如何保證緩存和數據庫的一致性?
很多小伙伴在面試的時候,應該都遇到過類似的問題,如何確保緩存和數據庫的一致性?
如果你對這個問題有過研究,應該可以發現這個問題其實很好回答,如果第一次聽到或者第一次遇到這個問題,估計會有點懵,今天我們來聊聊這個話題。
1. 問題分析
首先我們來看看為什么會有這個問題!
我們在日常開發中,為了提高數據響應速度,可能會將一些熱點數據保存在緩存中,這樣就不用每次都去數據庫中查詢了,可以有效提高服務端的響應速度,那么目前我們最常使用的緩存就是 Redis 了。
用 Redis 做緩存,并不是一說緩存就是 Redis,還是要結合業務的具體情況,我們可以根據不同業務對數據要求的實時性不同,將數據分為三級,以電商項目為例:
- 第 1 級:訂單數據和支付流水數據:這兩塊數據對實時性和精確性要求很高,所以一般是不需要添加緩存的,直接操作數據庫即可。
- 第 2 級:用戶相關數據:這些數據和用戶相關,具有讀多寫少的特征,所以我們使用 redis 進行緩存。
- 第 3 級:支付配置信息:這些數據和用戶無關,具有數據量小,頻繁讀,幾乎不修改的特征,所以我們使用本地內存進行緩存。
選中合適的數據存入 Redis 之后,接下來,每當要讀取數據的時候,就先去 Redis 中看看有沒有,如果有就直接返回;如果沒有,則去數據庫中讀取,并且將從數據庫中讀取到的數據緩存到 Redis 中,大致上就是這樣一個流程,讀取數據的這個流程實際上是比較清晰也比較簡單的,沒啥好說的。
然而,當數據存入緩存之后,如果需要更新的話,往往會來帶另外的問題:
- 當有數據需要更新的時候,先更新緩存還是先更新數據庫?如何確保更新緩存和更新數據庫這兩個操作的原子性?
- 更新緩存的時候該怎么更新?修改還是刪除?
怎么辦?正常來說,我們有四種方案:
- 先更新緩存,再更新數據庫。
- 先更新數據庫,再更新緩存。
- 先淘汰緩存,再更新數據庫。
- 先更新數據庫,再淘汰緩存。
到底使用哪種?
在回答這個問題之前,我們不妨先來看看三個經典的緩存模式:
- Cache-Aside
- Read-Through/Write through
- Write Behind
2. Cache-Aside
Cache-Aside,中文也叫旁路緩存模式,如果我們能夠在項目中采用 Cache-Aside,那么就能夠盡可能的解決緩存與數據庫數據不一致的問題,注意是盡可能的解決,并無法做到絕對解決。
Cache-Aside 又分為讀緩存和寫緩存兩種情況,我們分別來看。
2.1 讀緩存
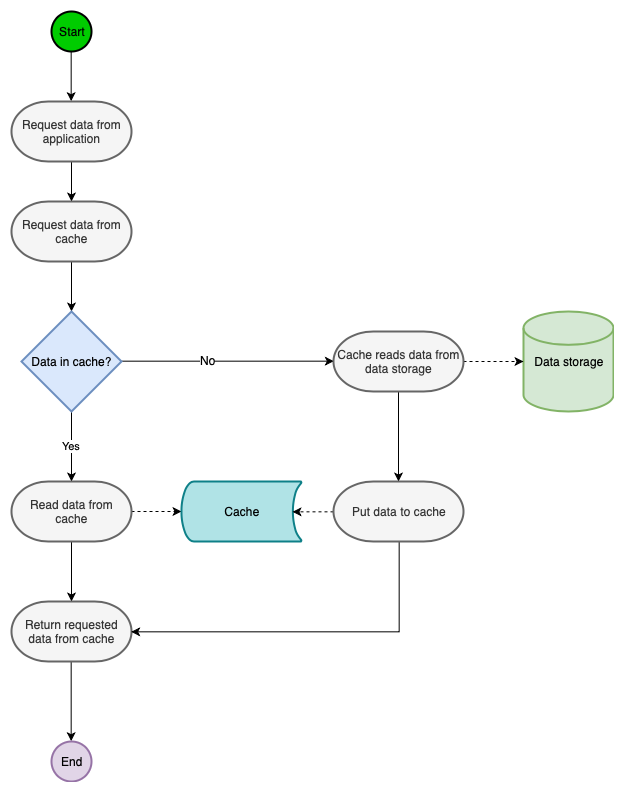
先來看一張流程圖:
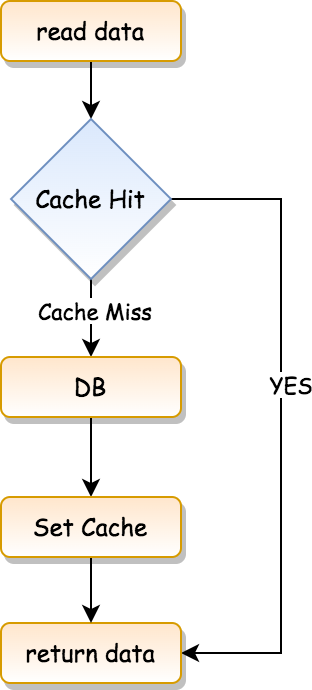
它的流程是這樣:
- 讀取數據。
- 檢查緩存中是否有需要的數據,如果命中緩存(Cache Hit),則直接返回數據。
- 如果沒有命中緩存,即 Cache Miss,那么就先去訪問數據庫。
- 將從數據庫中讀取到的數據設置到緩存中。
- 返回數據。
這是 Cache-Aside 的讀緩存流程。
其實對于讀緩存的流程而言,大家一般都沒什么異議,有異議的主要是寫流程,我們繼續來看。
2.2 寫緩存
先來看一張流程圖:
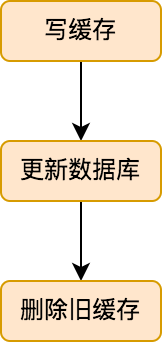
這個寫緩存的流程就比較簡單,先更新數據庫中的數據,然后刪除舊的緩存即可。
流程雖然簡單,但是卻引伸出來兩個問題:
- 為什么是刪除舊緩存而不是更新舊緩存?
- 為什么不先刪除舊的緩存,然后再更新數據庫?
我們來分別回答這兩個問題。
為什么是刪除舊緩存而不是更新舊緩存?
- 更新緩存,說著容易做起來并不容易。很多時候我們更新緩存并不是簡簡單單更新一個 Bean。很多時候,我們緩存的都是一些復雜操作或者計算(例如大量聯表操作、一些分組計算)的結果,如果不加緩存,不但無法滿足高并發量,同時也會給 MySQL 數據庫帶來巨大的負擔。那么對于這樣的緩存,更新起來實際上并不容易,此時選擇刪除緩存效果會更好一些。
- 對于一些寫頻繁的應用,如果按照更新緩存->更新數據庫的模式來,比較浪費性能,因為首先寫緩存很麻煩,其次每次都要寫緩存,但是可能寫了十次,只讀了一次,讀的時候讀到的緩存數據是第十次的,前面九次寫緩存都是無效的,對于這種情況不如采取先寫數據庫再刪除緩存的策略。
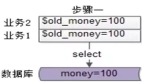
- 在多線程環境下,這樣的更新策略還有可能會導致數據邏輯錯誤,來看如下一張流程圖:
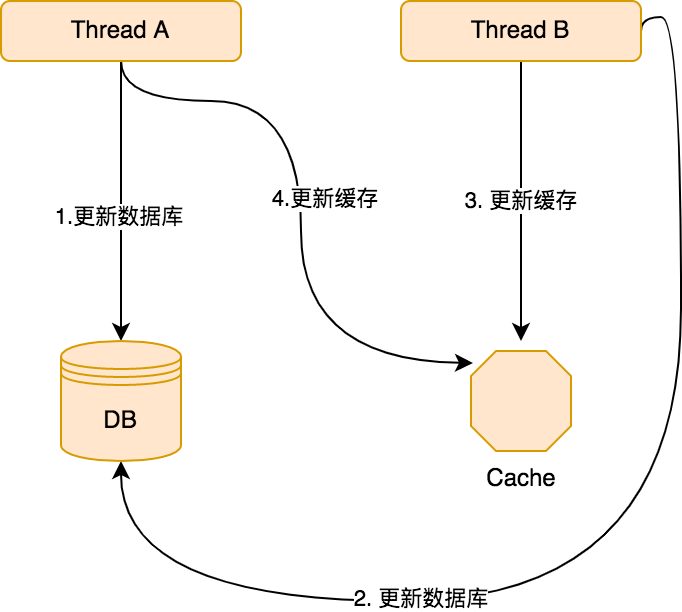
可以看到,有兩個并發的線程 A 和 B:
- 首先 A 線程更新了數據庫。
- 接下來 B 線程更新了數據庫。
- 由于網絡等原因,B 線程先更新了緩存。
- A 線程更新了緩存。
那么此時,緩存中保存的數據就是不正確的,而如果采用了刪除緩存的方式,就不會發生這種問題了。
為什么不先刪除舊的緩存,然后再更新數據庫?
這個也是考慮到并發請求,假設我們先刪除舊的緩存,然后再更新數據庫,那么就有可能出現如下這種情況:
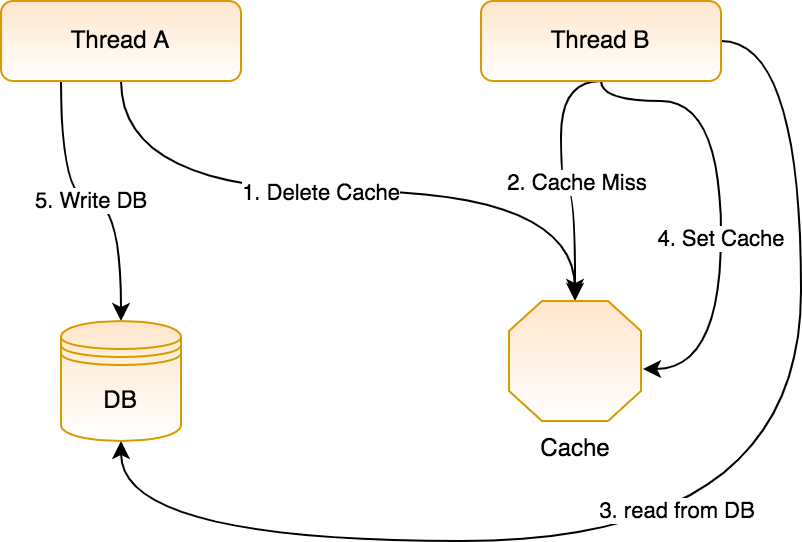
這個操作是這樣的,有兩個線程,A 和 B,其中 A 寫數據,B 讀數據,具體流程如下:
- A 線程首先刪除緩存。
- B 線程讀取緩存,發現緩存中沒有數據。
- B 線程讀取數據庫。
- B 線程將從數據庫中讀取到的數據寫入緩存。
- A 線程更新數據庫。
一套操作下來,我們發現數據庫和緩存中的數據不一致了!所以,在 Cache-Aside 中是先更新數據庫,再刪除緩存。
2.3 延遲雙刪
其實無論是先更新數據庫再刪除緩存,還是先刪除緩存再更新數據庫,在并發環境下都有可能存在問題:
假設有 A、B 兩個并發請求:
- 先更新數據庫再刪除緩存:當請求 A 更新數據庫之后,還未來得及進行緩存清除,此時請求 B 查詢到并使用了 Cache 中的舊數據。
- 先刪除緩存再更新數據庫:當請求 A 執行清除緩存后,還未進行數據庫更新,此時請求 B 進行查詢,查到了舊數據并寫入了 Cache。
當然我們前面已經分析過了,盡量先操作數據庫再操作緩存,但是即使這樣也還是有可能存在問題,解決問題的辦法就是延遲雙刪。
延遲雙刪是這樣:先執行緩存清除操作,再執行數據庫更新操作,延遲 N 秒之后再執行一次緩存清除操作,這樣就不用擔心緩存中的數據和數據庫中的數據不一致了。
那么這個延遲 N 秒,N 是多大比較合適呢?一般來說,N 要大于一次寫操作的時間,如果延遲時間小于寫入緩存的時間,會導致請求 A 已經延遲清除了緩存,但是此時請求 B 緩存還未寫入,具體是多少,就要結合自己的業務來統計這個數值了。
2.4 如何確保原子性
但是更新數據庫和刪除緩存畢竟不是一個原子操作,要是數據庫更新完畢后,刪除緩存失敗了咋辦?
對于這種情況,一種常見的解決方案就是使用消息中間件來實現刪除的重試。大家知道,MQ 一般都自帶消費失敗重試的機制,當我們要刪除緩存的時候,就往 MQ 中扔一條消息,緩存服務讀取該消息并嘗試刪除緩存,刪除失敗了就會自動重試。如果小伙伴們還不懂 RabbitMQ 的使用,可以在公眾號江南一點雨后臺回復 rabbitmq,有免費的視頻+文檔。
3. Read-Through/Write-Through
這種緩存操作模式,松哥印象最深的是在 Oracle Coherence 中有應用,不知道小伙伴們有沒有用過 Oracle Coherence,這是一個內存數據網格,通過這個,應用開發人員和管理人員可快速訪問鍵值數據,Coherence 可提供集群式低延遲數據存儲、多語言網格計算和異步事件流處理,從而為客戶企業應用賦予超高水平的可擴展性和性能。
Oracle Coherence 我們就不討論了,我們就來說說 Read-Through。
3.1 Read-Through
這里為了省事,我就不自己畫圖了,網上找了一張圖片,如下:
乍一看,很多人感覺這和 Cache-Aside 一樣呀,沒啥區別!是的,單看流程是不太容易看到區別。
Read-Through 是一種類似于 Cache-Aside 的緩存方法,區別在于,在 Cache-Aside 中,由應用程序決定去讀取緩存還是讀取數據庫,這樣就會導致應用程序中出現了很多業務無關的代碼;而在 Read-Through 中,相當于多出來了一個中間層 Cache Middleware,由它去讀取緩存或者數據庫,應用層的代碼得到了簡化,松哥之前寫過 Spring Cache 的用法,大家回憶下 Spring Cache 中的 @Cacheable 注解,感覺像不像 Read-Through?
我畫一個簡單的流程圖大家來看下:
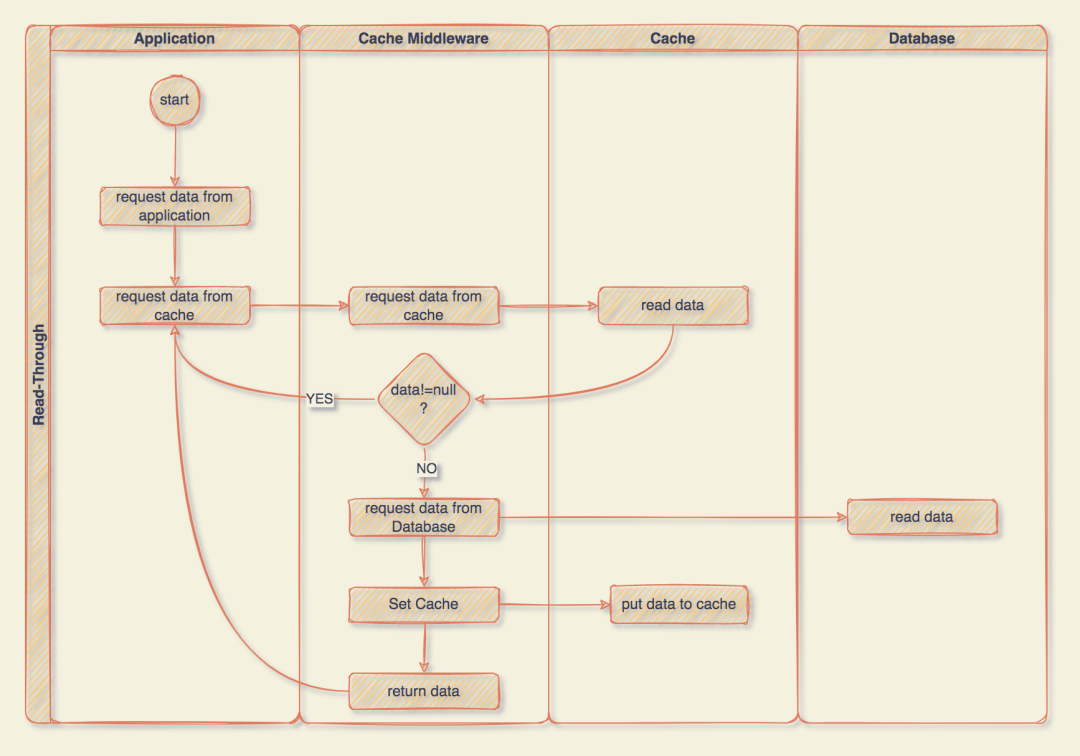
可以看到,和 Cache-Aside 相比,其實就相當于是多了一個 Cache Middleware,這樣我們在應用程序中就只需要正常的讀寫數據就行了,并不用管底層的具體邏輯,相當于把緩存相關的代碼從應用程序中剝離出來了,應用程序只需要專注于業務就行了。
3.2 Write-Through
Write-Through 其實也是差不多,所有的操作都交給 Cache Middleware 來完成,應用程序中就是一句簡單的更新就行了,我們來看看流程:
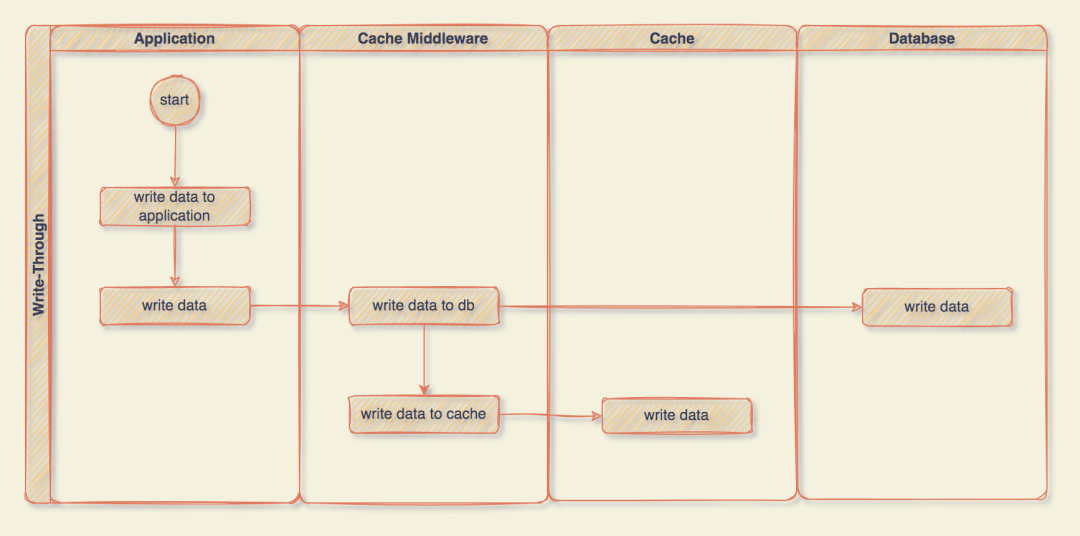
在 Write-Through 策略中,所有的寫操作都經過 Cache Middleware,每次寫入時,Cache Middleware 會將數據存儲在 DB 和 Cache 中,這兩個操作發生在一個事務中,因此,只有兩個都寫入成功,一切才會成功。
這種寫數據的優勢在于,應用程序只與 Cache Middleware 對話,所以它的代碼更加干凈和簡單。
4. Write Behind
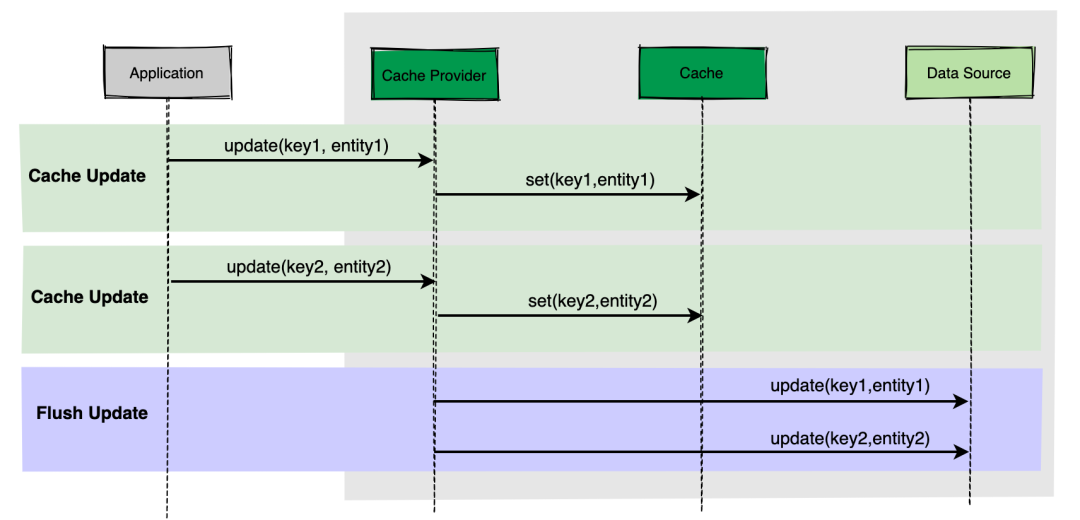
Write-Behind 緩存策略類似于 Write-Through 緩存,應用程序僅與 Cache Middleware 通信,Cache Middleware 會預留一個與應用程序通信的接口。
Write-Behind 與 Write-Through 最大的區別在于,前者是數據首先寫入緩存,一段時間后(或通過其他觸發器)再將數據寫入 Database,并且這里涉及到的寫入是一個異步操作。這種方式下,Cache 和 DB 數據的一致性不強,對一致性要求高的系統要謹慎使用,如果有人在數據尚未寫入數據源的情況下直接從數據源獲取數據,則可能導致獲取過期數據,不過對于頻繁寫入的場景,這個其實非常適用。
將數據寫入 DB 可以通過多種方式完成:
- 一種是收集所有寫入操作,然后在某個時間點(例如,當 DB 負載較低時)對數據源進行批量寫入。
- 另一種方法是將寫入合并成更小的批次,例如每次收集五個寫入操作,然后對數據源進行批量寫入。
這個流程圖就不想畫了,在網上找了一張,小伙伴們參考下:
參考資料:
https://www.jianshu.com/p/a8eb1412471f
https://catsincode.com/caching-strategy/