RocketMQ-Streams架構設計淺析
精選作者 |倪澤
RocketMQ-Streams 是一款輕量級流處理引擎,應用以SDK 的形式嵌入并啟動,即可進行流處理計算,不依賴于其他組件,最低1核1G可部署,在資源敏感場景具有很大優勢。同時它支持 UTF/UTAF/UTDF 多種計算類型。目前已經廣泛運用于安全,風控,邊緣計算等場景。
本期將帶領大家從源碼的角度,解析RocketMQ-Streams的構建,數據流轉過程。也會討論RocketMQ-Streams是如何實現故障恢復和擴縮容的。
一、使用示例
代碼示例:
public class RocketMQWindowExample {
public static void main(String[] args) {
DataStreamSource source = StreamBuilder.dataStream("namespace", "pipeline");
source.fromRocketmq(
"topicName",
"groupName",
false,
"namesrvAddr")
.map(message -> JSONObject.parseObject((String) message))
.window(TumblingWindow.of(Time.seconds(10)))
.groupBy("groupByKey")
.sum("字段名", "輸出別名")
.count("total")
.waterMark(5)
.setLocalStorageOnly(true)
.toDataSteam()
.toPrint(1)
.start();
}
}pom文件依賴:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-streams-clients</artifactId>
<version>1.0.1-preview</version>
</dependency>
上述代碼是一個簡單的使用例子,它主要的功能是從RocketMQ中指定topic讀取數據,經過轉化成JSON格式,以groupByKey字段值分組、10秒一個窗口,對OutFlow字段值進行累加,結果輸出到total字段,并打印到控制臺上。上述計算中還允許輸入亂序5秒,即窗口時間到達后不會馬上觸發,而是會等待5s,如果這個段時間內,有窗口數據到達依然有效。上述setLocalStorageOnly為true表示不對狀態進行遠程存儲,僅使用RocksDB做本地存儲。目前1.0.1的RocketMQ-Streams版本依然使用Mysql作為遠程狀態存儲,下一版本將使用RocketMQ作為遠程狀態存儲。
二、RocketMQ總體架構圖
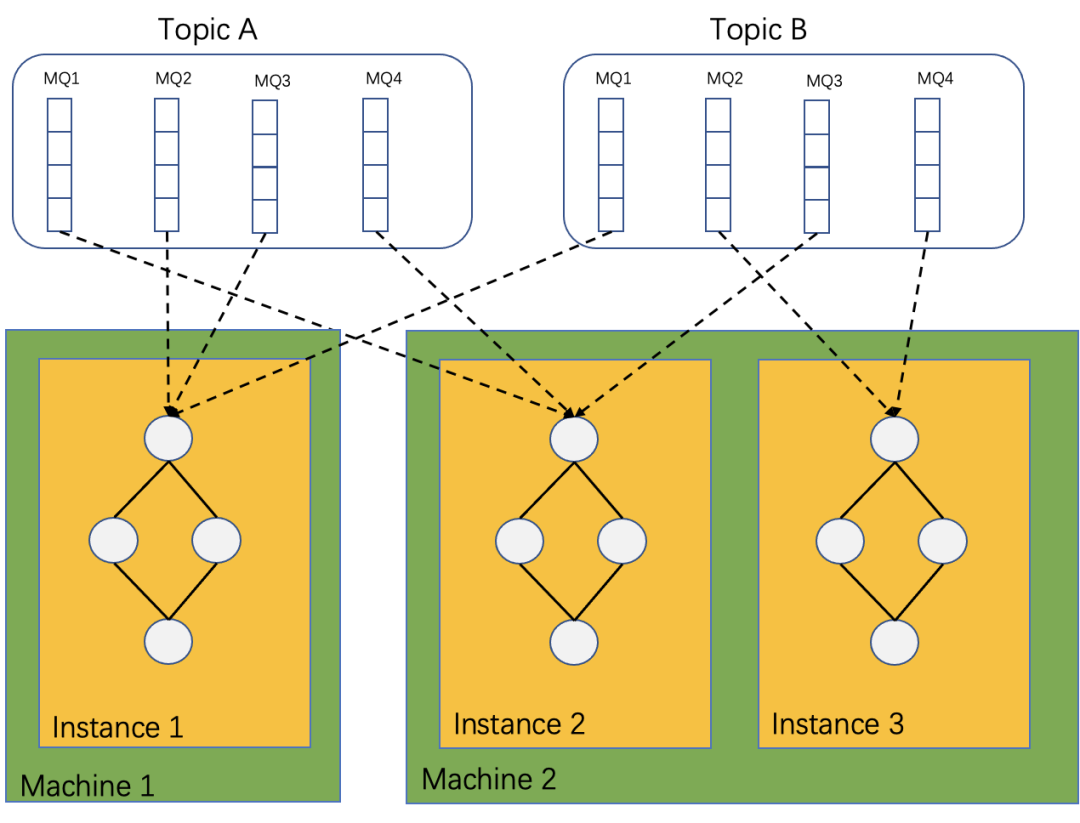
RocketMQ-Streams 作為輕量流處理引擎,本質上是作為RocketMQ 的客戶端消費數據,一個流處理實例可以處理多個隊列,而一個隊列只能被一個實例消費。若干RocketMQ-Streams 實例組成消費者組共同消費數據,通過擴容實例達到增加處理能力的消費,減少實例則會發生rebalance,消費的隊列自動重平衡到其他消費實例上。從上述圖中,我們還可以看出計算實例間不需要直接交換任何數據,可各自獨立完成所有計算處理。這種架構簡化了RocketMQ-Streams 本身的設計,同時也可非常方便的進行實例擴縮容。
處理拓撲
處理器拓撲為應用定義了流處理過程的計算邏輯,它由一系列的處理器節點和數據流向組成。例如,在開頭的代碼示例中,整個處理拓撲由source、map、groupBy、sum、count、print等處理節點組成。有兩種特殊的處理節點:
- source節點
他沒有任何上游節點,從外部讀入數據到RocketMQ-Streams,并交由下游處理。
- sink節點
他沒有任何下游節點,他將處理后的數據寫出到外部。
處理拓撲僅僅是流處理代碼的邏輯抽象,在流計算啟動時將會被實例化。為了設計簡單,目前一個流處理實例中僅有一張計算拓撲。
在所有流處理算子之中,有兩種特別的算子,一種是涉及數據分組的算子groupBy,另一種是有狀態計算例如count等。這兩種算子會影響整個計算拓撲的構建,下面將具體分析RocketMQ-Streams是如何處理他們的。
groupBy
分組算子groupBy特殊是因為經過groupBy操作,后續算子期望對相同key的數據進行操作,例如經過groupBy("年級")之后再進行sum就是對按照年級分組求和,這就要求需要將具有相同“年級”的數據重新路由到一個流計算實例上處理,如果不這樣做,每個實例上得出的結果都將是不完整的,整體輸出結果也將是錯誤的。
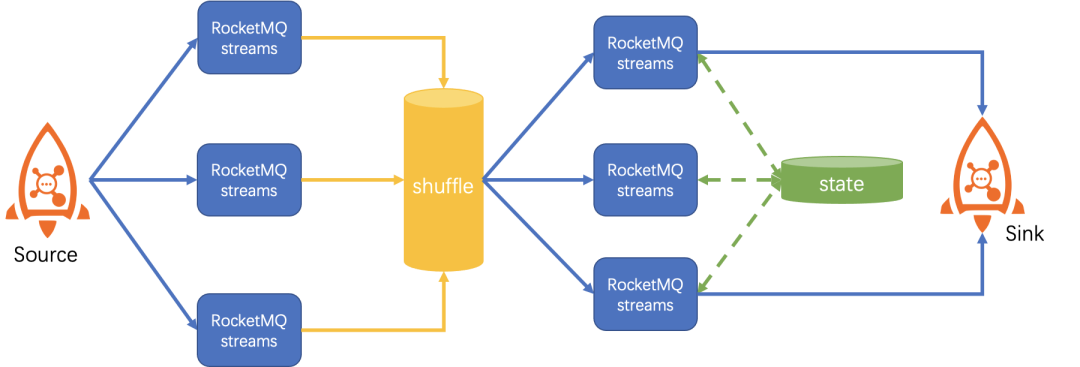
RocketMQ-Streams 采用 shuffle topic 這種方式來處理。具體說來,計算實例將groupBy數據重新發回RocketMQ的一個topic,并且在發回過程中按照key的hash值來選擇目標隊列,再從這個topic讀取數據進行后續流處理。按照key hash后相同的key一定在一個隊列里面,而一個隊列只會被一個流處理實例消費,這樣就達到相同key被路由到一個實例上處理的效果。
有狀態算子
有狀態算子與無狀態算子相對。如果計算結果只與當前輸入有關,和上一次輸入無關就是無狀態算子,例如filter、map、foreach結果只與當前輸入有關系。還有一種算子的輸出結果不僅與當前算子有關系還與上一次輸入有關,例如sum,需要對一段時間內輸入進行求和,他就是有狀態算子。
RocketMQ-Streams利用RocksDB作為本地存儲,Mysql作為遠程存儲來保存狀態數據。他具體做法是:
當發現消息來自新的隊列時,檢查是否需要加載狀態,如果需要異步加載狀態到RocksDB。
數據到達有狀態算子時,如果加載完成使用RocksDB中狀態進行計算,如果沒有,使用Mysql中狀態計算。
計算完成后,將狀態數據保存到RocksDB和Mysql中。
窗口觸發后,從RocksDB中查詢出狀態數據,并將結果向下游算子傳遞。
整體數據流向圖如下:
三、擴縮容與故障恢復
擴縮容和故障恢復是一個硬幣的兩面,即同一個事物的兩種表達,計算集群如果能正確擴縮容就等于具備故障恢復的能力,反之亦然。通過前面介紹我們知道,RocketMQ-Streams具有非常良好的擴縮容性能,擴容時只需要新部署一個流計算實例即可,縮容時停止計算實例即可。對于無狀態的計算來說比較簡單,擴容后,數據計算不需要之前的狀態。有狀態計算的擴縮容涉及到狀態的遷移。有狀態的擴縮容可由下圖表示:
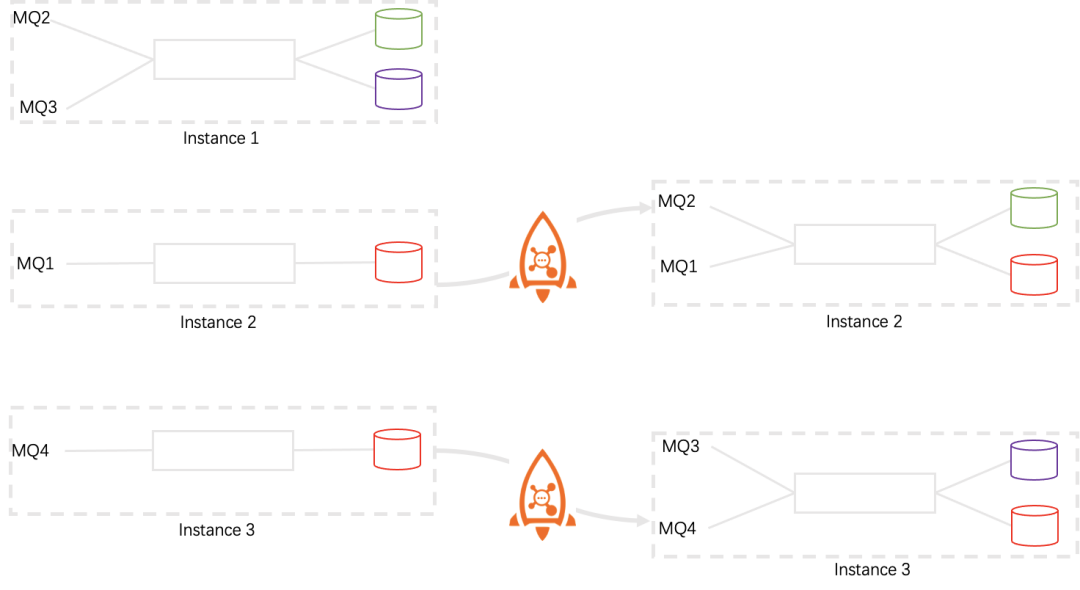
當計算實例從3個縮容到2個,借助于RocketMQ的rebalance,MQ會在計算實例之間重新分配。
Instance1上消費的MQ2和MQ3被分配到Instance2和Instance3上,這兩個MQ的狀態數據也需要遷移到Instance2和Instance3上,這也暗示,狀態數據是根據源數據分片保存的;擴容則是剛好相反的過程。
具體實現上,RocketMQ-Streams采用系統消息來觸發狀態的加載和持久化。
系統消息類別:
//新增消費隊列
NewSplitMessage
//不在消費某個隊列
RemoveSplitMessage
//客戶端持久化消費位點到MQ
CheckPointMessage
當發現消息來自一個新的RocketMQ隊列(MessageQueue),RocketMQ-Streams之前沒有處理過來自該隊列的消息,會先于數據前發送NewSplitMessage消息,通過處理拓撲下游算子傳遞,當有狀態算子收到該消息時會將新增隊列對應的狀態加載到本地內存RocksDB中,當數據真正到達時,就根據這個狀態繼續計算。
當因為計算實例增加或者RocketMQ集群變動,rebalance后,計算實例不再消費某個隊列(MessageQueue)時,會發出RemoveSplitMessage消息,有狀態算子刪除本地RocksDB中的狀態。
CheckPointMessage是一種特別的系統消息,他的作用與實現exactly-once有關。我們在擴縮容過程中需要做到exactly-once,才能保證擴縮容或故障恢復對計算結果沒有影響。RocketMQ-streams向broker提交消費offset前會產生CheckPointMessage消息,向下游拓撲傳遞,他將保證即將提交消費位點的所有消息都已經被sink處理掉。
開源地址:
RocketMQ-Streams 倉庫地址:
https://github.com/apache/rocketmq-streams
RocketMQ 倉庫地址:
https://github.com/apache/rocketmq
作者:倪澤,RocketMQ 資深貢獻者, RocketMQ-Streams 維護者之一,阿里云技術專家。