矩陣分解就能擊敗深度學習!MIT發布時序數據庫tspDB:用SQL做機器學習
人類從歷史中學到的唯一教訓,就是人類無法從歷史中學到任何教訓。
「但機器可以學到。」 ——沃茲基碩德

無論是預測明天的天氣,預測未來的股票價格,識別合適的機會,還是估計病人的患病風險,都可能對時間序列數據進行解釋,數據的收集則是在一段時間內對觀察結果的記錄。
但使用時間序列數據進行預測通常需要多個數據預處理的步驟,并且需要用到復雜的機器學習算法,對于非專業人士來說,了解這些算法的原理和使用場景是一件不容易的事。

最近,來自麻省理工學院的研究人員開發了一個強大的系統工具tspDB方便用戶處理時序數據,能夠在現有的時間序列數據庫之上直接整合預測功能。系統包含了很多復雜的模型,即使非專家也能在幾秒鐘之內完成一次預測。在執行預測未來值和填補缺失數據點這兩項任務時,新系統比最先進的深度學習方法更準確、更高效。論文發表在ACM SIGMETRICS會議上。

論文地址:http://proceedings.mlr.press/v133/agarwal21a/agarwal21a.pdf
tspDB性能提升的主要原因是它采用了一種新穎的時間序列預測算法,這種算法在對多變量時間序列數據進行預測時特別有效。多變量指的是數據有一個以上的時間依賴變量,例如在天氣數據庫中,溫度、露點和云量的當前值都依賴于其各自的過去值。
該算法還可以估計多變量時間序列的波動性,以便為用戶提供模型預測準確度的confidence
作者表示,即使時間序列數據變得越來越復雜,這個算法也能有效地捕捉到時間序列結構。
文章作者Anish Agarwal博士畢業于麻省理工,主要研究興趣包括因果推理和機器學習的相互作用;高維統計;數據經濟學。2022年1月作為博士后研究員加入加州大學伯克利分校的西蒙斯研究所。

處理時序數據的正確姿勢
目前機器學習工作流程的一個主要瓶頸是數據處理太耗費時間,并且中間流程也很容易出錯。開發人員需要從數據存儲或數據庫中先獲取數據,然后應用機器學習算法進行訓練和預測,這個過程中需要大量的人工來做數據處理。

現在這種情況越來越嚴重了,因為機器學習需要吞進去的數據越來越多,更不好管理了。尤其是在實時預測領域,特別是在各種時間序列的應用場景中,比如金融和實時控制更需要好好管理數據。
要是能直接在數據庫上進行預測,不就省了取數據這步了嗎?
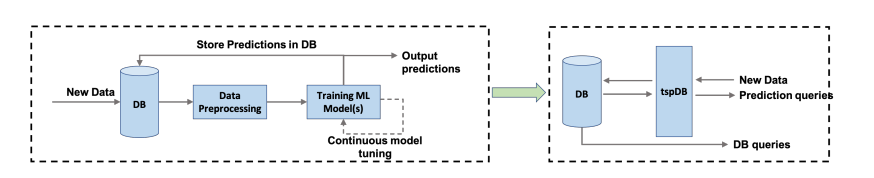
但這種在數據庫上的預測集成系統不僅需要提供一個直觀的預測查詢界面,防止重復數據工程;同時還需要確保準確率可以達到sota,支持增量的模型更新,比較短的訓練時間和較低的預測延遲。
tspDB就是直接與PostgreSQL集成,內部原生支持多個機器學習算法,例如廣義線性模型、隨機森林、神經網絡,在訓練模型的時候也可以在數據庫里調節超參數。
和其他數據庫不同的是,tspDB的一個重要出發點「終端用戶」如何與系統對接來獲得預測值。
為了讓機器學習的接口更通用,tspDB采用了一種不同的方法:把機器學習模型從用戶中抽象出來,爭取只用一個單一的界面來響應標準的數據庫查詢和預測查詢,也就是都用SQL來查詢。
在tspDB中,預測性查詢的形式與標準SELECT查詢相同。預測性查詢和普通查詢的區別就是一個是模型預測,另一個是檢索。
比如數據庫里只有100條數據,想預測第101天的值,就用PREDICT關鍵詞,WHERE day = 101即可;而WHERE day = 10時就會被解析第10天的股票價格的估算值/去噪值,所以PREDICT還可以用于預測缺失值。

為了實現PREDICT查詢,用戶需要利用現有的多元時間序列數據先建立一個預測模型。CREATE的關鍵字可以用于在tspDB中建立預測模型,輸入的特征也可以是多個數據列。
tspDB與PostgreSQL DB相比,在標準的多變量時間序列數據集上,在tspDB中創建預測模型所需的時間是PostgreSQL批量插入時間的0.58倍-1.52倍。在查詢延遲方面,在tspDB中回答一個PREDICT查詢所需的時間是回答一個標準的PREDICT查詢的1.6到2.8倍,與回答一個標準的SELECT查詢相比,要高出1.6到2.8倍。
從絕對值來看,這相當于回答一個SELECT查詢需要1.32毫秒,而回答一個預測查詢需要3.5毫秒,回答一個歸納/預測查詢需要3.36/3.45毫秒。
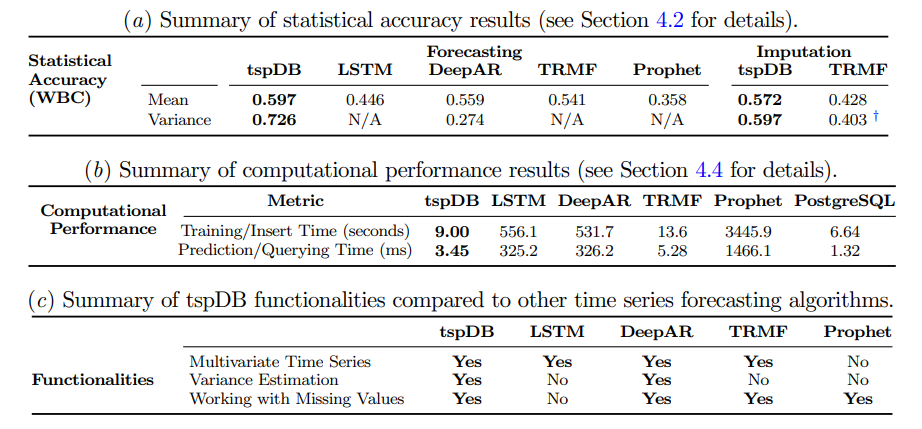
也就是說,tspDB的計算性能接近于從PostgreSQL插入和讀取數據所需的時間,基本上可以用于實時預測系統。
因為tspDB還只是一個概念的驗證,相當于是PostgreSQL的一個擴展,用戶可以對單列或多列創建預測查詢;在時間序列關系上創建單列或多列的預測查詢,并提供預測區間的估計值。最重要的是,代碼是開源的。
代碼鏈接:https://github.com/AbdullahO/tspdb
文章中還提出一個基于時間序列算法的矩陣分解算法,通過將多變量時序數據Page Matrix堆疊起來后,使用SVD算法進行分解,在子矩陣中移除最后一列作為預測值,使用線性回歸對目標值進行預測即可。
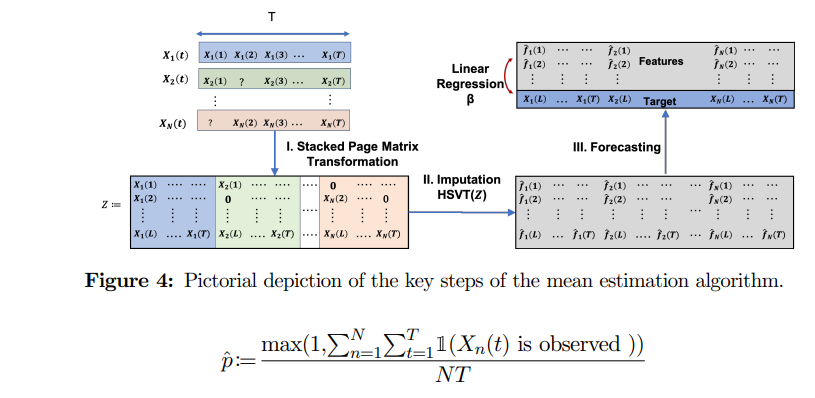
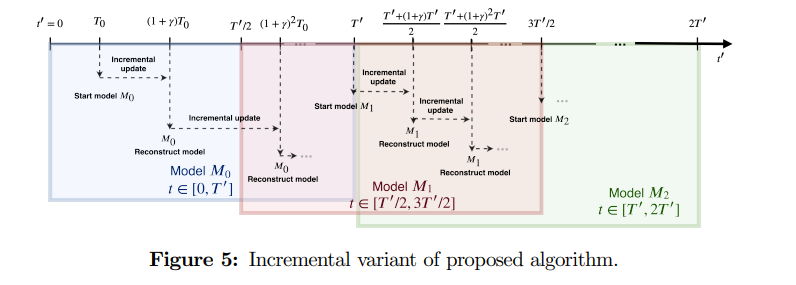
對于不斷涌入的時序數據,算法還支持增量的模型更新。
為了對算法進行性能測試,研究人員選擇了三個現實世界的數據集,包括電力(Electricity)、交通(Traffic)和金融(Finance)。評價指標采用Normalized Root Mean Square Error (NRMSE)作為準確率。為了量化不同方法的統計準確性,研究人員還加了一個標準Borda Count (WBC)的變體作為評價指標,0.5的值意味著算法的表現和其他算法相比就是平均水平,1代表相比其他算法具有絕對優勢,0代表絕對劣勢。
將tspDB的預測性能與學術界和工業界最流行的時間序列庫如LSTM、DeepAR、TRMF和Prophet進行比較后可以發現,tspDB的表現與深度學習算法(DeepAR和LSTM)相比都相差不多,并且超過了TRMF和Prophet。
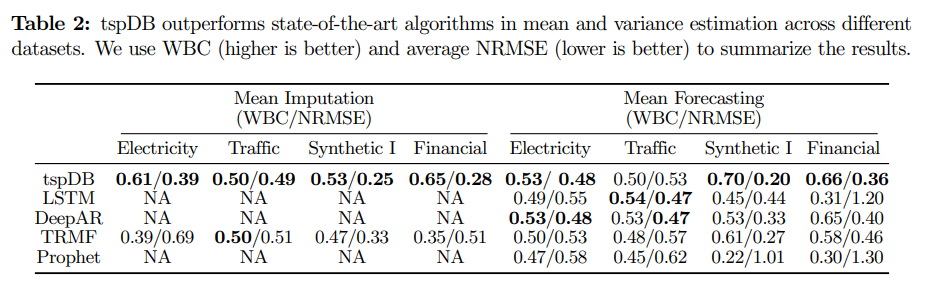
當改變缺失值的比例和添加的噪聲時,tspDB在50%的實驗中是表現最好的方法,在80%的實驗中至少是表現第二好的。使用WBC和NRMSE這兩個指標,tspDB在電力、金融數據集中的表現優于其他所有算法,而在交通數據集中的表現可與DeepAR和LSTM匹敵。
在方差估計上,因為我們無法獲得現實世界數據中真正的基礎時變方差,所以研究人員將分析限制在合成數據上。合成數據集II包括了九組多變量時間序列,每組都有不同的時間序列動態加性組合和不同的噪聲觀測模型(高斯、泊松、伯努利噪聲)。
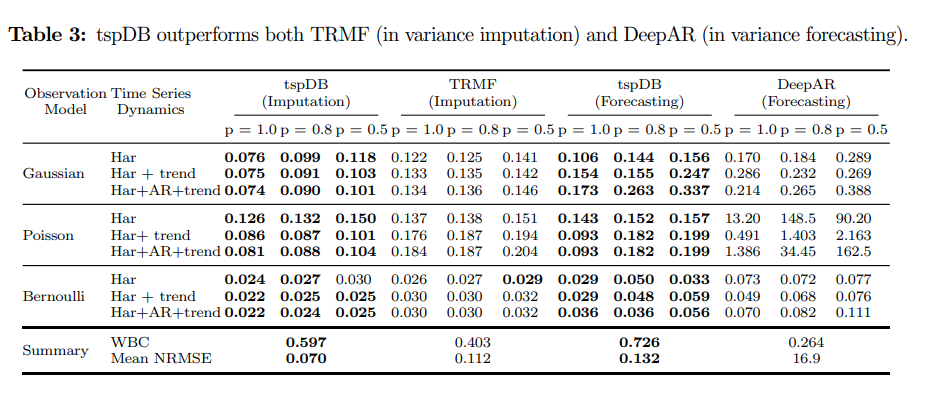
實驗結果中可以發現,除了一個實驗之外,tspDB在所有的實驗中都比TRMF和DeepAR(用于預測)具有更高的性能(>98%)。
總的來說,這些實驗顯示了tspDB的穩健性,即在估計時間序列的均值和方差時,可以消除部分噪聲的影響。