JDK9為何要將String的底層實現(xiàn)由char[]改成了byte[]?

如果你不是 Java8 的釘子戶,你應(yīng)該早就發(fā)現(xiàn)了:String 類的源碼已經(jīng)由 char[] 優(yōu)化為了 byte[] 來存儲字符串內(nèi)容,為什么要這樣做呢?
開門見山地說,從 char[] 到 byte[],最主要的目的是為了節(jié)省字符串占用的內(nèi)存 。內(nèi)存占用減少帶來的另外一個好處,就是 GC 次數(shù)也會減少。
一、為什么要優(yōu)化 String 節(jié)省內(nèi)存空間
我們使用 jmap -histo:live pid | head -n 10 命令就可以查看到堆內(nèi)對象示例的統(tǒng)計信息、查看 ClassLoader 的信息以及 finalizer 隊列。
以我正在運行著的編程喵喵項目實例(基于 Java 8)來說,結(jié)果是這樣的。
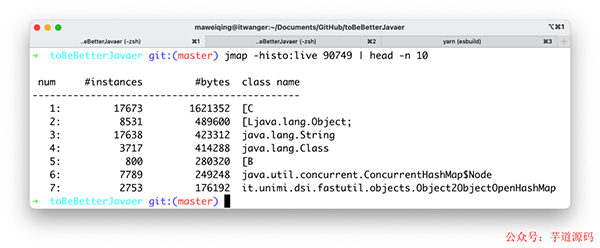
其中 String 對象有 17638 個,占用了 423312 個字節(jié)的內(nèi)存,排在第三位。
由于 Java 8 的 String 內(nèi)部實現(xiàn)仍然是 char[],所以我們可以看到內(nèi)存占用排在第 1 位的就是 char 數(shù)組。
char[] 對象有 17673 個,占用了 1621352 個字節(jié)的內(nèi)存,排在第一位。
那也就是說優(yōu)化 String 節(jié)省內(nèi)存空間是非常有必要的,如果是去優(yōu)化一個使用頻率沒有 String 這么高的類庫,就顯得非常的雞肋。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能。
項目地址:??https://github.com/YunaiV/ruoyi-vue-pro??
二、byte[] 為什么就能節(jié)省內(nèi)存空間呢?
眾所周知,char 類型的數(shù)據(jù)在 JVM 中是占用兩個字節(jié)的,并且使用的是 UTF-8 編碼,其值范圍在 '\u0000'(0)和 '\uffff'(65,535)(包含)之間。
也就是說,使用 char[] 來表示 String 就導致了即使 String 中的字符只用一個字節(jié)就能表示,也得占用兩個字節(jié)。
而實際開發(fā)中,單字節(jié)的字符使用頻率仍然要高于雙字節(jié)的。
當然了,僅僅將 char[] 優(yōu)化為 byte[] 是不夠的,還要配合 Latin-1 的編碼方式,該編碼方式是用單個字節(jié)來表示字符的,這樣就比 UTF-8 編碼節(jié)省了更多的空間。
換句話說,對于:
String name = "jack";
這樣的,使用 Latin-1 編碼,占用 4 個字節(jié)就夠了。
但對于:
String name = "小二";
這種,木的辦法,只能使用 UTF16 來編碼。
針對 JDK 9 的 String 源碼里,為了區(qū)別編碼方式,追加了一個 coder 字段來區(qū)分。
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;
Java 會根據(jù)字符串的內(nèi)容自動設(shè)置為相應(yīng)的編碼,要么 Latin-1 要么 UTF16。
也就是說,從 char[] 到 byte[],中文是兩個字節(jié),純英文是一個字節(jié),在此之前呢,中文是兩個字節(jié),英文也是兩個字節(jié) 。
基于微服務(wù)的思想,構(gòu)建在 B2C 電商場景下的項目實戰(zhàn)。核心技術(shù)棧,是 Spring Boot + Dubbo 。未來,會重構(gòu)成 Spring Cloud Alibaba 。
項目地址:??https://github.com/YunaiV/onemall??
三、為什么用UTF-16而不用UTF-8呢?
在 UTF-8 中,0-127 號的字符用 1 個字節(jié)來表示,使用和 ASCII 相同的編碼。只有 128 號及以上的字符才用 2 個、3 個或者 4 個字節(jié)來表示。
- 如果只有一個字節(jié),那么最高的比特位為 0;
- 如果有多個字節(jié),那么第一個字節(jié)從最高位開始,連續(xù)有幾個比特位的值為 1,就使用幾個字節(jié)編碼,剩下的字節(jié)均以 10 開頭。
具體的表現(xiàn)形式為:
- 0xxxxxxx:一個字節(jié);
- 110xxxxx 10xxxxxx:兩個字節(jié)編碼形式(開始兩個 1);- 1110xxxx 10xxxxxx 10xxxxxx:三字節(jié)編碼形式(開始三個 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字節(jié)編碼形式(開始四個 1)。
也就是說,UTF-8 是變長的,那對于 String 這種有隨機訪問方法的類來說,就很不方便。所謂的隨機訪問,就是charAt、subString這種方法,隨便指定一個數(shù)字,String要能給出結(jié)果。如果字符串中的每個字符占用的內(nèi)存是不定長的,那么進行隨機訪問的時候,就需要從頭開始數(shù)每個字符的長度,才能找到你想要的字符。
那有小伙伴可能會問,UTF-16也是變長的呢?一個字符還可能占用 4 個字節(jié)呢?
的確,UTF-16 使用 2 個或者 4 個字節(jié)來存儲字符。
- 對于 Unicode 編號范圍在 0 ~ FFFF 之間的字符,UTF-16 使用兩個字節(jié)存儲。
- 對于 Unicode 編號范圍在 10000 ~ 10FFFF 之間的字符,UTF-16 使用四個字節(jié)存儲,具體來說就是:將字符編號的所有比特位分成兩部分,較高的一些比特位用一個值介于 D800~DBFF 之間的雙字節(jié)存儲,較低的一些比特位(剩下的比特位)用一個值介于 DC00~DFFF 之間的雙字節(jié)存儲。
但是在 Java 中,一個字符(char)就是 2 個字節(jié),占 4 個字節(jié)的字符,在 Java 里也是用兩個 char 來存儲的,而String的各種操作,都是以Java的字符(char)為單位的,charAt是取得第幾個char,subString取的也是第幾個到第幾個char組成的子串,甚至length返回的都是char的個數(shù)。
所以UTF-16在Java的世界里,就可以視為一個定長的編碼。