













谷歌大牛Jeff Dean單一作者撰文:深度學習研究的黃金十年
自從計算機誕生之初,人類就夢想著能夠創造出會思考的機器。1956 年在達特茅斯學院組織的一個研討會上,約翰 · 麥卡錫提出人工智能這個概念,一群數學家和科學家聚集在一起尋找如何讓機器使用語言、形成抽象理解和概念、以解決現存的各種問題,當時研討會參與者樂觀地認為,在幾個月的時間里這些問題能取得真正的進展。
人工智能是由約翰麥卡錫于 1956 年在達特茅斯學院組織的一個研討會上創立的,一群數學家和科學家聚集在一起尋找如何讓機器使用語言、形成抽象和概念、解決現在保留的各種問題,當時研討會參與者樂觀地認為,幾個月的集中努力將在這些問題上取得真正的進展。

1956 年達特茅斯人工智能會議的參與者:馬文 · 明斯基、克勞德 · 香農 、雷 · 所羅門諾夫和其他科學家。攝自:Margaret Minsky
事實證明,預留幾個月的時間安排過于樂觀。在接下來的 50 年里,創建人工智能系統的各種方法開始流行,但后來又遭遇過時,包括基于邏輯的系統、基于規則的專家系統和神經網絡。
直到 2011 年左右,人工智能才開始進入發展關鍵階段,取得了巨大的進步,這得益于深度學習中神經網絡的復興,這些技術的進步有助于提高計算機看、聽和理解周圍世界的能力,使得人工智能在科學以及人類探索的其他領域取得巨大進步。這其中有哪些原因呢?
近日,谷歌大牛 Jeff Dean 發表了一篇文章《 A Golden Decade of Deep Learning: Computing Systems & Applications 》,文章探索了深度學習在這黃金十年里,計算系統以及應用進步的原因都有哪些?本文重點關注三個方面:促成這一進步的計算硬件和軟件系統;過去十年在機器學習領域一些令人興奮的應用示例;如何創建更強大的機器學習系統,以真正實現創建智能機器的目標。
Jeff Dean 的這篇文章發表在了美國文理學會會刊 D?dalus 的 AI 與社會(AI & Society)特刊上。

文章地址:https://www.amacad.org/sites/default/files/publication/downloads/Daedalus_Sp22_04_Dean.pdf
深度學習的黃金十年
人工智能硬件和軟件的進步
人工智能的硬件和軟件:深度學習通過組合不同的線性代數(例如矩陣乘法、向量點積以及類似操作)進行運算,但這種運算方式會受到限制,因此我們可以構建專用計算機或加速器芯片來進行處理,相比于通用 CPU,這種專業化的加速器芯片能帶來新的計算效率和設計選擇。
專為支持此類計算而定制的計算機或加速器芯片。相對于必須運行更廣泛種類的算法的通用 CPU,這種專業化實現了新的效率和設計選擇。
早在 2000 年代初期,就有少數研究者開始探索使用 GPU 來實現深度學習算法。之后到了 2004 年,計算機科學家 Kyoung-Su Oh 和 Keechul Jung 展示了使用 GPU 對神經網絡算法近 20 倍的速度提 sheng。2008 年,計算機科學家 Rajat Raina 及其同事演示了在某些非監督學習算法中,使用 GPU 與使用基于 CPU 的最佳實現相比,GPU 速度提升可達 72.6 倍。
隨著計算硬件的改進,深度學習開始在圖像識別、語音識別、語言理解等方面取得顯著進步。深度學習算法有兩個非常好的特性可以構建專門的硬件:首先,它們對精度的降低非常寬容;其次,深度學習的計算方式,其由密集矩陣或向量上的不同線性代數運算序列組成。
為了使深度學習和計算變得更容易,研究人員開發了開源軟件框架,如今,開源框架幫助大量的研究人員、工程師等推進深度學習研究,并將深度學習應用到更廣泛的領域。
早期的一些框架包括 Torch、Theano、DistBelief 、Caffe 等,還有谷歌在 2015 年開發、開源的 TensorFlow,它是一個允許表達機器學習計算的框架,并結合了 Theano 和 DistBelief 等早期框架的想法。到目前為止,TensorFlow 已被下載超過 5000 萬次,是世界上最受歡迎的開源軟件包之一。
TensorFlow 發布的一年后,PyTorch 于 2016 年發布,它使用 Python 可以輕松表達各種研究思想而受到研究人員的歡迎。JAX 于 2018 年發布,這是一個流行的面向 Python 的開源庫,結合了復雜的自動微分和底層 XLA 編譯器,TensorFlow 也使用它來有效地將機器學習計算映射到各種不同類型的硬件上。
TensorFlow 和 PyTorch 等開源機器學習庫和工具的重要性怎么強調都不為過,它們允許研究人員可以快速嘗試想法。隨著世界各地的研究人員和工程師更輕松地在彼此的工作基礎上進行構建,整個領域的進展速度將加快!
研究成果激增
研究不斷取得進步、面向 ML 硬件(GPU、TPU 等)的計算能力不斷增強、開源機器學習工具(Tensor-Flow、PyTorch 等)被廣泛采用,這一系列進展使得機器學習及其應用領域的研究成果急劇增加。其中一個強有力的指標是發布到 arXiv 上關于機器學習領域的論文數量,arXiv 是一個廣受歡迎的論文預印本托管服務,2018 年發布的論文預印本數量是 2009 年的 32 倍以上(每兩年增長一倍以上)。通過與氣候科學和醫療保健等關鍵領域的專家合作,機器學習研究人員正在幫助解決對社會有益、促進人類進步的重要問題。可以說我們生活在一個激動人心的時代。
科學和工程應用激增
計算能力的變革性增長、機器學習軟硬件的進步以及機器學習研究成果的激增,都使得機器學習應用在科學和工程領域的激增。通過與氣候科學和醫療健康等關鍵領域的合作,機器學習研究人員正在幫助解決對社會有益并促進人類發展的重要問題。這些科學和工程領域包括如下:
- 神經科學
- 分子生物學
- 醫療健康
- 天氣、環境和氣候挑戰
- 機器人
- 可訪問性
- 個性化學習
- 計算機輔助的創造性
- 重要的構建塊
- Transformers
- 計算機系統的 ML
每個細分的詳細內容請參考原文。
機器學習的未來
ML 研究社區正在出現一些有趣的研究方向,如果將它們結合起來可能會更加有趣。
首先,研究稀疏激活模型,比如稀疏門控專家混合模型(Sparsely-Gated MoE),展示了如何構建非常大容量的模型,其中對于任何給定的實例(如 2048 個專家中的兩至三個),只有一部分模型被「激活」。
其次,研究自動化機器學習(AutoML),其中神經架構搜索(NAS)或進化架構搜索(EAS)等技術可以自動學習 ML 模型或組件的高效結構或其他方面以對給定任務的準確率進行優化。AutoML 通常涉及運行很多自動化實驗,每個實驗都可能包含巨量計算。
最后,以幾個到幾十個相關任務的適當規模進行多任務訓練,或者從針對相關任務的大量數據訓練的模型中遷移學習然后針對新任務在少量數據上進行微調,這些方式已被證明在解決各類問題時都非常有效。
一個非常有趣的研究方向是把以上三個趨勢結合起來,其中在大規模 ML 加速器硬件上運行一個系統。目標是訓練一個可以執行數千乃至數百個任務的單一模型。這種模型可能由很多不同結構的組件組成,實例(example)之間的數據流在逐實例的基礎上是相對動態的。模型可能會使用稀疏門控專家混合和學習路由等技術以生成一個非常大容量的模型,但其中一個任務或實例僅稀疏激活系統中總組件的一小部分。
下圖 1 描述了一個多任務、稀疏激活的機器學習模型。
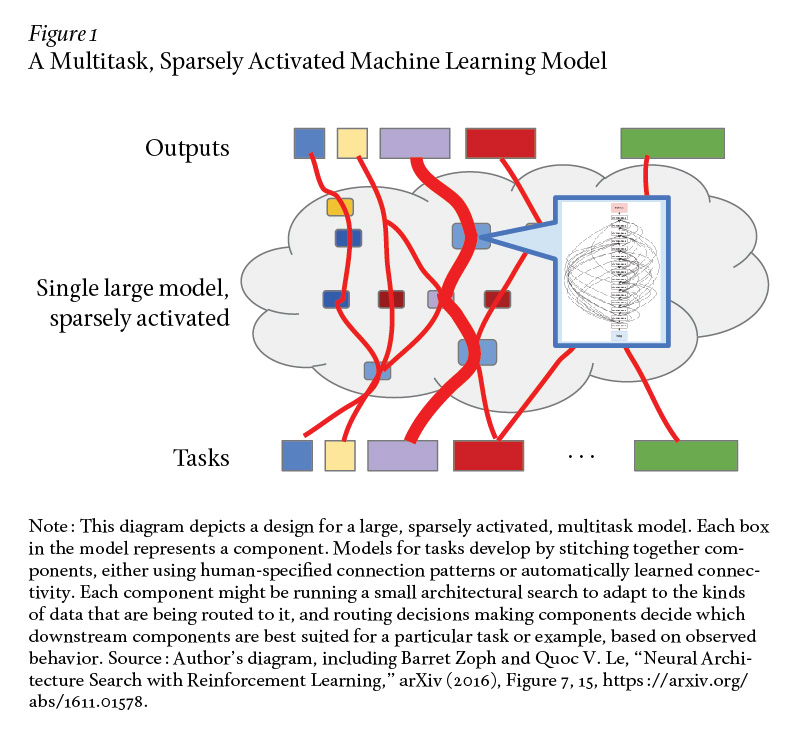
每個組件本身可能正在運行一些類 AutoML 的架構搜索,以使組件的結構適應路由到它的數據類型。新的任務可以利用在其他任務上訓練的組件,只要它有用就行。Jeff Dean 希望通過非常大規模的多任務學習、共享組件和學習路由,模型可以迅速地以高準確率來完成新任務,即使每個新任務的新實例相對較少。原因在于模型能夠利用它在完成其他相關任務時已經獲得的專業知識和內部表示。
構建一個能夠處理數百萬任務并學習自動完成新任務的單一機器學習是人工智能和計算機系統工程領域真正面臨的巨大挑戰。這需要機器學習算法、負責任的 AI(如公平性和可解釋性)、分布式系統和計算機架構等很多領域的專業知識,從而通過構建一個能夠泛化以在機器學習所有應用領域中獨立解決新任務的系統,來推動人工智能領域的發展。
負責任的 AI 開發
雖然 AI 有能力在人們日常生活的方方面面提供幫助,但所有研究人員和從業人員應確保以負責任的方式開發相關方法,仔細審查偏見、公平性、隱私問題以及其他關于 AI 工具如何運作并影響他人的社會因素,并努力以適當的方式解決所有這些問題。
制定一套明確的原則來指導負責任的 AI 發展也很重要。2018 年,谷歌發布了一套 AI 準則,用于指導企業與 AI 相關的工作和使用。這套 AI 準則列出了需要考慮的重要領域,包括機器學習系統中的偏見、安全、公平、問責、透明性和隱私。近年來,其他機構和政府也紛紛效仿這一模式,發布了自己的 AI 使用準則。Jeff Dean 希望這種趨勢能夠延續下去,直到它不再是一種趨勢,而成為所有機器學習研究和開發中遵循的標準。
Jeff Dean 對未來的展望
2010 年代的確是深度學習研究和取得進展的黃金十年。1956 年達特茅斯人工智能研討會上提出的一些最困難的問題在這十年取得了長足進步。機器能夠以早期研究人員希望的方式看到、聽到和理解語言。核心領域的成功促使很多科學領域迎來重大進展,不僅智能手機更加智能,而且隨著人們繼續創建更復雜、更強大且對日常生活有幫助的深度學習模型,未來有了更多的可能性。得益于強大機器學習系統提供的幫助,人們將在未來變得更有創造力和擁有更強的能力。


















