













機器學習在基于 URL 的客戶端監控分析中的優化和實踐

傳統的客戶端監控分析場景中,采用按照具體的 URL 進行統計分析的方法,在面對一個應用可能會訪問成千上萬條 URL 時,結果就差強人意,不能明顯地標識出應用訪問的哪些 URL 存在潛在問題。
MDAP 平臺在進行客戶端監控分析時,通過使用概率統計和機器學習的方案,將若干條相似的 URL 歸一化成同一條規則模型,然后基于該規則模型進行相關統計分析,從而提高了基于 URL 的客戶端監控分析的可用性及準確性,進而提高了 MDAP 用戶對自己應用質量的監控分析。
1. 引言
URL 作為客戶端監控分析的一個重要元素,傳統的基于 URL 的統計分析方式直接使用原始 URL 值進行統計分析,比如:
SELECT `url`, count(1) as `cnt`
FROM `web_analysis_tab`
WHERE `app_name` = 'app_1'
GROUP BY `url`;
使用上述查詢語句進行統計分析的結果是非常糟糕的,主要表現在以下幾個方面:
- 應用開發者無法 快速地、準確地 通過分析結果定位、發現潛在的應用問題、風險;
- 統計結果過于 分散 ,用戶可能會失去查看統計分析結果的興趣;
- 平臺處理過濾離散數據的統計分析,可能存在較大的 系統開銷 ,包括:查詢效率、網絡傳輸、頁面展示等。
比如,假設 app_1 訪問過 1,000,000 個不同值的 URL,而其 URL 規則模型 不足 100 個 。
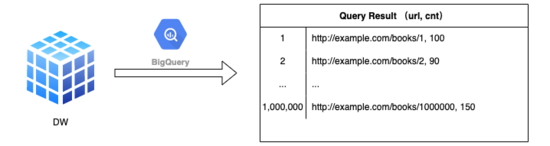
初版的 MDAP (Multi-Dimension Analysis Platform,多維度分析平臺)用戶和開發者同樣面對此類問題的困擾。為了更好地服務 MDAP 用戶,協助 MDAP 用戶快速、有效地分析自己的應用質量。MDAP 平臺基于 概率統計 理論和 機器學習 技術,根據應用上報的 URL, 自動學習 出相應的 URL 模型,利用衍生字段 ??url_pattern?? 而非原始 ??url?? 進行統計分析,從而大幅度減少了基于 URL 統計分析過于散列的情況,使得統計分析結果更加收斂,進而更方便用戶使用 MDAP 對自己的應用質量進行分析查看。
本文剩余部分的結構安排如下:在第 2 節中,結合具體例子講解 MDAP 對解決 URL 歸一化問題的思考。第 3 節,介紹 MDAP 是如何對 URL 進行歸一化處理的總體框架,并在第 4 節中進行詳細的算法描述。優化效果的測試與評估在第 5 節中進行闡述。最后,在第 6 節中,進行總結并對未來進行展望。
2. 問題思考
本章節將解釋這項工作的詳細動機和思考。針對三種不同方案進行分析,闡述配置/上傳 URL 模型規則的不可行性;通過一個具體的例子,展示自底向上的成對策略如何工作以及何時失敗;并解釋模式樹為何有效。
2.1 用戶配置方案
配置/上傳 URL 模型規則
為了將 URL 轉換成對應的 URL 模型規則,最先考慮的方案是在平臺中,允許用戶配置/上傳應用相關的 URL 模型規則,但隨即我們發現該方案存在幾點問題:
golang/gin : ??GET http://example.com/users/:user_name?? ;
golang/grpc-gateway : ??GET http://example.com/{name=users/*}?? ,遵守 Google API 設計規范;
java/spring : ??GET http://example.com/users/{user_name}?? 。
- 繁瑣的用戶配置。MDAP 平臺的宗旨是為了協助平臺用戶監控、統計、分析自己的應用質量。為了進行 URL 模型匹配而需要平臺用戶配置/上傳 URL 模型規則,無疑增加了平臺用戶的負擔。同時,平臺用戶極有可能遺忘進行新的 URL 模型規則變更,從而嚴重影響 URL 模型匹配效果,進而回退到傳統的基于 URL 統計分析模型。
- 差異化的 URL 模型規則。不同語言、框架的 URL 路由規則差異大,巨大的風格差異不利于平臺進行 URL 規則模型的統一管理,比如下面三種獲取某一具體用戶詳情信息的 URL 模型規則:
- 數據巨大的外部 URL。根據 MDAP 平臺統計分析,單應用訪問非本應用服務的外部 URL 地址數量平均占比約為 10%-30%。這些外部 URL 多為 Google、Facebook 等網站的路由地址,使用 MDAP 平臺的用戶在開發自己應用的時候,并不完全了解外部 URL 的模型規則,因此無法在 MDAP 平臺進行相關的配置。
綜上所述,基于用戶自主配置 URL 模型規則的方案是 不可行的 。因此,MDAP 平臺需要基于應用上報的 URL 自動學習對應的 URL 規則模型。
2.2 機器學習方案
2.2.1 URL 協議語法介紹
為了幫助讀者更好地理解后續算法設計以及 MDAP 思考解決問題的思路,本文需要對 URL 的語法結構進行簡單介紹,如下圖所示:

根據上圖所示,我們可以將 URL 分解為一些通用的 URL 組件: ??schema?? 、 ??authority?? 、 ??path?? 、 ??query?? 及 ??fragment?? ,其通過 ??:?? 、 ??/?? 、 ????? 及 ??#?? 進行分割。例如,URL ??http://example.com/books/search?name=go&isbn=1234?? 可以分解成如下幾部分組件:
schema: http
authority: example.com
path: {"path0": "books", "path1": "search"}
query: {"name": "go", "isbn": "1234"}
在稍后的算法設計中,本文重點關注 ??path?? 和 ??query?? 兩部分數據,將上述 URL 轉換成 ??Tuple(authority, Array[Tuple(K, V)])?? 的結構,具體如下:
(
"example.com",
[
("path0", "books"),
("path1", "search"),
("name", "go"),
("isbn", "1234")
]
)
2.2.2 自底向上結對策略思考
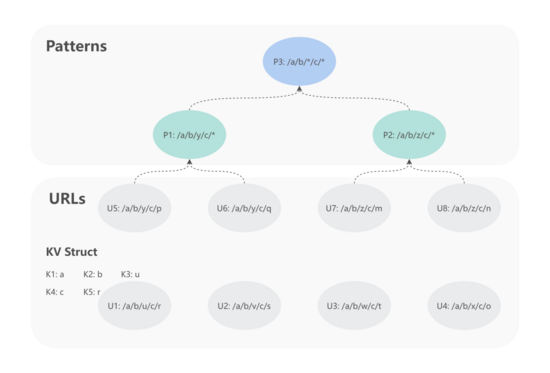
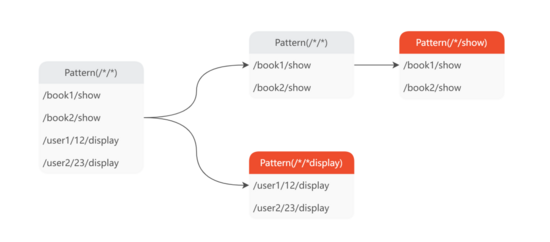
如上圖所示,其中存在 8 條不同的 URL,MDAP 采用 2.2.1 將每條 URL 轉換成 KV 結構,比如: ??U1 -> {"K1": "a", "K2": "b", "K3": "y", "K4": "c", "K5": "*"}?? 。使用自底向上策略生成 URL 規則模型的方式,可以清楚地看到 K3 和 K5 應該被歸一化為 ??*?? 。其歸一化過程如下:
- U5 + U6 -> P1 : ?
?({"K1": "a", "K2": "b", "K3": "y", "K4": "c", "K5": "*"})?? - U7 + U8 -> P2 : ?
?({"K1": "a", "K2": "b", "K3": "z", "K4": "c", "K5": "*"})?? - P1 + P2 -> P3 : ?
?({"K1": "a", "K2": "b", "K3": "*", "K4": "c", "K5": "*"})??
上述步驟首先基于 U5、U6 和 U7、 U8 分別生成 P1 和 P2,然后基于 P1、P2 生成理想的 URL 模型規則 P3。但如果 U6 不存在的話,就會導致 P1 無法生成,進一步 P3 也無法生成。此外,在上述示例中 U1 - U4 同樣不適合用來結對生成規則模型。
2.2.3 URL 模式樹
相對于自底向上策略,模式樹可以充分利用整個訓練集的統計信息。這樣,學習過程變得更加可靠和穩健,不再受到隨機噪聲的影響。對于 2.2.2 中的示例,即使某些 URL 不存在,仍然可以通過考慮所有其他 URL(包括 U1 ~ U4)。
其次,使用模式樹,可以通過直接基于樹節點總結規則來顯著提高學習效率。例如,不再需要 P1 和 P2,可以根據上述模式直接生成 P3。詳細的算法描述將在第 4 節中進行闡述。
3. 框架總覽
本章節將闡述 MDAP 進行 URL 模型規則學習和匹配的方法和架構。
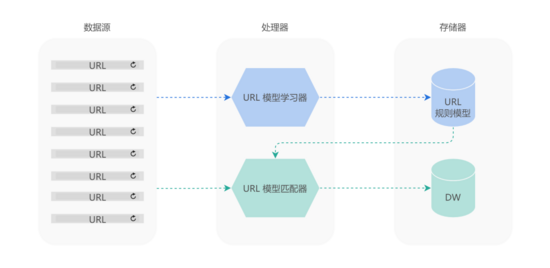
如上圖所示:
- 首先,MDAP 使用 URL 模型學習器,基于應用上報的 URL 數據,自動學習出 URL 規則模型,并將其進行存儲;
- 然后,在 URL 模型匹配器中,MDAP 將 URL 規則模型作用于應用上報的 URL 數據,生成元組 ?
?Tuple(url, url_pattern)?? 后,將其存入數據倉庫之中。
考慮到各應用上報到 MDAP 的 URL 數據量巨大,MDAP 平臺使用 Flink 進行 URL 模型規則學習,具體如下:
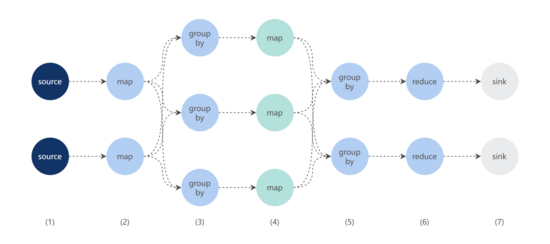
- 從數據源中讀取 URL 數據;
- 按照 2.2.1 將各 URL 轉化成 ?
?Tuple(authority, Array[Tuple(K, V)])?? 的結構; - authority + salt authority salt salt length(Array[Tuple(K, V)])
- 對同一分組下的 URL,使用模式樹算法生成 URL 規則模型;
- 再按照 ?
?authority?? 將步驟 4 生成的結果分組; - 合并相同 ?
?authority?? 下的模型; - 保存 URL 規則模型。
關于 URL 模型匹配器,MDAP 使用了 ??Trie?? 的衍生變種結構,來提升 URL 模型匹配的效率,在本文中不再贅述,感興趣的讀者可以去了解學習 Trie 這種數據結構。
4. 算法描述
本章節將闡述如何基于模式樹生成 URL 規則模型,重點闡述基于熵進行節點分裂及基于高斯分布、馬爾可夫鏈進行顯著值、離散值區分。
如上圖所示,生成 URL 規則模型的算法包括以下 6 步:
- 初始化模式樹根節點,其包含全部 URL;
- 找出 值 元素 最適合分裂 的 URL 鍵( ?
?path_index?? 或 ??query_key?? ); - 區分出第 2 步找出的 URL 鍵對應的 顯著值 (Salient Value)和 離散值 (Trivial Value);
- 將顯著值保留,并將離散值歸一化為 ?
?*?? ,并基于顯著值和 ??*?? 分裂模式樹; - 重復 2-4 步,直至所有的 URL 鍵都已處理;
- 遍歷模式樹的葉子節點,收集各 URL 節點的模型規則。
在本算法中,最關鍵的兩個步驟為第 2 步和第 3 步。
4.1 找出值元素最適合分裂的 URL 鍵
信息 熵 的概念用來解決如何找出最適合分裂的 URL 鍵。根據值越隨機的 URL 鍵,其熵越大。盡可能聚合鍵值變化少的部分,把變化多的部分后置計算或進行通配處理,因此,需要找到可以最小化熵的 URL 鍵。計算 URL 鍵對應的熵的公式如下:
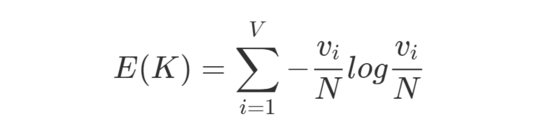
其中,V 為該 URL 鍵對應的值元素的個數,N 為全部元素出現的總次數,vi 為第 i 個元素出現的頻次。
根據上述公式,查找出熵最小的 URL 鍵,并結合 4.2 區分出顯著值和離散值,即可進行模型樹節點分裂。
4.2 區分顯著值和離散值
4.2.1 基于高斯分布區分顯著值和離散值
根據對 MDAP 收集的 URL 歷史數據的分析結果,假設 URL 中每個鍵對應的值列表服從高斯分布:
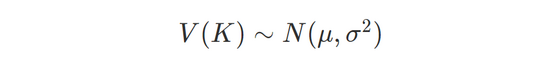
因此,將熵最小的鍵的值按照其頻次進行倒序排序,并對計算相鄰的兩個值之間的頻次下降速度,以下降速度最大的兩個節點為界,即可區分出顯著值和離散值,其中分界點之左為顯著值,之右為離散值,比如:
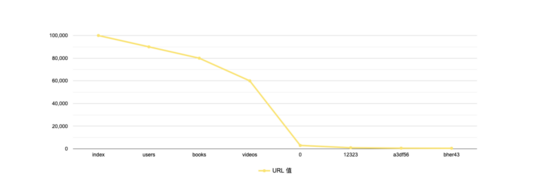
在上圖中,頻次速度下降最大兩個節點為 ??videos?? 和 ??0?? ,因此,顯著值包括:
["index", "users", "books", "videos"]
離散值包括:
["0", "12323", "a3df56", "bher43"]
4.2.2 基于馬爾可夫鏈和密度函數進行剪枝
雖然按照 4.2.1 可以區分顯著值和離散值,但其效果并非總是有效,比如:
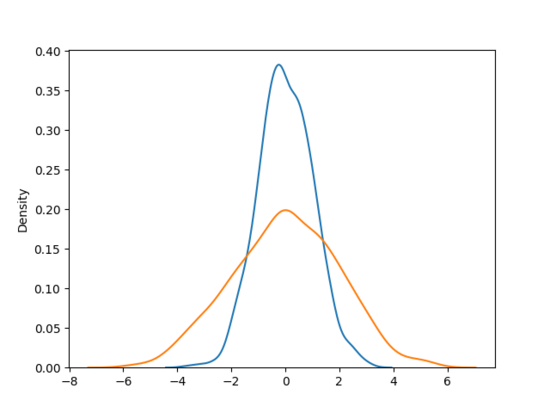
在上圖中,如 URL 鍵對應的值服從藍色線條的高斯分布,則通過 4.2.1 可區分出顯著值和離散值;但如果 URL 鍵對應的值服從橙色線條甚至是比橙色線條更扁平的高斯分布,則極容易將離散值誤判為顯著值,因此需要輔助算法進行剪枝操作。
根據 MDAP 平臺對 URL 數據的分析,發現離散的 URL 符合以下幾個特征:
- 數字,比如: ?
?/users/123?? 中的 ??123?? ; - 哈希值,比如: ?
?/files/12af8712?? 中的 ??12af8712?? ; - base64,比如: ?
?/something/aGVsbG8K?? 中的 ??aGVsbG8K?? 等其他非人類語言。
滿足以上特征的(除數字外)字符串統稱為亂語(Gibberish)。為了對亂語和數字類型的 URL 鍵值進行剪枝,MDAP 引入馬爾可夫鏈和密度函數進行亂語、數字識別,但由于縮略詞(Abbreviate)不屬于人類標準的語言,有極大概率被誤判成亂語,因此需要配置縮略詞表進行先驗判斷。具體算法步驟如下:
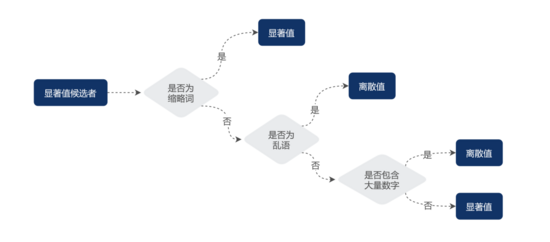
- 判斷給定字符串是否在縮略詞表,如果是,保留其為顯著值并結束,否則繼續后續步驟;
- 判斷給定字符串是否為亂語,如果是,將其歸為離散值并結束,否則繼續后續步驟;
- 判斷給定字符串是否含有大量數字,如果是,將其歸為離散值,否則保留其為顯著值。
基于馬爾可夫鏈進行亂語判別
馬爾可夫鏈在 NLP(自然語言處理)中廣泛使用,MDAP 平臺使用馬爾可夫鏈的方式比較簡單,通過 ??2-gram?? 的方式進行字符串分詞,從而計算連續字符串出現的概率,比如:
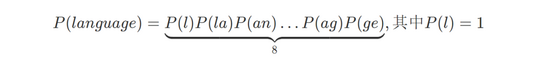
使用馬爾可夫鏈,將大文本作為訓練集,生成相應的概率矩陣:
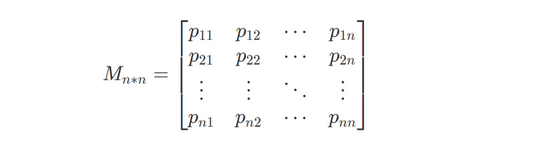
然后,將該矩陣作用于好文本和壞文本,計算出判斷字符串是否為亂語的閾值:
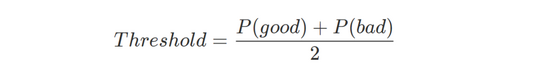
最后,通過下面的公式判斷給定的字符串是否為亂語:
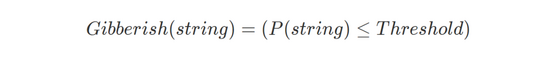
基于密度函數進行數字含量判別
考慮到主要版本號之類的字符串,比如 ??v1?? ,需要保留為顯著值,而像用戶 ID 之類的字符串,比如 ??1234?? ,需要被歸類成離散值,因此需要采用如下的公式,進行字符串數組含量判斷。
5. 算法優化測試與效果展示
本章節將展示使用模式樹生成 URL 規則模型的去重效果、URL 匹配度,并展示在 MDAP 平臺中的實際效果。
5.1 算法優化測試
5.1.1 壓縮率測試
首先,MDAP 收集一部分來自生產環境的數據作為訓練集來生成 URL 規則模型,其中各域名包含 ??100,000 - 2,000,000?? 原始 URL 數據,具體如下圖所示:
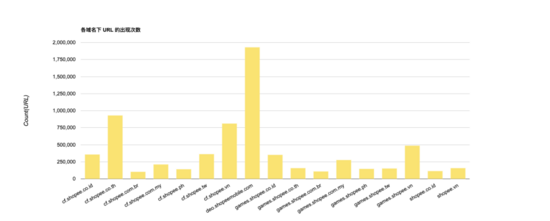
然后,將原始 URL 進行 ??distinct?? 去重后得到 ??10 - 16,000?? 條 URL,具體如下圖所示:
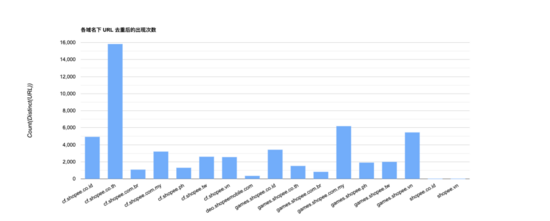
最后,將原始 URL 經過第 4 節的算法處理后,生成的 URL 規則模型條數為 ??1 - 85?? 條,具體如下圖所示:
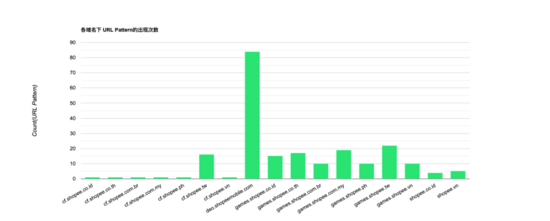
通過對比去重 URL 和 URL 規則模型的統計效果圖,可以明顯發現, 通過模式樹生成的 URL 模型規則的數量遠小于簡單 ??distinct?? 去重的結果 。
5.1.2 匹配度測試
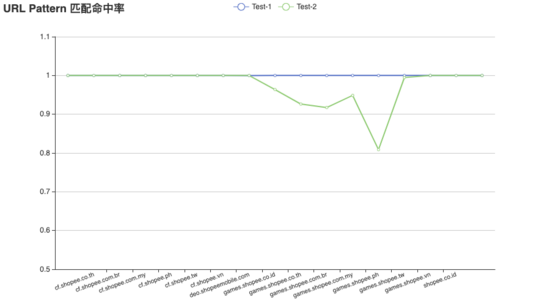
將 5.1.1 生成的 URL 規則模型在兩個不同的測試集之間進行驗證,其中測試集 1(Test-1)為與訓練集同日但不同時間段的數據,測試集 2(Test-2)為距離測試集 1 一周之后的數據。如上圖所示,測試集 1 的數據匹配規則模型的命中率很高(大于等于 99.99%),測試集 2 的命中率相對較差(80.89% - 100%)。
5.1.3 測試結論
通過 5.1.1 和 5.1.2 的測試結果,可以得出以下結論:
- 基于模式樹生成的 URL 規則模型進行統計分析,可以極大地統計分析結果的收斂度;
- URL 與模型規則的匹配度隨訓練時間與匹配時間的范圍變化而變化,相差時間越近,匹配度越好。
5.2 效果展示
MDAP 平臺目前使用 ??T + 1?? 的方式進行 URL 規則模型匹配,基于平臺數據監測統計結果,模型規則的平均匹配失敗率約為 ??0.3%?? 。使用模型下規則基于 URL 統計分析的頁面展示效果如下,其中第一張圖為基于 ??distinct?? 去重后的 URL 進行統計分析(約 ??8110?? 條),第二張圖為基于 URL 規則模型進行統計分析(約 ??60?? 條)。
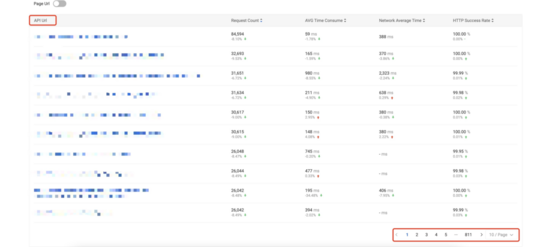
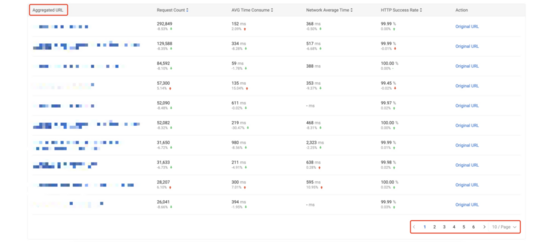
6. 總結與展望
MDAP 平臺基于模型樹構建實現了 URL 歸一化處理,并基于歸一化的結果提高了基于 URL 進行統計分析的能力和準確性。
但目前仍然存在一定缺陷,主要包括兩方面:
- 規則學習周期相對較長,對于準實時數據處理能力較差;
- 模型迭代功能尚未完善,存在一定缺陷。
因此,后續 MDAP 平臺將在此兩方面進行進一步優化,從而提高 MDAP 在基于 URL 進行統計分析時的數據質量。
本文作者
Daniel,MDAP 聯合項目團隊后端工程師,來自 Shopee Engineering Infrastructure 團隊。
















