













一種管理深度學習數據集的新方法
譯文Hub簡介

Activeloop的Hub是一個開源Python軟件包,可將數據排列在類似Numpy的數組中。它與Tensorflow和PyTorch等深度學習框架無縫集成,可加快GPU處理和訓練。我們可以使用Hub API來更新數據、可視化數據以及創建機器學習管道。
Hub讓我們可以存儲圖像、音頻、視頻和時間序列數據,又能做到訪問起來很快。數據可以存儲在GCS/S3存儲桶、本地存儲或Activeloop云上。數據可直接用于訓練Pytorch模型,這樣您無需構建數據管道。Hub還提供數據版本控制、數據集搜索查詢和分布式工作負載。
我在使用Hub后覺得很棒,能夠在幾分鐘內創建數據并將數據推送到云端。本文介紹如何使用Hub來創建和管理數據集。
- 在Activeloop云上初始化數據集
- 處理圖像
- 將數據推送到云端
- 數據版本控制
- 數據可視化
Activeloop存儲
Activeloop為開源數據集和私有數據集提供免費存儲。您還可以通過推薦介紹獲得多達 200 GB的免費存儲空間。Activeloop的Hub與Database for AI對接,讓我們可以使用標簽可視化數據集,復雜的搜索查詢讓我們可以高效地分析數據。該平臺還含有100多個圖像分割、分類和對象檢測方面的數據集。
要創建帳戶,您可以使用Activeloop網站來注冊,或者輸入“!activeloop register”。該命令將要求您添加用戶名、密碼和電子郵件。成功創建帳戶后,我們將使用“!activeloop login” 來登錄。現在,我們可以直接從本地機器創建和管理云數據集。
如果您使用Jupyter Notebook,請使用“!”,否則直接在CLI中添加沒有!的命令。
!activeloop register
!activeloop login -u -p
初始化Hub數據集
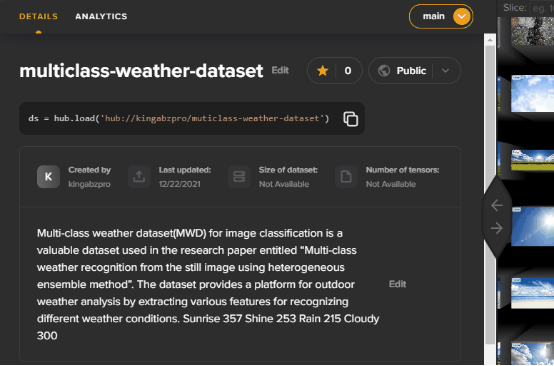
在本教程中,我們將使用采用(CC BY 4.0)的Kaggle數據集Multi-class Weather。該數據集含有四個基于天氣分類的文件夾;Sunrise、Shunshine、Rain和Cloudy。
首先,我們需要安裝hub和kaggle軟件包。kaggle軟件包將允許我們直接下載數據集并解壓縮。
!pip install hub kaggle
!kaggle datasets download -d pratik2901/multiclass-weather-dataset
!unzip multiclass-weather-dataset
下一步,我們將在Activeloop云上創建HUB數據集。數據集函數還可以創建新數據集或訪問舊數據集。您還可以提供AWS存儲桶地址,以便在亞馬遜服務器上創建數據集。想在Activeloop上創建數據集,我們需要傳遞含有用戶名和數據集名稱的URL。
“hub://<username>/<datasetname>”
import hub
ds = hub.dataset('hub://kingabzpro/muticlass-weather-dataset')
數據預處理
在將數據處理成hub格式之前,我們需要準備數據。下面的代碼將提取文件夾名稱并將其存儲在“class_names”變量中。在第二部分,我們將創建數據集文件夾中可用的文件列表。
from PIL import Image
import numpy as np
import os
dataset_folder = '/work/multiclass-weather-dataset/Multi-class Weather Dataset'
class_names = os.listdir(dataset_folder)
files_list = []
for dirpath, dirnames, filenames in os.walk(dataset_folder):
for filename in filenames:
files_list.append(os.path.join(dirpath, filename))
file_to_hub函數接受三個參數:文件名、數據集和類名。它從每個圖像中提取標簽,并將它們轉換成整數。它還將圖像文件轉換成類似Numpy的數組,并將它們附加到tensor。就這個項目而言,我們只需要兩個tensor,一個用于標簽,一個用于圖像數據。
.compute
def file_to_hub(file_name, sample_out, class_names):
## First two arguments are always default arguments containing:
# 1st argument is an element of the input iterable (list, dataset, array,...)
# 2nd argument is a dataset sample
# Other arguments are optional
# Find the label number corresponding to the file
label_text = os.path.basename(os.path.dirname(file_name))
label_num = class_names.index(label_text)
# Append the label and image to the output sample
sample_out.labels.append(np.uint32(label_num))
sample_out.images.append(hub.read(file_name))
return sample_out
不妨創建一個帶有“png”壓縮的圖像tensor和一個簡單的標簽tensor。確保tensor的名稱應與我們在file_to_hub函數中提到的名稱相似。想了解有關tensor的更多信息,請參閱《API摘要 - Hub 2.0》:https://docs.activeloop.ai/api-basics#creating-tensors-and-adding-data。
最后,我們將通過提供files_lists、hub數據集實例“ds”和class_names來運行file_to_hub函數。由于需要轉換數據并推送到云端,這需要幾分鐘。
with ds:
ds.create_tensor('images', htype = 'image', sample_compression = 'png')
ds.create_tensor('labels', htype = 'class_label', class_names = class_names)
file_to_hub(class_names=class_names).eval(files_list, ds, num_workers = 2)
數據可視化
現在該數據集在multiclass-weather-dataset上公開可用。我們可以使用標簽探索數據集或添加描述,以便其他人可以了解有關許可證信息和數據分布的更多信息。Activeloop不斷添加新功能,以改善查看體驗。
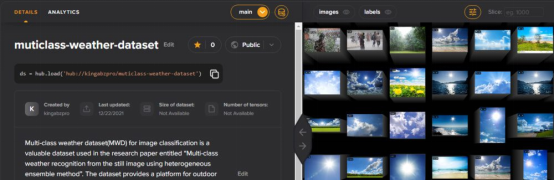
我們還可以使用Python API來訪問數據集。我們將使用PIL的Image函數將數組轉換成圖像,并將其顯示在Jupyter筆記本中。
Image.fromarray(ds["images"][0].numpy())

為了訪問標簽,我們將使用含有分類信息的class_names,并使用“標簽”tensor來顯示標簽。
class_names = ds["labels"].info.class_names
class_names[ds["labels"][0].numpy()[0]]
>>> 'Cloudy'
提交
我們還可以創建不同的分支,并管理不同的版本,比如Git和DVC。在本節中,我們將更新class_names信息,并使用該信息創建提交。
ds.labels.info.update(class_names = class_names)
ds.commit("Class names added")
>>> '455ec7d2b49a36c14f3d80d0879369c4d0a70143'
正如我們所看到的,日志顯示我們已成功地將更改提交到主分支。想了解有關版本控制的更多信息,請參閱《數據集版本控制 - Hub 2.0》:https://docs.activeloop.ai/getting-started/step-8-dataset-version-control。
log = ds.log()
---------------
Hub Version Log
---------------
Current Branch: main
Commit : 455ec7d2b49a36c14f3d80d0879369c4d0a70143 (main)
Author : kingabzpro
Time : 2022-01-31 08:32:08
Message: Class names added
您還可以使用Hub UI查看所有分支和提交。
原文標題:??A New Way of Managing Deep Learning Datasets??,作者:Abid Ali Awan


















