進(jìn)程調(diào)度:我太難了!
1. 任務(wù)切換
現(xiàn)在有一塊CPU,但是有兩個(gè)程序都想來執(zhí)行,我們需要開發(fā)一個(gè)任務(wù)調(diào)度程序。

只有兩個(gè)程序,so easy啦!讓它們交替執(zhí)行就行了。
為了實(shí)現(xiàn)切換,我們提供一個(gè)API,這兩個(gè)程序執(zhí)行一會(huì)兒就主動(dòng)調(diào)用一下這個(gè)API,然后在這個(gè)API內(nèi)部實(shí)現(xiàn)任務(wù)的切換。
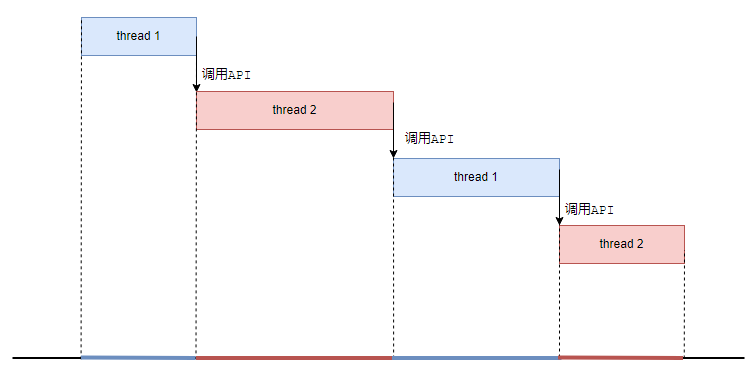
所謂的切換,其實(shí)就是把當(dāng)前進(jìn)程的上下文(也就是CPU一堆的寄存器值)保存到進(jìn)程的TCB(進(jìn)程控制塊,每個(gè)進(jìn)程對(duì)應(yīng)的內(nèi)存數(shù)據(jù)結(jié)構(gòu))里。然后把另一個(gè)進(jìn)程TCB里的上下文寄存器的值裝載起來,開始運(yùn)行。
這是一種主動(dòng)配合式的調(diào)度。
2. 搶占
然而,理想很美好,現(xiàn)實(shí)很骨感。
這些個(gè)程序可能不是那么聽話,可能很久都不調(diào)用我們的API交出CPU,甚至可能搞了個(gè)死循環(huán),另一個(gè)程序永遠(yuǎn)也沒機(jī)會(huì)執(zhí)行。
看來:不能依賴程序主動(dòng)交出執(zhí)行權(quán),調(diào)度程序需要有搶占CPU的能力!
怎么搶占呢?
我們可以利用時(shí)鐘中斷!
因?yàn)橐坏┯兄袛嗍录絹恚珻PU就得去執(zhí)行中斷處理程序。只要在時(shí)鐘中斷的處理函數(shù)里面加入調(diào)度入口,就能搶到CPU的執(zhí)行權(quán)。
為了公平起見,我們決定讓每個(gè)進(jìn)程都執(zhí)行一小段時(shí)間,我們把這個(gè)叫做時(shí)間片,比如100ms,然后輪流執(zhí)行它們就可以了,差不多是這個(gè)樣子:
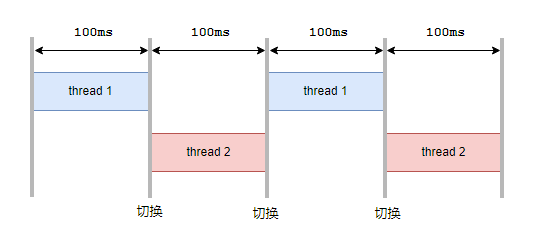
我們給CPU編程,讓它每1ms發(fā)送一次時(shí)鐘中斷。在每個(gè)時(shí)鐘中斷到來時(shí),檢查當(dāng)前的線程運(yùn)行時(shí)間是否足夠100ms,如果沒有就將當(dāng)前線程運(yùn)行的時(shí)間+1ms,然后中斷處理結(jié)束,讓它繼續(xù)運(yùn)行。
如果檢查發(fā)現(xiàn)時(shí)間已經(jīng)到了100ms,就切換另一個(gè)進(jìn)程來運(yùn)行。
100ms對(duì)于人類幾乎感知不到,所以還以為兩個(gè)線程是在同時(shí)運(yùn)行。
一個(gè)最最最簡(jiǎn)單的任務(wù)調(diào)度程序就完成了。
3. 阻塞
漸漸地,進(jìn)程多了起來,3個(gè)、4個(gè)、5個(gè)···
我們用一個(gè)隊(duì)列把它們存起來,先進(jìn)先出,就叫做就緒隊(duì)列吧,意思是準(zhǔn)備要排隊(duì)執(zhí)行的隊(duì)列。
所有就緒的進(jìn)程,依次排隊(duì)被我們的調(diào)度程序翻牌子執(zhí)行。
沒過多久,我們發(fā)現(xiàn)有些進(jìn)程經(jīng)常占著茅坑不xx,在sleep或者等待鎖的時(shí)候,白白霸占著CPU空轉(zhuǎn),搞得隊(duì)列里其他進(jìn)程怨聲載道。
那咱們對(duì)調(diào)度程序再做一個(gè)優(yōu)化吧:當(dāng)有進(jìn)程等待鎖、I/O等待或者sleep的時(shí)候,調(diào)度程序也需要介入,即使分配給它的時(shí)間片還沒用完,也要讓它主動(dòng)交出CPU,并把它放到另一個(gè)等待隊(duì)列里去,等到等待的條件滿足的時(shí)候,再把它請(qǐng)回到就緒隊(duì)列排隊(duì)。
現(xiàn)在,我們的調(diào)度程序不再允許有占著CPU卻摸魚的現(xiàn)象發(fā)生。
4. 優(yōu)先級(jí)
后來,進(jìn)程進(jìn)一步多了起來,6個(gè)、7個(gè)、···、100個(gè)。
每一個(gè)進(jìn)程都執(zhí)行100ms,轉(zhuǎn)一圈下來就是10000ms=10s。
一個(gè)打字程序,按了鍵盤10s鐘之后才反應(yīng)過來,這系統(tǒng)卡的一匹,簡(jiǎn)直沒法用。
我們可以把每個(gè)進(jìn)程執(zhí)行的時(shí)間縮短為10ms,轉(zhuǎn)一圈下來變成了1000ms=1s,情況好了很多,但還是有點(diǎn)卡。
而且這一招架不住進(jìn)程越來越多,200個(gè),300個(gè),甚至更多,轉(zhuǎn)一圈的時(shí)間還是在變長(zhǎng)。
但又不好繼續(xù)壓縮時(shí)間,否則就花太多時(shí)間在切換上了,真正執(zhí)行的時(shí)間變少。
歸根結(jié)底,問題在于進(jìn)程多了以后,再按照順序輪轉(zhuǎn)不合時(shí)宜了。
得讓一些進(jìn)程擁有VIP特權(quán),能夠優(yōu)先執(zhí)行。
要不這樣吧,給每個(gè)進(jìn)程設(shè)定一個(gè)優(yōu)先級(jí),從1到40,總共40個(gè)優(yōu)先級(jí),數(shù)字越大,優(yōu)先級(jí)越高。

調(diào)度的時(shí)候,把隊(duì)列遍歷一圈,找出里面優(yōu)先級(jí)最高的進(jìn)程來執(zhí)行。
現(xiàn)在,我們只需要給打字程序這樣的交互式進(jìn)程設(shè)定一個(gè)高優(yōu)先級(jí),再次按下鍵盤后,很快就能得到響應(yīng)了。
5. O(1)復(fù)雜度
每次調(diào)度的時(shí)候都得去遍歷所有的進(jìn)程,這復(fù)雜度是O(N)。
進(jìn)程少倒還不打緊,多了以后就有些惱火了,這效率太低了。
讓所有進(jìn)程一起排在一個(gè)大的隊(duì)列里,不是一個(gè)明智的做法。
要不我們按照優(yōu)先級(jí)拆分成不同的隊(duì)列吧!每個(gè)優(yōu)先級(jí)單獨(dú)弄一個(gè)就緒隊(duì)列,就是40個(gè)隊(duì)列,分開排隊(duì),找起來效率更高。
調(diào)度的時(shí)候,按照優(yōu)先級(jí)順序,依次來看每一個(gè)隊(duì)列是否有可以執(zhí)行的進(jìn)程,找到后就從隊(duì)列里取出來執(zhí)行,相同優(yōu)先級(jí)隊(duì)列里面的進(jìn)程,輪流執(zhí)行。

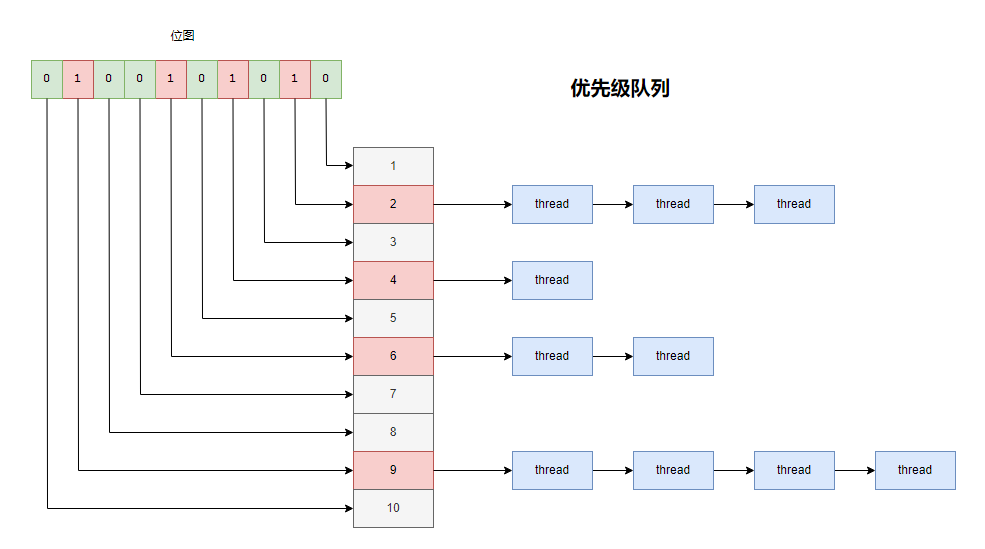
為了快速知道每一個(gè)優(yōu)先級(jí)隊(duì)列里面有沒有進(jìn)程,咱們?cè)倥粋€(gè)位圖,40個(gè)bit,每一位表示一個(gè)優(yōu)先級(jí)隊(duì)列,如果是1就知道這個(gè)優(yōu)先級(jí)的隊(duì)列里有進(jìn)程需要執(zhí)行,為0就沒有。
關(guān)于這個(gè)優(yōu)先級(jí)隊(duì)列,差不多可以這樣定義:
struct priority_queue {
int nr_active; // 所有隊(duì)列的進(jìn)程總數(shù)
unsigned long bitmap[BITMAP_SIZE]; // 位圖
struct list_head queue[MAX_PRIO]; // 隊(duì)列數(shù)組
};
現(xiàn)在找起來可方便了,進(jìn)程再多也沒事,都可以在O(1)的時(shí)間復(fù)雜度里找到要調(diào)度的進(jìn)程。
6. 餓死問題
系統(tǒng)運(yùn)行了一段時(shí)間,發(fā)現(xiàn)了一個(gè)重要的問題:由于高優(yōu)先級(jí)進(jìn)程的存在,低優(yōu)先級(jí)的程序很難得到執(zhí)行機(jī)會(huì),容易被“餓死”。
除非高優(yōu)先級(jí)的進(jìn)程執(zhí)行結(jié)束,或者在睡眠等待,否則只要它一直待在就緒隊(duì)列里,其他進(jìn)程就沒有機(jī)會(huì)。
這可不行呀,雖然你優(yōu)先級(jí)高,但總得給別人分口吃的吧。
看來進(jìn)程執(zhí)行完成之后,不能馬上把它再放回原來的隊(duì)列里去,得這一輪大家都執(zhí)行過后才行。
不放回原隊(duì)列,那放哪里去呢?
干脆再弄一個(gè)優(yōu)先級(jí)隊(duì)列,把它叫做expired隊(duì)列,并把原來的優(yōu)先級(jí)隊(duì)列叫做active隊(duì)列。
調(diào)度的時(shí)候,從active隊(duì)列里提取進(jìn)程。完成一次調(diào)度后就把它放到expired隊(duì)列,等原來的隊(duì)列里的進(jìn)程都挨個(gè)執(zhí)行完一圈,active隊(duì)列就空了,它們都來到了這個(gè)expired隊(duì)列,然后交換兩個(gè)隊(duì)列,從頭再來。
嗯,為了避免內(nèi)存拷貝。把a(bǔ)ctive和expired定義成指針,到時(shí)候直接交換兩個(gè)指針,更省事兒!
把原來的隊(duì)列封裝一下:
struct runqueue {
struct priority_queue* active;
struct priority_queue* expired;
struct priority_queue array[2];
};
就這樣,所有進(jìn)程在兩個(gè)隊(duì)列中兜兜轉(zhuǎn)轉(zhuǎn),現(xiàn)在低優(yōu)先級(jí)的進(jìn)程也有機(jī)會(huì)被執(zhí)行到了,不會(huì)被餓死了。
7. 優(yōu)先級(jí)與時(shí)間片
到目前為止,雖然進(jìn)程有優(yōu)先級(jí)之分,但這只影響它們的調(diào)度順序,而不影響它們執(zhí)行的時(shí)間,所有的進(jìn)程時(shí)間片依然是100ms。
現(xiàn)在,優(yōu)先級(jí)高的程序提出了抗議:我執(zhí)行的任務(wù)很重要,需要給我更長(zhǎng)的CPU時(shí)間片!
于是,一個(gè)新的需求來了:不同優(yōu)先級(jí)進(jìn)程,運(yùn)行的時(shí)間片需要有區(qū)別。
優(yōu)先級(jí)高的,時(shí)間片得長(zhǎng)一點(diǎn);優(yōu)先級(jí)低的,時(shí)間片得短一些。
這個(gè)需求倒也好辦,我們以中間優(yōu)先級(jí)20為基礎(chǔ),設(shè)定優(yōu)先級(jí)為20的進(jìn)程時(shí)間片是100ms,優(yōu)先級(jí)每增加1級(jí),時(shí)間片+5ms,每減少一級(jí),時(shí)間片-5ms。
優(yōu)先級(jí) ---- 時(shí)間片
1 5ms
2 10ms
3 15ms
··· ···
18 90ms
19 95ms
20 100ms # base
21 105ms
··· ···
39 195ms
40 200ms
現(xiàn)在,高優(yōu)先級(jí)的進(jìn)程不僅能夠優(yōu)先被執(zhí)行,給它分配的運(yùn)行時(shí)間也更多了。
上面的時(shí)間片分配算法還不算是完美,它有一個(gè)問題:
如果現(xiàn)在只有兩個(gè)優(yōu)先級(jí)為20和21的進(jìn)程在運(yùn)行,時(shí)間片分別是100ms和105ms,那么兩個(gè)進(jìn)程分別能獲取到的CPU時(shí)間占比是100/(100+105)=48.7%和105/(100+105)=51.2%。
優(yōu)先級(jí)增加1,CPU時(shí)間占比多了2.5%,看起來沒什么問題。
現(xiàn)在如果換成只有兩個(gè)優(yōu)先級(jí)為1和2的進(jìn)程在運(yùn)行,時(shí)間片分別是5ms和10ms,那么兩個(gè)進(jìn)程分別能獲取到的CPU時(shí)間占比是5/(5+10)=33.3%和10/(5+10)=66.7%。
優(yōu)先級(jí)2只比優(yōu)先級(jí)1的進(jìn)程高了一級(jí),獲取的CPU時(shí)間占比就翻了一倍!
同樣是優(yōu)先級(jí)加1,這差距咋就這么大呢?
說好的公平呢?
8. 公平調(diào)度:時(shí)間分配
現(xiàn)在,我們換個(gè)思路,不用絕對(duì)時(shí)間片,而用相對(duì)時(shí)間片。
比如設(shè)定我們的調(diào)度周期為100ms,這100ms讓所有可以運(yùn)行的進(jìn)程來瓜分,100ms之后所有就緒的進(jìn)程都被執(zhí)行了一圈兒。
那么問題來了,如何讓進(jìn)程們來瓜分這100ms呢?
當(dāng)然是按照優(yōu)先級(jí)來分。
我們給不同優(yōu)先級(jí)的進(jìn)程設(shè)置不同的權(quán)重,優(yōu)先級(jí)高的,權(quán)重值高,就多分一點(diǎn)兒,優(yōu)先級(jí)越低的,權(quán)重值低,就少分一點(diǎn)兒。


那這個(gè)權(quán)重值設(shè)定為多少好呢?
別急,有人已經(jīng)幫我們想好了,就是下面這個(gè)數(shù)組。
想知道為什么是這些數(shù)字而不是別的,是有講究的,不過先不用管。
const int sched_prio_to_weight[40] = {
88761, 71755, 56483, 46273, 36291,
29154, 23254, 18705, 14949, 11916,
9548, 7620, 6100, 4904, 3906,
3121, 2501, 1991, 1586, 1277,
1024, 820, 655, 526, 423,
335, 272, 215, 172, 137,
110, 87, 70, 56, 45,
36, 29, 23, 18, 15,
};
現(xiàn)在,各個(gè)進(jìn)程按照自己優(yōu)先級(jí)對(duì)應(yīng)的權(quán)重,來從這100ms的調(diào)度周期里來分配時(shí)間。
不知道你發(fā)現(xiàn)沒有,如果進(jìn)程特別多,那可能分下來的時(shí)間就會(huì)很少。咱們還得設(shè)定一個(gè)最小值,不然一天天的凈跑去調(diào)度切換了,真正執(zhí)行的時(shí)間少了。
這個(gè)最小值,就是進(jìn)程至少得運(yùn)行這么久才能切換。
9. 公平調(diào)度:進(jìn)程選擇
時(shí)間分配的問題解決了,還有一個(gè)問題:調(diào)度的時(shí)候,如何挑選下一個(gè)需要執(zhí)行的進(jìn)程呢?
前面我們按照權(quán)重來給大家分配了時(shí)間,但肯定有一些進(jìn)程,因?yàn)镮/O、鎖、睡眠等原因沒有把分配的時(shí)間用完,這一些進(jìn)程應(yīng)該得到補(bǔ)償,一旦它們符合執(zhí)行條件后,應(yīng)該優(yōu)先被執(zhí)行。
主動(dòng)放棄了CPU的進(jìn)程,它們運(yùn)行的時(shí)間肯定比分配的短。要不,按照進(jìn)程運(yùn)行的時(shí)間來排個(gè)序,挑選時(shí)間最短的進(jìn)程來運(yùn)行?
但是,不同進(jìn)程優(yōu)先級(jí)不一樣,分配到的時(shí)間本來就有長(zhǎng)短啊。
要是能夠消除因?yàn)闄?quán)重造成的時(shí)間分配長(zhǎng)短不一問題就好了,就能用運(yùn)行時(shí)間來排序了。
要不咱們?cè)倥粋€(gè)虛擬運(yùn)行時(shí)間,把權(quán)重帶來的影響再給修復(fù)回去?
比如優(yōu)先級(jí)高的進(jìn)程,分配的時(shí)間多,統(tǒng)計(jì)它的運(yùn)行時(shí)間的時(shí)候,就讓它流逝的慢一些。
而優(yōu)先級(jí)低的進(jìn)程,分配的時(shí)間少,統(tǒng)計(jì)它的運(yùn)行時(shí)間的時(shí)候,就讓它流逝的快一些。
這樣所有進(jìn)程在沒有任何睡眠、等待、I/O的情況下,大家都是用完了自己的時(shí)間,消除權(quán)重后的虛擬時(shí)間都應(yīng)該是一樣一樣的,都是整個(gè)調(diào)度周期的1/N!
這才叫公平嘛!

現(xiàn)在只需要把所有進(jìn)程按照虛擬時(shí)間來排個(gè)序,排在前面的虛擬時(shí)間短,調(diào)度的時(shí)候就選擇它來運(yùn)行。
好主意,那用什么樣的數(shù)據(jù)結(jié)構(gòu)來組織管理進(jìn)程呢?
數(shù)組?插入不方便。
鏈表?尋找插入位置的時(shí)候時(shí)間復(fù)雜度是O(N)。
用二叉搜索樹貌似是個(gè)不錯(cuò)的方案。左節(jié)點(diǎn)虛擬時(shí)間比父節(jié)點(diǎn)和右節(jié)點(diǎn)的虛擬時(shí)間小,只要找到最左邊的節(jié)點(diǎn)就是要調(diào)用的進(jìn)程,時(shí)間復(fù)雜度是O(LogN)。
但二叉搜索樹有個(gè)毛病,一個(gè)不小心就容易變成一棵“跛腳”的樹,這時(shí)間復(fù)雜度就又上去了。
紅黑樹沒有這個(gè)問題,它自帶平衡性,要不就它吧!
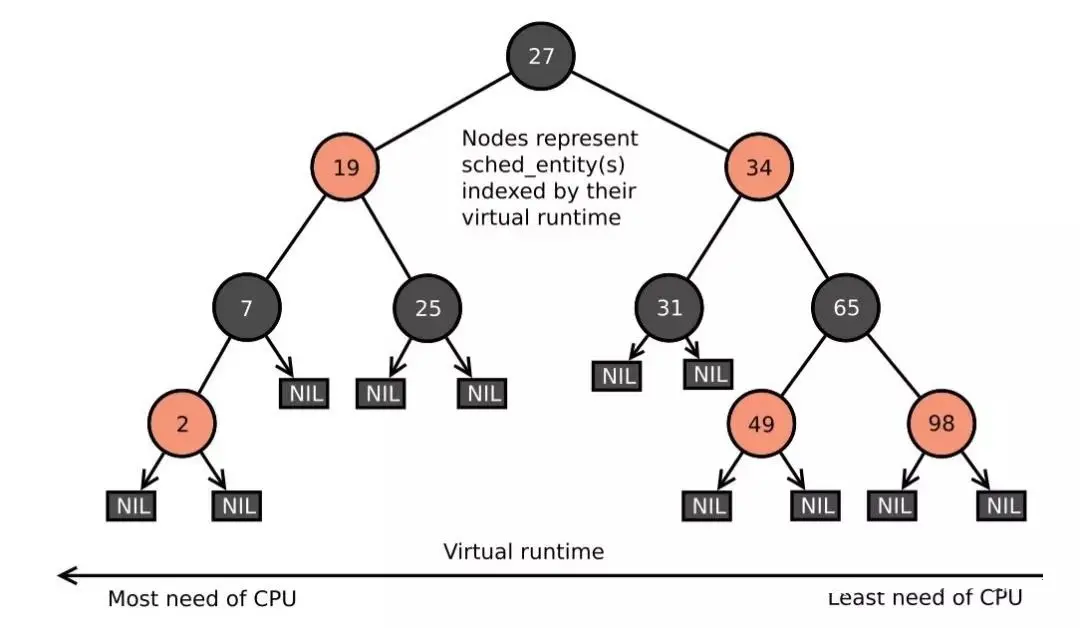
根據(jù)虛擬時(shí)間來把所有待運(yùn)行的進(jìn)程組織成一棵紅黑樹,只要找到整棵樹最左邊的節(jié)點(diǎn),就是要運(yùn)行的進(jìn)程。
不過為了更高效,樹調(diào)整更新導(dǎo)致最左邊節(jié)點(diǎn)發(fā)生變化的時(shí)候,把它給緩存起來,這樣調(diào)度的時(shí)候就直接拿到這個(gè)緩存節(jié)點(diǎn)就好了。
完美!
總結(jié)
上面講述的進(jìn)程調(diào)度模型其實(shí)就是Linux中O(1)調(diào)度算法和CFS(完全公平調(diào)度算法)調(diào)度算法的雛形,為了便于理解,文中進(jìn)行了一定程度的簡(jiǎn)化。包括但不限于:
- 在實(shí)際的Linux中,進(jìn)程優(yōu)先級(jí)有140個(gè),分為實(shí)時(shí)進(jìn)程和非實(shí)時(shí)進(jìn)程。
- 在實(shí)際的Linux中,進(jìn)程通過一個(gè)叫nice值(對(duì)其他進(jìn)程的友好度,nice越大,越友好,越謙讓,優(yōu)先級(jí)越低)的東西映射到優(yōu)先級(jí),優(yōu)先級(jí)數(shù)字越大,優(yōu)先級(jí)反而越低。
- 在實(shí)際的Linux中,進(jìn)程的優(yōu)先級(jí)分為靜態(tài)和動(dòng)態(tài),是會(huì)隨著運(yùn)行而變化的,不是固定不變。
- 在多核模式下,為了防止加鎖帶來的性能損失,每一個(gè)CPU核都有自己的調(diào)度隊(duì)列。
- 在實(shí)際的Linux中,參與調(diào)度的是線程,而不是進(jìn)程。但在早期的Linux中,沒有線程的概念,調(diào)度就是基于進(jìn)程來進(jìn)行,引入線程后,線程又稱為輕量級(jí)進(jìn)程。現(xiàn)在我們平時(shí)所說的進(jìn)程和線程在語義上有所不同,這一點(diǎn)要注意區(qū)別。
看完了這篇文章,再去看Linux的調(diào)度算法,應(yīng)該會(huì)輕松不少。