服務容錯:服務雪崩與容錯方案
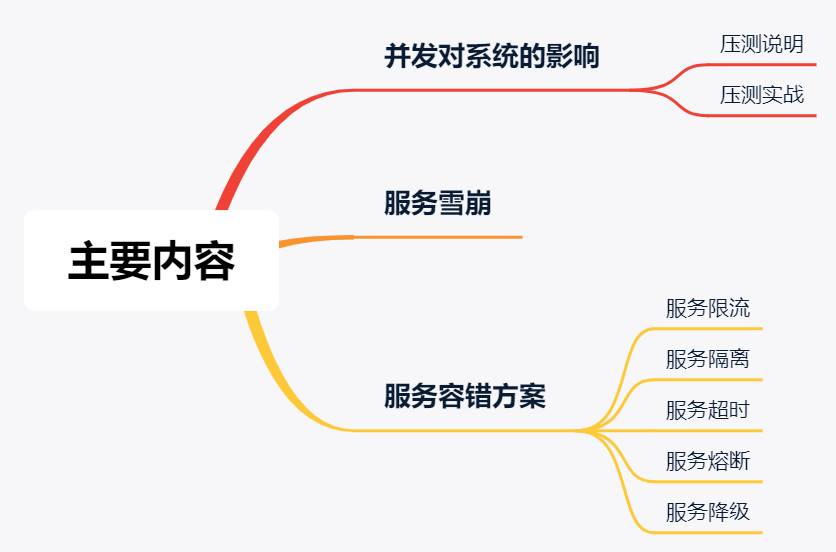
并發對系統的影響
當一個系統的架構設計采用微服務架構模式時,會將龐大而復雜的業務拆分成一個個小的微服務,各個微服務之間以接口或者RPC的形式進行互相調用。在調用的過程中,就會涉及到網路的問題,再加上微服務自身的原因,例如很難做到100%的高可用等。
如果眾多微服務當中的某個或某些微服務出現問題,不可用或者宕機了,那么其他微服務調用這些微服務的接口時就會出現延遲。如果此時有大量請求進入系統,就會造成請求任務的大量堆積,甚至會造成整體服務的癱瘓。
壓測說明
為了更加直觀的說明當系統沒有容錯能力時,高并發、大流量場景對于系統的影響,我們在這里模擬一個并發的場景。在訂單微服務shop-order的io.binghe.shop.order.controller.OrderController類中新增一個concurrentRequest()方法,源碼如下所示。
@GetMapping(value = "/concurrent_request")
public String concurrentRequest(){
log.info("測試業務在高并發場景下是否存在問題");
return "binghe";
}
接下來,為了更好的演示效果,我們限制下Tomcat處理請求的最大并發數,在訂單微服務shop-order的resources目錄下的application.yml文件中添加如下配置。
server:
port: 8080
tomcat:
max-threads: 20
限制Tomcat一次最多只能處理20個請求。接下來,我們就使用JMeter對 http://localhost:8080/order/submit_order 接口進行壓測,由于訂單微服務中沒有做任何的容錯處理,當對 http://localhost:8080/order/submit_order 接口的請求壓力過大時,我們再訪問http://localhost:8080/order/concurrent_request 接口時,會發現http://localhost:8080/order/concurrent_request 接口會受到并發請求的影響,訪問很慢甚至根本訪問不到。
壓測實戰
使用JMeter對 http://localhost:8080/order/submit_order 接口進行壓測,JMeter的配置過程如下所示。
(1)打開JMeter的主界面,如下所示。
(2)在JMeter中右鍵測試計劃添加線程組,如下所示。
(3)在JMeter中的線程組中配置并發線程數,如下所示。
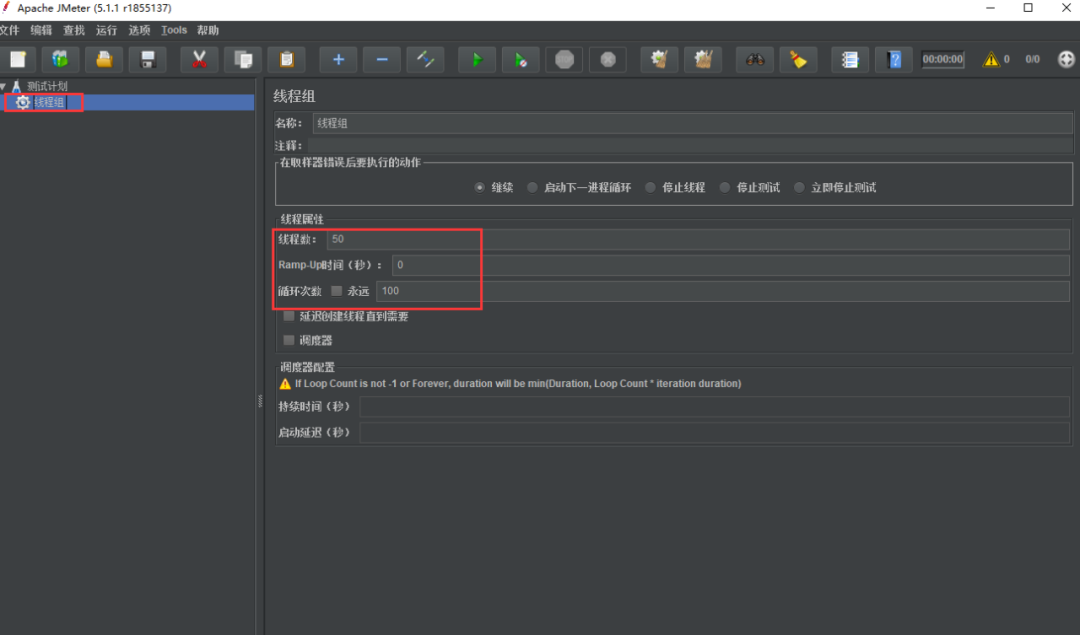
如上圖所示,將線程數配置成50,Ramp-Up時間配置成0,循環次數為100。表示JMeter每次會在同一時刻向系統發送50個請求,發送100次為止。
(4)在JMeter中右鍵線程組添加HTTP請求,如下所示。
(5)在JMeter中配置HTTP請求,如下所示。
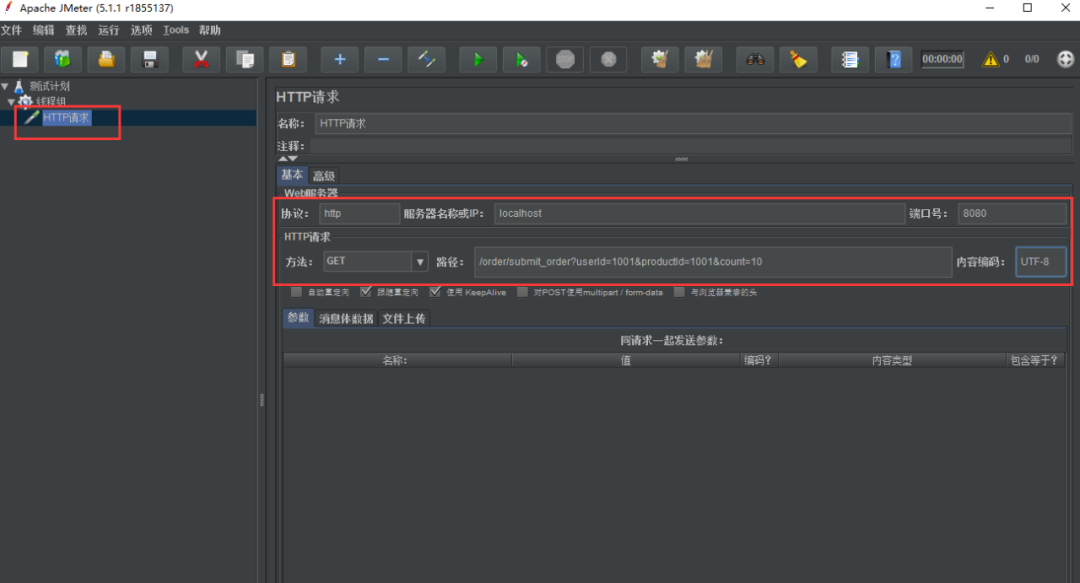
具體配置如下所示。
- 協議:http
- 服務器名稱或IP:localhost
- 端口號:8080
- 方法:GET
- 路徑:/order/submit_order?userId=1001&productId=1001&count=1
- 內容編碼:UTF-8
(6)配置好JMeter后,點擊JMeter上的綠色小三角開始壓測,如下所示。
點擊后會彈出需要保存JMeter腳本的彈出框,根據實際需要點擊保存即可。
點擊保存后,開始對 http://localhost:8080/order/submit_order 接口進行壓測,在壓測的過程中會發現訂單微服務打印日志時,會比較卡頓,同時在瀏覽器或其他工具中訪問http://localhost:8080/order/concurrent_request 接口會卡頓,甚至根本訪問不到。
說明訂單微服務中的某個接口一旦訪問的并發量過高,其他接口也會受到影響,進而導致訂單微服務整體不可用。為了說明這個問題,我們再來看看服務雪崩是個什么鬼。
服務雪崩
系統采用分布式或微服務的架構模式后,由于網絡或者服務自身的問題,一般服務是很難做到100%高可用的。如果一個服務出現問題,就可能會導致其他的服務級聯出現問題,這種故障性問題會在整個系統中不斷擴散,進而導致服務不可用,甚至宕機,最終會對整個系統造成災難性后果。
為了最大程度的預防服務雪崩,組成整體系統的各個微服務需要支持服務容錯的功能。
服務容錯方案
服務容錯在一定程度上就是盡最大努力來兼容錯誤情況的發生,因為在分布式和微服務環境中,不可避免的會出現一些異常情況,我們在設計分布式和微服務系統時,就要考慮到這些異常情況的發生,使得系統具備服務容錯能力。
常見的服務錯誤方案包含:服務限流、服務隔離、服務超時、服務熔斷和服務降級等。
服務限流
服務限流就是限制進入系統的流量,以防止進入系統的流量過大而壓垮系統。其主要的作用就是保護服務節點或者集群后面的數據節點,防止瞬時流量過大使服務和數據崩潰(如前端緩存大量實效),造成不可用;還可用于平滑請求。
限流算法有兩種,一種就是簡單的請求總量計數,一種就是時間窗口限流(一般為1s),如令牌桶算法和漏牌桶算法就是時間窗口的限流算法。
服務隔離
服務隔離有點類似于系統的垂直拆分,就按照一定的規則將系統劃分成多個服務模塊,并且每個服務模塊之間是互相獨立的,不會存在強依賴的關系。如果某個拆分后的服務發生故障后,能夠將故障產生的影響限制在某個具體的服務內,不會向其他服務擴散,自然也就不會對整體服務產生致命的影響。
互聯網行業常用的服務隔離方式有:線程池隔離和信號量隔離。
服務超時
整個系統采用分布式和微服務架構后,系統被拆分成一個個小服務,就會存在服務與服務之間互相調用的現象,從而形成一個個調用鏈。形成調用鏈關系的兩個服務中,主動調用其他服務接口的服務處于調用鏈的上游,提供接口供其他服務調用的服務處于調用鏈的下游。
服務超時就是在上游服務調用下游服務時,設置一個最大響應時間,如果超過這個最大響應時間下游服務還未返回結果,則斷開上游服務與下游服務之間的請求連接,釋放資源。
服務熔斷
在分布式與微服務系統中,如果下游服務因為訪問壓力過大導致響應很慢或者一直調用失敗時,上游服務為了保證系統的整體可用性,會暫時斷開與下游服務的調用連接。這種方式就是熔斷。
服務熔斷一般情況下會有三種狀態:關閉、開啟和半熔斷。
- 關閉狀態:服務一切正常,沒有故障時,上游服務調用下游服務時,不會有任何限制。
- 開啟狀態:上游服務不再調用下游服務的接口,會直接返回上游服務中預定的方法。
- 半熔斷狀態:處于開啟狀態時,上游服務會根據一定的規則,嘗試恢復對下游服務的調用。此時,上游服務會以有限的流量來調用下游服務,同時,會監控調用的成功率。如果成功率達到預期,則進入關閉狀態。如果未達到預期,會重新進入開啟狀態。
服務降級
服務降級,說白了就是一種服務托底方案,如果服務無法完成正常的調用流程,就使用默認的托底方案來返回數據。例如,在商品詳情頁一般都會展示商品的介紹信息,一旦商品詳情頁系統出現故障無法調用時,會直接獲取緩存中的商品介紹信息返回給前端頁面。