













MNN 引擎的稀疏計算方案設計與實踐
推理引擎領域,經(jīng)過最近幾年的打磨優(yōu)化,阿里推出的MNN(Mobile Neural Network) [1][2][3] 也成為業(yè)內(nèi)領先的推理引擎,當我們想進一步提升性能時,結合深度學習模型設計入手是一個有潛力的方向,結合科學計算、高性能計算領域的知識則是一個更具體的方法,基于這個思考路徑, 業(yè)內(nèi)逐漸開始從稀疏計算角度來提升推理引擎性能。稀疏是指數(shù)據(jù)矩陣中有部分是0元素,一般而言,矩陣稀疏化之后,非0元素數(shù)據(jù)在內(nèi)存中不連續(xù),無法直接復用GEMM(general matrix multiply) [9] 算法,同時緩存命中問題或判斷開銷會降低稀疏計算性能,需要新的方法實現(xiàn)稀疏相對稠密計算的加速。
結合業(yè)內(nèi)已有的稀疏計算方法與MNN的推理框架、內(nèi)存布局、算子關系,我們在MNN框架中設計支撐多類后端的稀疏整體方案,打磨稀疏計算核心匯編實現(xiàn)達到高性能;重要性能指標數(shù)據(jù)如下:以AI(Artificial Intelligence)領域經(jīng)典的分類模型MobileNetV1 [12] MobileNetV2 [13] 為例, 選取相同高通SD 835 CPU(MSM8998),與XNNPack [6] 相比,MobileNetV1 90%稀疏度時XNNPack 加速比為2.35x,MNN加速比為 2.57x - 3.96x。MobileNetV2 85% 稀疏度時, XNNPack MobileNetV2(只有 block=2),加速比為1.62x,MNN加速比為 3.71x(block=4),block含義與其他模型信息見1.1、 3.1節(jié)解讀,其他信息在后續(xù)展開。
1. 稀疏布局與加速原理
1.1 可調(diào)分塊稀疏權重
深度神經(jīng)網(wǎng)絡模型的稀疏計算包括輸入稀疏 [11] 、輸出稀疏、權重稀疏,0元素占全部元素的比例就是稀疏度,通常而言輸入和輸出稀疏對具備特定屬性模型會有效果,例如激活函數(shù)為ReLU,計算出負數(shù)值會被歸零,所以可以不精確計算出這些結果,只計算符號實現(xiàn)加速。而在CPU對通用DNN模型具備加速效果的是權重稀疏,在MNN中我們聚焦權重稀疏這個通用場景,另一個重要特點是面向深度學習的權重稀疏比例一般在30%-90%,有別于科學計算中極度稀疏到99%的場景。即以下三點:
MNN稀疏計算的基本選型:
- 左右矩陣方面:選擇通用權重稀疏;
- 稀疏度方面: 在30%-90%左右需產(chǎn)生加速效果,非科學計算的極度稀疏場景;
- 結構方面:不采用裁剪權重矩陣通道維度的完全結構化剪枝方法,而是隨機稀疏+分塊稀疏。
常規(guī)結構化剪枝中 [4][5] ,直接刪減權重矩陣的IC或OC維度的整個維度切片,裁剪后模型仍然是稠密的,直接縮減矩陣乘法規(guī)模,由于對宏觀結構改變較大,導致模型精度損失顯著。
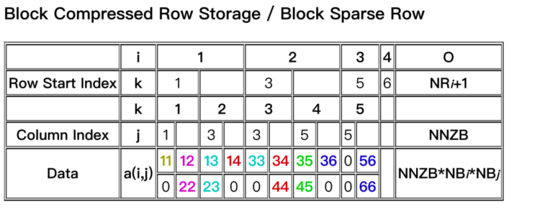
MNN中的稀疏計算選擇對權重在OC維度做動態(tài)分塊稀疏,下圖1為隨機稀疏分塊下矩陣乘法的左右矩陣數(shù)據(jù)布局,涂色方格表示數(shù)據(jù)非0, 白色方格表示稀疏化處理后為0,即可不存儲,又可不計算。
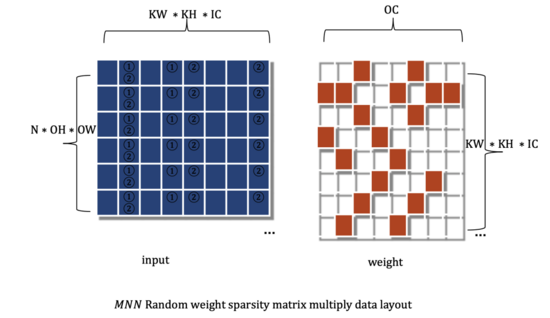
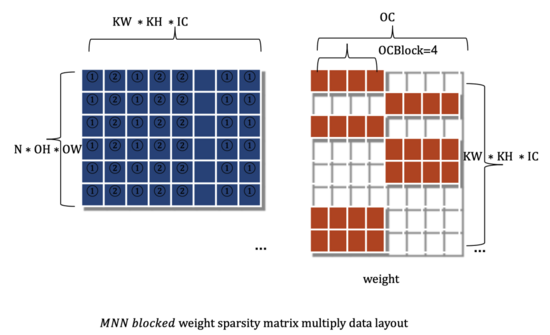
下圖2為分塊稀疏的矩陣乘法的左右矩陣數(shù)據(jù)布局,左矩陣與隨機稀疏情形相同, 右矩陣為權重矩陣,以每OCBlock為單位,連續(xù)為0或非0分布于內(nèi)存中。為了靈活性考慮,我們設計支持OCBlock為可調(diào)數(shù)值。
1.2 權重矩陣數(shù)據(jù)壓縮格式
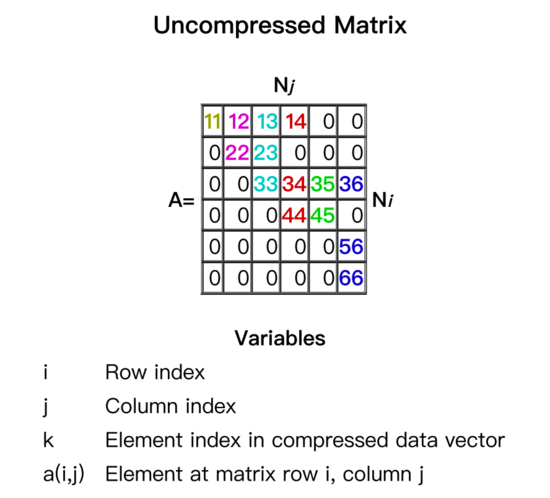
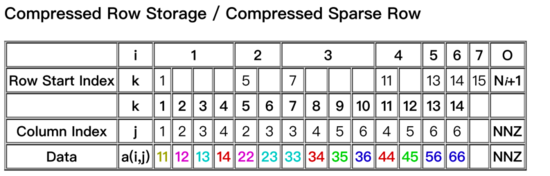
經(jīng)過對比選型,在MNN中權重矩陣采用了多種布局形式,原始權重如圖3所示,為了保障性能的同時壓縮內(nèi)存占用。性能隨機稀疏時,選用圖4所示的布局樣式;分塊稀疏時,選用圖5布局。原始矩陣壓縮為非0數(shù)據(jù)與索引部分。下圖4、5中,權重矩陣A的0元素被壓縮后不再存儲,data為非0數(shù)據(jù),Row start Index 與Column Index為行索引與列索引。圖5的布局時,可以節(jié)省更多索引空間,壓縮內(nèi)存占用。
2. MNN稀疏計算方案設計
2.1 推理框架層設計
在MNN已有架構基礎上的設計稀疏計算,則設計與實現(xiàn)需要考慮較多現(xiàn)狀的約束,結合基礎軟件的定位,設計目標主要包括以下5個方面。
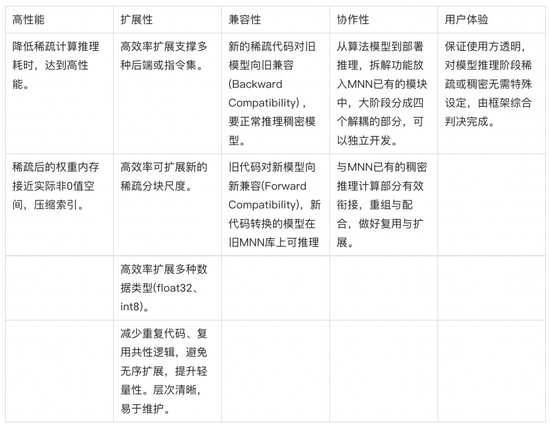
說明:由于漢語時序的”前后“和英語”forward/backward”語義相反,故用了向舊兼容代替通常說的有歧義的"向前兼容"。
2.2 MNN稀疏計算架構解析
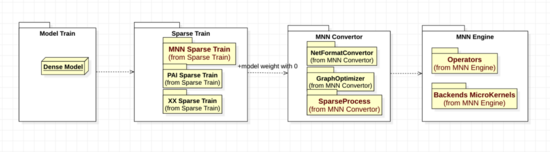
經(jīng)過不斷設計與完善,MNN稀疏計算目前整體上包含稀疏訓練、轉換參數(shù)、算子框架、后端kernel 四個階段,設計四部分松耦合;方便層內(nèi)擴展,以及模塊化集成與被集成,如下圖package UML所示。為了便于理解,參考C4Model建模方法分層,圖6為container層架構、圖7為具體一層的Component層架構。
- 第一,屬于算法模型階段, 算法工程師結合數(shù)據(jù)搭建模型,根據(jù)自身偏好在各類框架下訓練得到AI模型;
- 第二,稀疏化訓練階段,參考圖6,從float稠密權重模型開始,導入MNN Python壓縮工具包(mnncompress),設定mnncompress需要的參數(shù),運行將原模型中權重部分數(shù)值稀疏化為0。我們建議用戶使用MNNCompress工具里的訓練插件,最大化發(fā)揮加速性能;
- 第三,轉換模型階段,MNN convertor 主要包含三類模塊,MNN內(nèi)部buffer格式轉換、圖優(yōu)化、后處理,選擇算子,將權重矩陣統(tǒng)計處理,滿足稀疏閾值的,給添加稀疏后端識別和運行需要的參數(shù),最終寫文件得到稀疏MNN模型;
- 第四,MNN engine推理計算階段,部署新模型到MNN運行環(huán)境中,和普通模型運行一樣,MNN 運行時會自行處理算子映射、后端microkernel選擇、執(zhí)行推理。參考一般模型部署運行文檔。(https://www.yuque.com/mnn/cn/create_session)
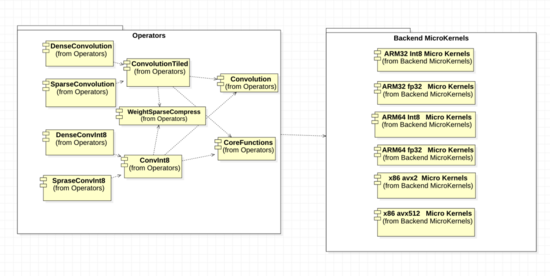
在 MNN Engine中,參考圖7, 算子operators和后端backend做如下結構設計與考量。
- 外部看來,算子注冊并未新增一種“稀疏卷積”算子,仍然是普通的卷積算子,這樣可以減小用戶使用的選擇成本,減少算子膨脹,在MNN內(nèi)部更靈活地選擇稀疏計算加速,或原始稠密卷積。
- 算子層面,將原始的稠密卷積重組成兩層,合理分配可復用與需要擴展的部分,實現(xiàn)稀疏計算壓縮各類操作。
- 量化稀疏算子則基于量化卷積算子ConvInt8Tiled擴充實現(xiàn),基本方法與2相近。
- 算子中平臺有關的核心函數(shù),我們分別實現(xiàn)了ARM32 fp32,ARM32 int8, ARM64 fp32, ARM64 int8, x86 avx2 fp32, x86 avx512 fp32共6種后端的匯編代碼。
- 測試類方面,稀疏的用例完全包含稠密卷積的用例,并增加稀疏分塊維度,遍歷不同分塊、不同稀疏度、不同后端的正確性。
3. 稀疏計算性能評估
3.1 典型模型稀疏加速評估
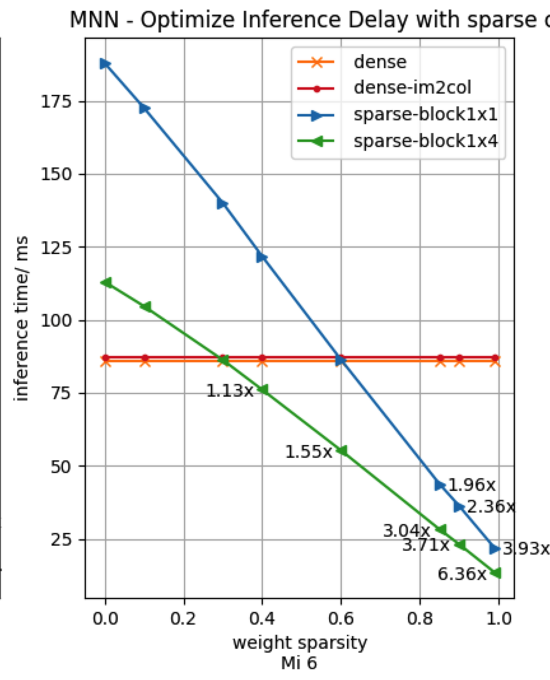
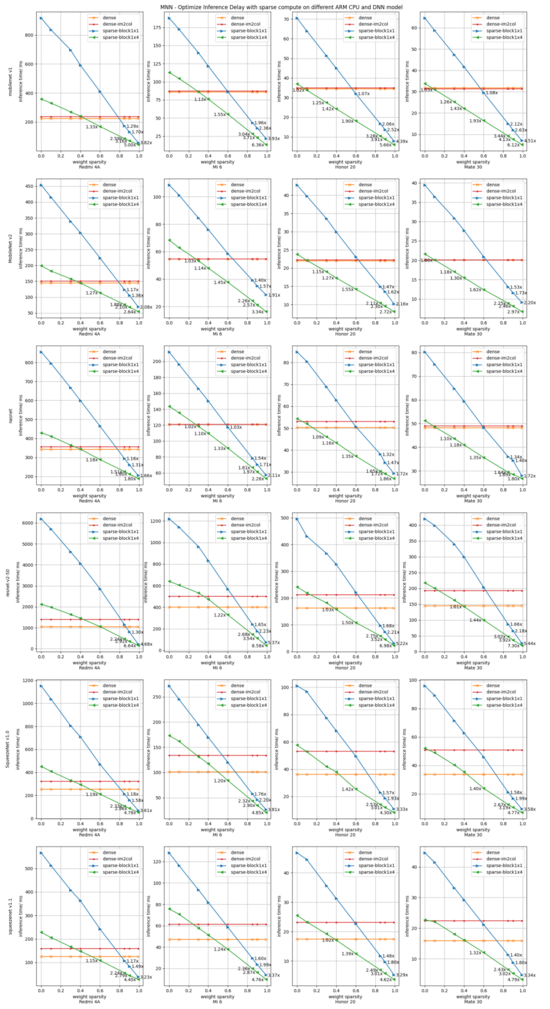
為全面評估fp32稀疏加速效果,我們從"稀疏度、分塊大小、cpu型號、模型類型"四個維度進行評測,匯集在圖8展示結果, 單張曲線圖表示固定一個設備、一個模型時,推理耗時隨稀疏度的變化曲線。
將大圖的第1行第2列取出單列置于上方,便于解讀數(shù)據(jù)。單張曲線圖包含四條曲線,"dense"為MNN當前基準, "dense-im2col"為將推理算法固定為分塊im2col做加速的數(shù)據(jù),不使用winograd之類加速算法, "sparse-block1x1"表示對權重矩陣的稀疏為1x1分塊,也就是完全隨機稀疏。 "sparse-block1x4"是半結構化稀疏,表示對權重矩陣的稀疏分塊為1x4分塊,沿著ic維度分塊為1, 沿著oc維度分塊為4。
從小圖可見在mobilenet V1、Mi6 機型、1x4分塊時,對應綠色左三角?曲線,稀疏加速比在0.9稀疏度是達到3.71x。
參考對比XNNPack模型推理性能:
XNNPack [6] 數(shù)據(jù)評測采用高通SD 835 CPU(MSM8998),mobilenetV1 為90%稀疏度,對mobilenetV2 為85% 稀疏度,
對應SD 835 CPU,我們以小米6為例,下圖第1行第2列,為例對比數(shù)據(jù):
XNNPack mobilenetV1(sparsity=0.9, block=1),加速比為2.35x,MNN加速比為 2.57x , 分塊為1x4時加速比3.96x.
XNNPack mobilenetV2(sparsity=0.85, block=2),加速比為1.62x,MNN加速比為 3.71x(block=4).
對于卷積kernel不是1x1的層,我們?nèi)钥梢詫崿F(xiàn)稀疏加速,在XNNPack的論文中表明他們并未能實現(xiàn)稀疏加速。
通過數(shù)據(jù)大圖8,我們可得到幾點分析和結論:
- 參照設備小米6上, 在稀疏分塊1x4時,稀疏加速臨界值優(yōu)化到0.3, 低端機型臨界值有升高,其他中高端機型, 分塊1x4時, 稀疏度0.1的時候就達到加速臨界值了, 0.9稀疏度時加速比可達4.13x。
- MNN推理耗時隨稀疏度增加,基本線性下降,跨模型、cpu 一致性比較好。
- 內(nèi)存占用:經(jīng)過推導, 稀疏相對稠密節(jié)省的內(nèi)存比例如下,
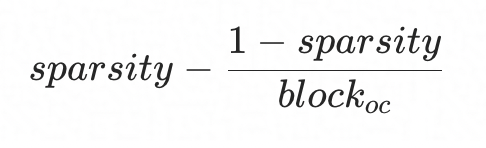
另一方面,我們評估了典型模型的分類精度,MobileNet V2在0.5稀疏度、1x4稀疏分塊配置下,精度損失0.6%,對應上圖加速比為1.3x。

4. 業(yè)務模型實踐
4.1 某圖片超分業(yè)務
在某業(yè)務移動端鏈路上,時間延遲與流量是其痛點,業(yè)務方對接端智能 MNN與工作臺,開發(fā)超分辨率任務模型,同時使用MNN稀疏計算加速方案,主要做了四個步驟,
- 第一步為超分模型算法訓練;
- 第二步,參考稀疏訓練文檔,設定壓縮工具mnncompress需要的稀疏參數(shù),得到權重部分數(shù)稀疏為0的模型;
- 第三步,使用MNN convertor轉換模型;
- 運用MNN工作臺(https://www.mnn.zone/m/0.3/) ,部署模型到mnn運行環(huán)境中。整套流程集成再MNN工作臺,大大提升了AI的開發(fā)流程效率,感興趣的同學可以試用和聯(lián)系工作臺負責人”明弈“。
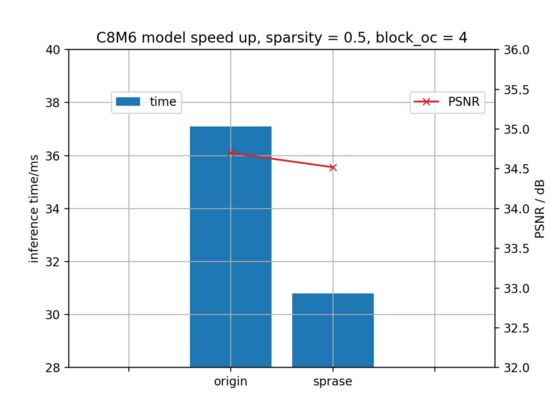
下圖所示,在稀疏度0.45情況下,稀疏自身方案對推理的加速比約1.2x, 業(yè)務指標為圖像信噪比,從 34.728dB少量下降到34.502dB。對業(yè)務精度影響在接受范圍內(nèi)。
4.2 某語音模型
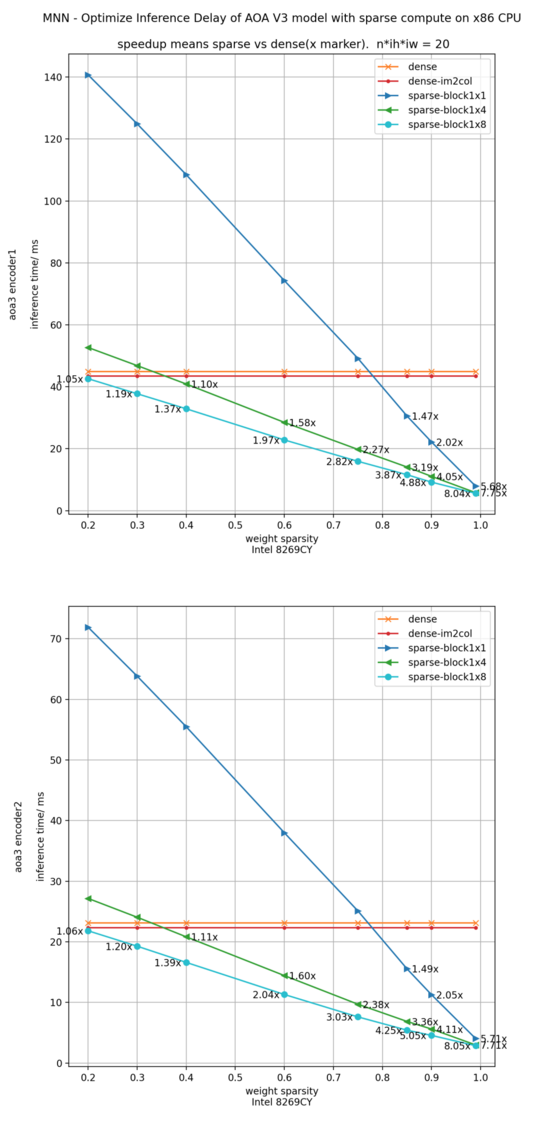
另一個業(yè)務方模型為某語音模型,下圖為構造稀疏后在avx512下實測加速比,不同稀疏方法對加速會有影響,0.75稀疏度時,輸入序列20時(典型場景1),下圖所示,稀疏與稠密模型相比,encoder1加速比 2.82x, encoder2加速比3.02x。對于此方案達到預期的加速比。
5. 總結與展望
我們在MNN現(xiàn)有框架中,設計了通用稀疏卷積計算方案,使其數(shù)據(jù)布局、算子結構配合既有MNN結構、發(fā)揮出較高性能,而XNNPack的稀疏矩陣乘法只針對網(wǎng)絡pointwise類卷積有加速。
第一點,我們設計實現(xiàn)了推理性能優(yōu)于XNNPack的MNN稀疏加速方案;0.9稀疏度時,CV模型在ARM端獲得3.16x-4.13x加速比,跨機型、跨模型加速效果都比較顯著。
第二點,在實際業(yè)務模型中驗證了業(yè)務精度指標,損失有限、可接受。
第三點,推理耗時隨稀疏度增加線性下降,跨模型、cpu 一致;在小米6上,稀疏分塊1x4加速臨界值優(yōu)化到0.3,中高端機型甚至稀疏度0.1的時候可達臨界值。
第四點,降低內(nèi)存占用隨稀疏度成正比,具體數(shù)值見性能分析部分。
在引擎實現(xiàn)、稀疏計算內(nèi)核、匯編代碼開發(fā)中,經(jīng)常會從不及預想值開始,在一次次調(diào)試中不斷加深對MNN既有邏輯的理解,優(yōu)化稀疏算子代碼、SIMD代碼,優(yōu)化數(shù)據(jù)布局,最終將綜合指標提升到高水準。
稀疏計算研發(fā)工作得以完成,非常感謝團隊的同學通力協(xié)作!移動端或服務端,量化加速在不同領域都相對常見,指令集支持由來已久。而深度模型在CPU上的稀疏計算加速不斷發(fā)展,分別使用時,二者各有相對優(yōu)勢。稀疏計算加速可以理解為一種 "可伸縮"等效位寬的技術,這個角度可以探索更多獨特的應用場景。



















