如何批量給PDF添加水印?

我們有時候需要把一些機密文件發給多個客戶,為了避免客戶泄露文件,會在機密文件中添加水印。每個客戶收到的文件內容相同,但是水印都不相同。這樣一來,如果資料泄露了,通過水印就知道是從誰手上泄露的。
今天,一個做市場的朋友找我咨詢PDF加水印的問題,如下圖所示:
他有一個Excel文件,文件里面有10000個經銷商的名字,他要把價目表PDF發給這些經銷商,每個經銷商收到的PDF文件上面的水印都是這個經銷商自己的名字。
這個需求手動操作肯定要累死人。但是如果用Python來做,就非常簡單。代碼不超過30行。
準備環境
要完成這個需求,需要安裝兩個模塊,分別叫做reportlab和pikepdf。使用Pip安裝就可以了:
python3 -m pip install reportlab pikepdf
然后,需要找到一個.ttf或者.ttc格式的中文字體。你可以直接從網上下載中文字體文件。也可以使用系統自帶的中文字體。這里以尋找macOS系統默認的宋體為例。
macOS系統字體在/System/Library/Fonts,宋體對應的.ttc文件地址是/System/Library/Fonts/Supplemental/Songti.ttc。對于系統默認的字體,我們只需要知道它的對應的文件名叫做Songti.ttc就可以了。如果是從網上下載的第三方字體,需要使用絕對路徑或者相對于項目代碼的相對路徑。
獲得經銷商名字對應的列表
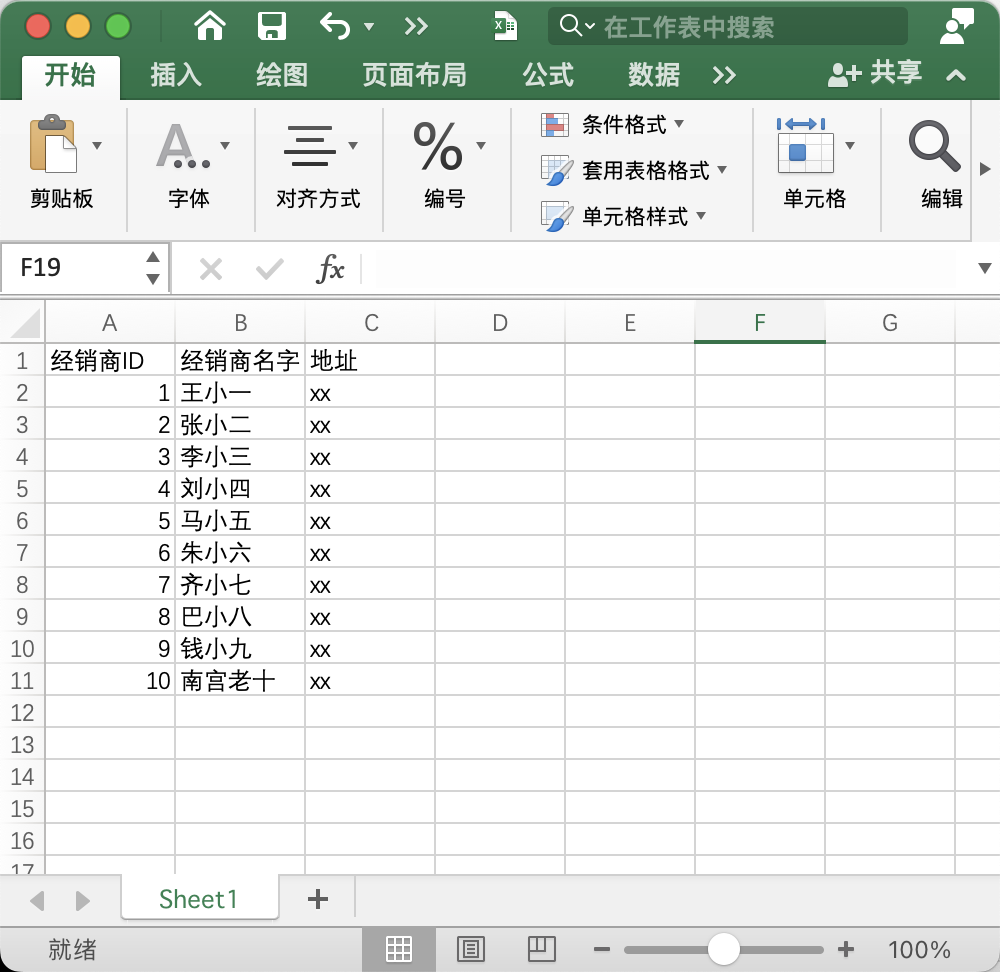
由于這位朋友不會使用pandas,那么我們就盡量使用Python原生的方法來獲得經銷商名字列表。假設經銷商信息對應的Excel如下圖所示:
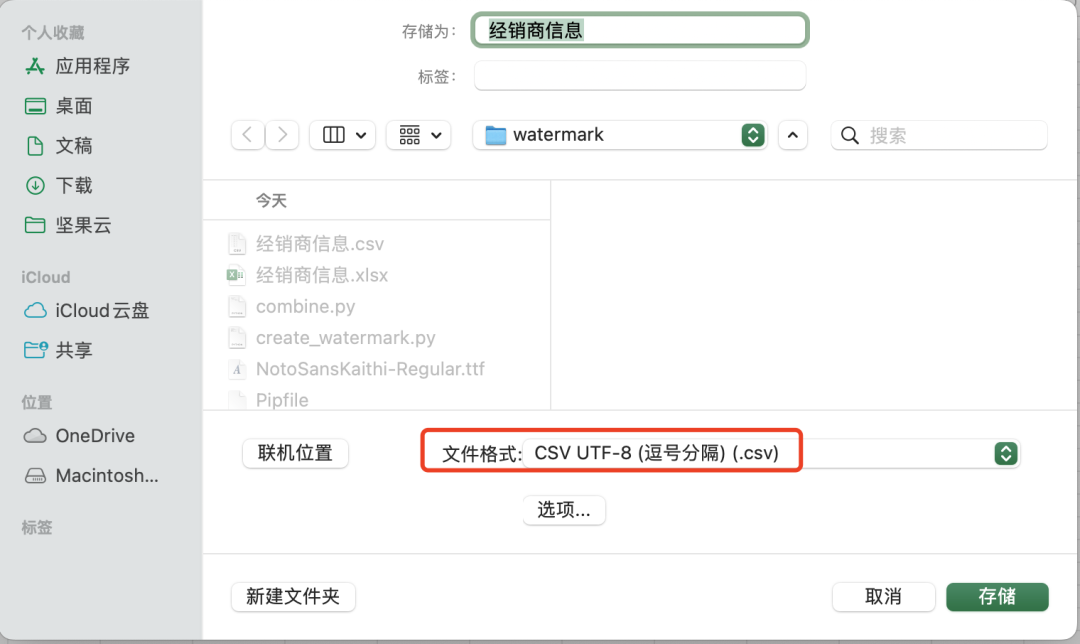
我們首先把這個Excel文件導出成csv文件:
然后,我們用Python讀取這個csv文件,獲得經銷商名字列表:
import csv
with open('經銷商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['經銷商名字'] for x in reader]
print(name_list)
運行效果如下圖所示:

生成水印PDF
一般來說,我們不能直接把一段文字作為水印添加到另一個PDF文件中。我們只有先把這段文字生成圖片或者生成水印PDF文件,然后把這個圖片或者水印PDF作為『圖層』覆蓋到目標PDF上面。
因此,現在需要給每一個經銷商生成對應的水印PDF文件。這個PDF中只含有水印文字。效果如下圖所示:
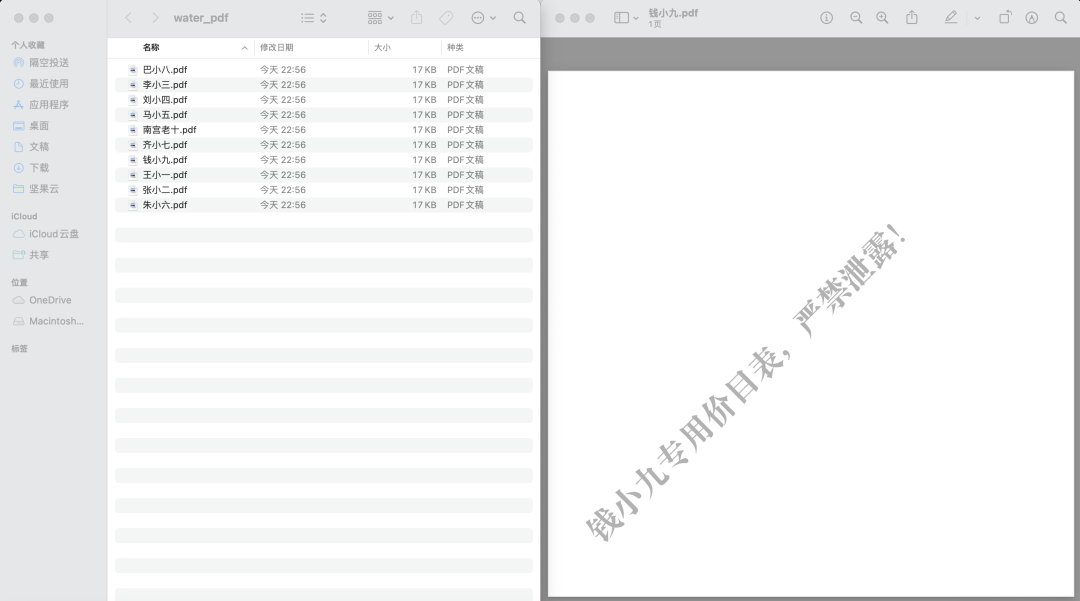
對應的代碼create_watermark.py如下:
import csv
from pathlib import Path
from reportlab.lib import units
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
with open('經銷商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['經銷商名字'] for x in reader]
pdfmetrics.registerFont(TTFont('Songti', 'Songti.ttc')) # 加載中文字體
water_mark_folder = Path('water_pdf') # 用一個文件夾存放所有的水印PDF
water_mark_folder.mkdir(exist_ok=True)
for name in name_list:
path = str(water_mark_folder / Path(f'{name}.pdf'))
c = canvas.Canvas(path, pagesize=(200 * units.mm, 200 * units.mm)) # 生成畫布,長寬都是200毫米
c.translate(0.1 * 200 * units.mm, 0.1 * 200 * units.mm)
c.rotate(45) # 把水印文字旋轉45°
c.setFont('Songti', 35) # 字體大小
c.setStrokeColorRGB(0, 0, 0) # 設置字體顏色
c.setFillColorRGB(0, 0, 0) # 設置填充顏色
c.setFillAlpha(0.3) # 設置透明度,越小越透明
c.drawString(0, 0, f'{name}專用價目表,嚴禁泄露!')
c.save()
代碼的具體作用,已經寫到注釋中了。運行以后會在當前項目根目錄生成water_pdf文件夾,里面就是生成的水印PDF。
合并水印與目標PDF
最后一步,把每一個經銷商的水印PDF與目標PDF進行合并。水印PDF作為一個圖層覆蓋到目標PDF上面。
使用pikepdf完成這個工作非常簡單,編寫一個combine.py文件,代碼如下:
import glob
from pathlib import Path
from pikepdf import Pdf, Page, Rectangle
water_pdf_list = glob.glob('water_pdf/*.pdf')
result = Path('result')
result.mkdir(exist_ok=True)
col = 2 # 每頁多少列水印
row = 3 # 每頁多少行水印
for path in water_pdf_list:
target = Pdf.open('./PythonisinstanceGolang.pdf') # 必須每次重新打開PDF,因為添加水印是inplace的操作
file = Path(path)
name = file.stem
water_mark_pdf = Pdf.open(path)
water_mark = water_mark_pdf.pages[0]
for page in target.pages:
for x in range(col): # 每一行顯示多少列水印
for y in range(row): # 每一頁顯示多少行PDF
page.add_overlay(water_mark,
Rectangle(page.trimbox[2] * x / col,
page.trimbox[3] * y / row,
page.trimbox[2] * (x + 1) / col,
page.trimbox[3] * (y + 1) / row))
result_name = Path('result', f'{name}_添加水印.pdf')
target.save(str(result_name))
運行以后,會在項目根目錄生成一個result文件夾,里面就是添加了水印的PDF文件了,如下圖所示:
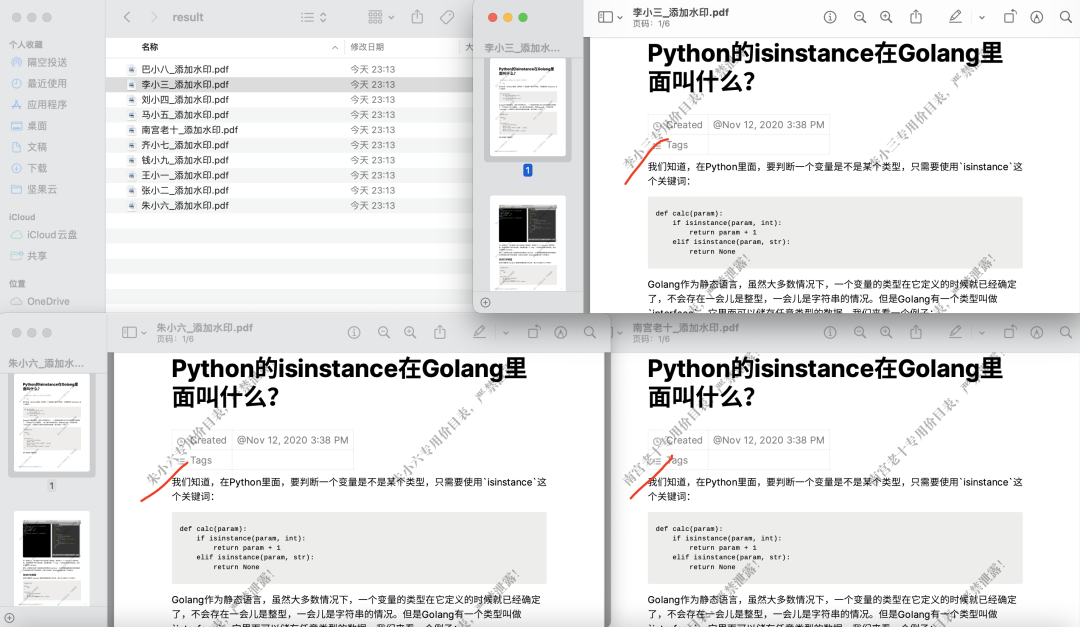
這里有必要對代碼中的一些地方進行解釋。帶上行號的代碼如下圖所示:
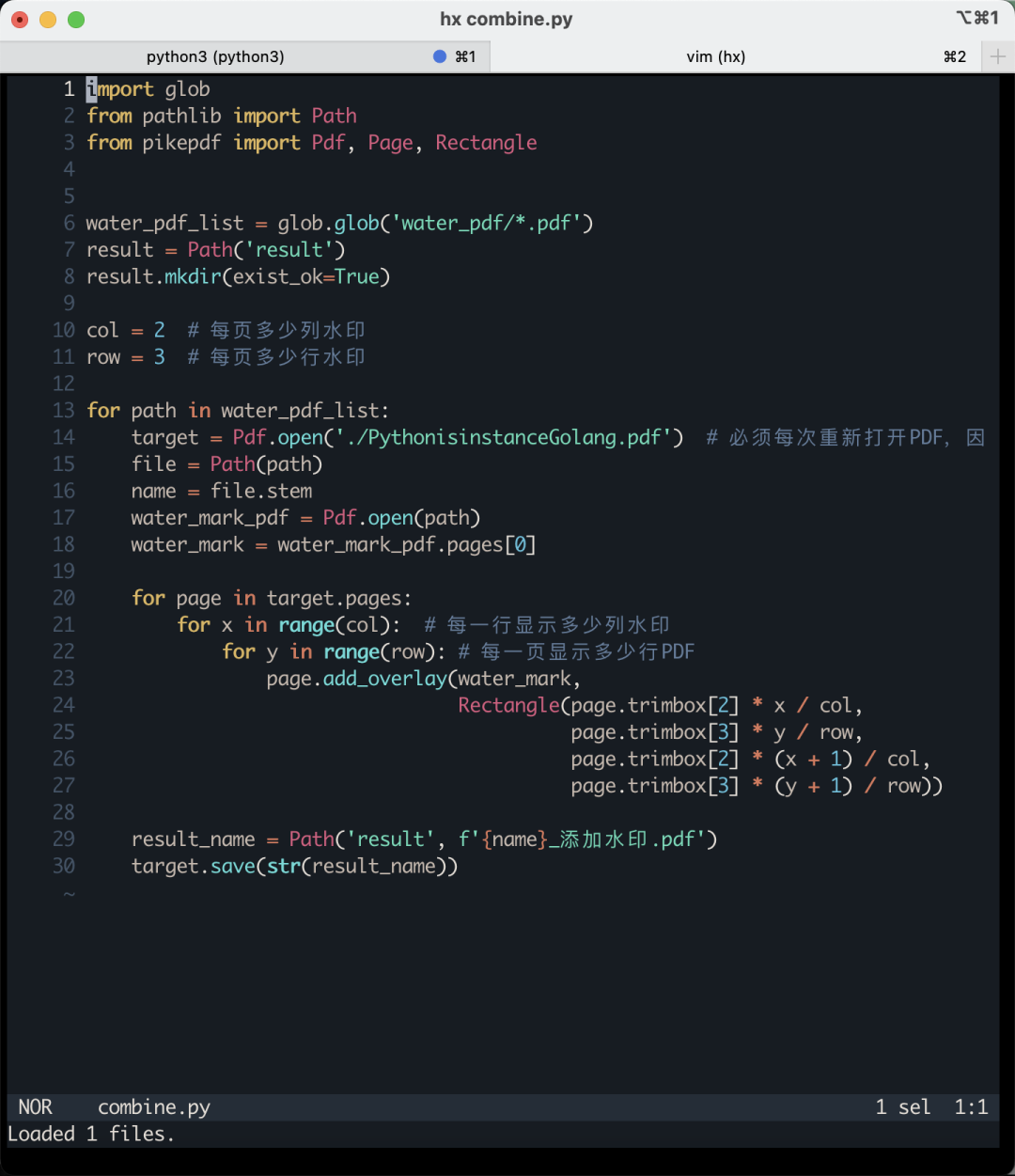
代碼第21行和22行,有兩個for循環,他們的作用是給一個頁面上添加多個水印。請大家注意下圖我畫圈的地方:
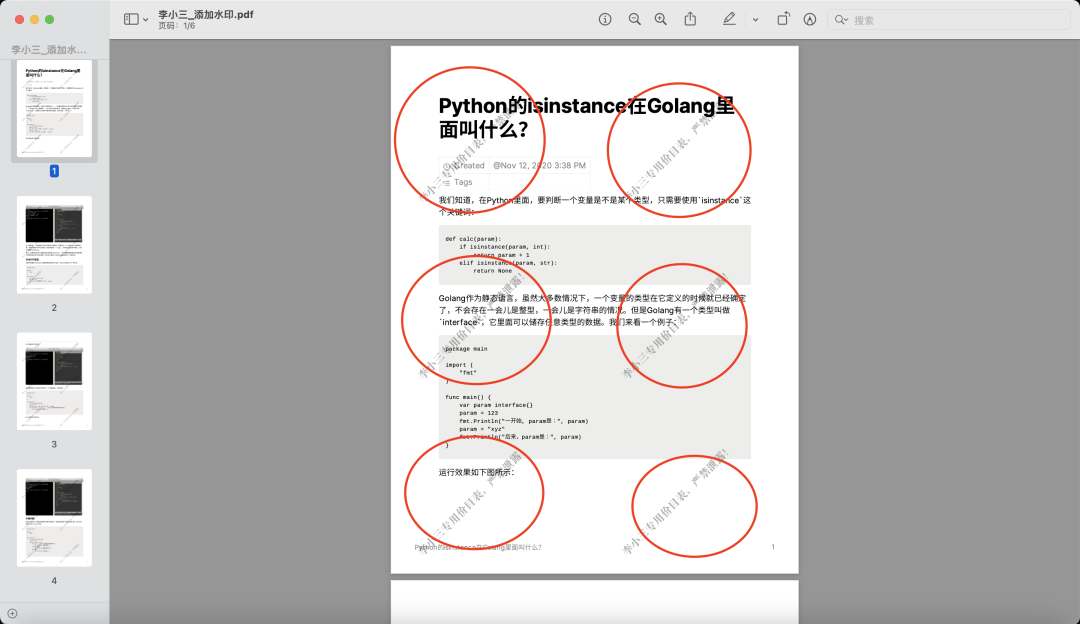
每一頁都有6個水印,分成3行2列。其中的3行對應了變量row的值。2列對應了變量col的值。大家也可以根據自己的需要修改這兩個數字。甚至每一頁的水印隨機變換位置,防止被去水印的程序移除。
page.trimbox是PDF頁面的寬度,page.trimbox是PDF頁面的高度。
總結
大家注意在這篇文章中,我把任務分成了三個部分,分別是:
- Excel轉CSV,讓Python方便讀取
- Python讀取CSV生成水印PDF
- 水印PDF與目標PDF文件合并
這三個部分的代碼是可以合并在一個.py文件里面的,但是我沒有這樣做,是考慮到問這個問題的同學不是程序員,Python水平只是入門,如果合并在一起,代碼量多了以后,出問題都不知道錯在哪里。
在計算機領域,所有問題都可以通過把問題拆分成多個部分分別單獨運行或者增加若干個中間層來解決。今天用的方法就是把問題拆分的方法。對于初學者來說,每一步都是相對獨立的,都能立刻看到效果。第二步只需要依賴第一步的結果,第三步只需要依賴第二步的結果,這樣每一步的輸入輸出非常清楚,可以顯著降低問題的復雜度。如果報錯了,也更容易知道是哪個地方有問題。