













為什么我建議需要定期重建數據量大但是性能關鍵的表

一般現在對于業務要查詢的數據量以及要保持的并發量高于一定配置的單實例 MySQL 的極限的情況,都會采取分庫分表的方案解決。當然,現在也有很多 new SQL 的分布式數據庫的解決方案,如果你用的是 MySQL,那么你可以考慮 TiDB(實現了 MySQL 協議,兼容 MySQL 客戶端以及 SQL 語句)。如果你用的是的 PgSQL,那么你可以考慮使用 YugaByteDB(實現了 PgSQL 協議,兼容 PgSQL 客戶端以及 SQL 語句),他們目前都有自己的云部署解決方案,你可以試試:
- TiDB Cloud。
- YugaByte Cloud。
但是對于傳統分庫分表的項目,底層的數據庫還是基于 MySQL 以及 PgSQL 這樣的傳統關系型數據庫。一般在業務剛開始的時候,會考慮按照某個分片鍵多分一些表,例如訂單表,我們估計用戶直接要查的訂單記錄是最近一年內的。如果是一年前的,提供其他入口去查,這時候查的就不是有業務數據庫了,而是歸檔數據庫,例如 HBase 這樣的。例如我們估計一年內用戶訂單,最多不會超過 10 億,更新的并發 TPS (非查詢 QPS)不會超過 10 萬/s。那么我們可以考慮分成 64 張表(個數最好是 2^n,因為 2^n 取余數 = 對 2^n - 1 取與運算,減少分片鍵運算量)。然后我們還會定時的歸檔掉一年前的數據,使用類似于 delete from table 這樣的語句進行“徹底刪除”(注意這里是引號的刪除)。這樣保證業務表的數據量級一直維持在
然而,日久天長以后,會發現,某些帶分片鍵(這里就是用戶 id)的普通查詢,也會有些慢,有些走錯本地索引。
查詢越來越慢的原因
例如這個 SQL:
select * from t_pay_record
WHERE
((
user_id = 'user_id1'
AND is_del = 0
))
ORDER BY
id DESC
LIMIT 201.2.3.4.5.6.7.8.9.
這個表的分片鍵就是 user_id。
一方面,正如我在“為什么我建議在復雜但是性能關鍵的表上所有查詢都加上 force index”中說的,數據量可能有些超出我們的預期,導致某些分片表大于一定界限,導致 MySQL 對于索引的隨機采樣越來越不準,由于統計數據不是實時更新,而是更新的行數超過一定比例才會開始更新。并且統計數據不是全量統計,是抽樣統計。所以在表的數據量很大的時候,這個統計數據很難非常準確。依靠表本身自動刷新數據機制,參數比較難以調整(主要是 STATS_SAMPLE_PAGES 這個參數,STATS_PERSISTENT 我們一般不會改,我們不會能接受在內存中保存,這樣萬一數據庫重啟,表就要重新分析,這樣減慢啟動時間,STATS_AUTO_RECALC 我們也不會關閉,這樣會導致優化器分析的越來越不準確),很難預測出到底調整到什么數值最合適。并且業務的增長,用戶的行為導致的數據的傾斜,也是很難預測的。通過 Alter Table 修改某個表的 STATS_SAMPLE_PAGES 的時候,會導致和 Analyze 這個 Table 一樣的效果,會在表上加讀鎖,會阻塞表上的更新以及事務。所以不能在這種在線業務關鍵表上面使用。所以最好一開始就能估計出大表的量級,但是這個很難。
所以,我們考慮對于數據量比較大的表,最好能提前通過分庫分表控制每個表的數據量,但是業務增長與產品需求都是不斷在迭代并且變復雜的。很難保證不會出現大并且索引比較復雜的表。這種情況下需要我們,在適當調高 STATS_SAMPLE_PAGES 的前提下,對于一些用戶觸發的關鍵查詢 SQL,使用 force index 引導它走正確的索引。
但是,有時候即使索引走對了,查詢依然有點慢。具體去看這個 SQL 掃描的數據行數的時候,發現并沒有很多。
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id | 32 | NULL | 16 | 0.01 | Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+1.2.3.4.5.
可能還是會有偶現的這樣的慢 SQL,并且隨著時間推移越來越多,這個就和 MySQL InnoDB 里面的刪除機制有關系了。目前大部分業務表都用的 InnoDB 引擎,并且都用的默認的行格式 Dynamic,在這種行格式下我們在插入一條數據的時候,其結構大概如下所示:

記錄頭中,有刪除標記:

當發生導致記錄長度變化的更新時,例如變長字段實際數據變得更長這種,會將原來的記錄標記為刪除,然后在末尾創建更新后的記錄。當刪除一條記錄的時候,也是只是標記記錄頭的刪除標記。
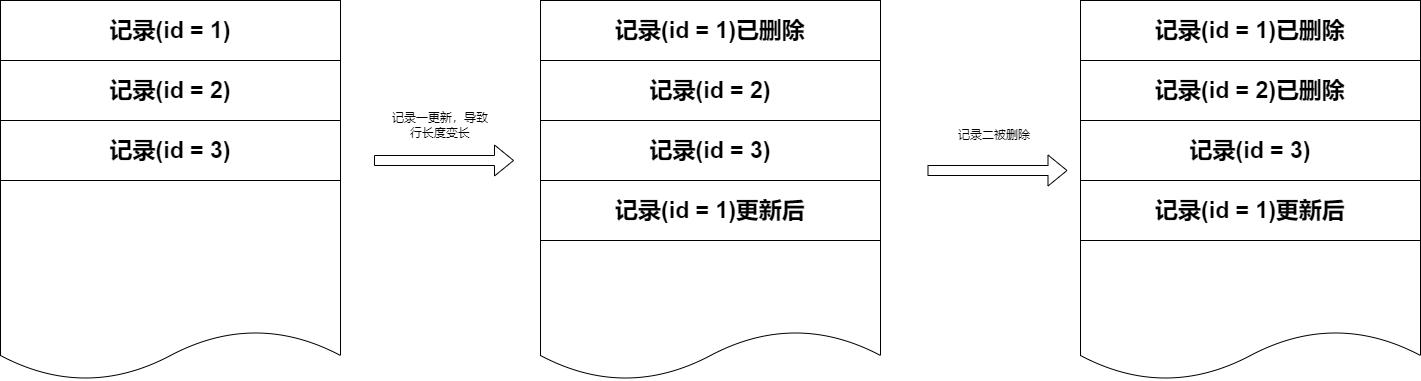
對于這種可能的碎片化,MySQL InnoDB 也是有期望并且措施的,即每個頁面 InnoDB 引擎只會存儲占用 93% 空間的數據,剩下的就是為了能讓長度變化的更新不會導致數據跑到其他頁面。但是相對的,如果 Delete 就相當于完全浪費了存儲空間了。
一般情況下這種不會造成太大的性能損耗,因為刪除一般是刪的老的數據,更新一般集中在最近的數據。例如訂單發生更新,一般是時間最近的訂單才會更新,很少會有很久前的訂單基本不會更新,并且歸檔刪除的一般也是很久之前的訂單。但是隨著業務越來越復雜,歸檔邏輯也越來越復雜,比如不同類型的訂單時效不一樣,可能出現一年前還有未結算的預購訂單不能歸檔。久而久之,你的數據可能會變成這樣:
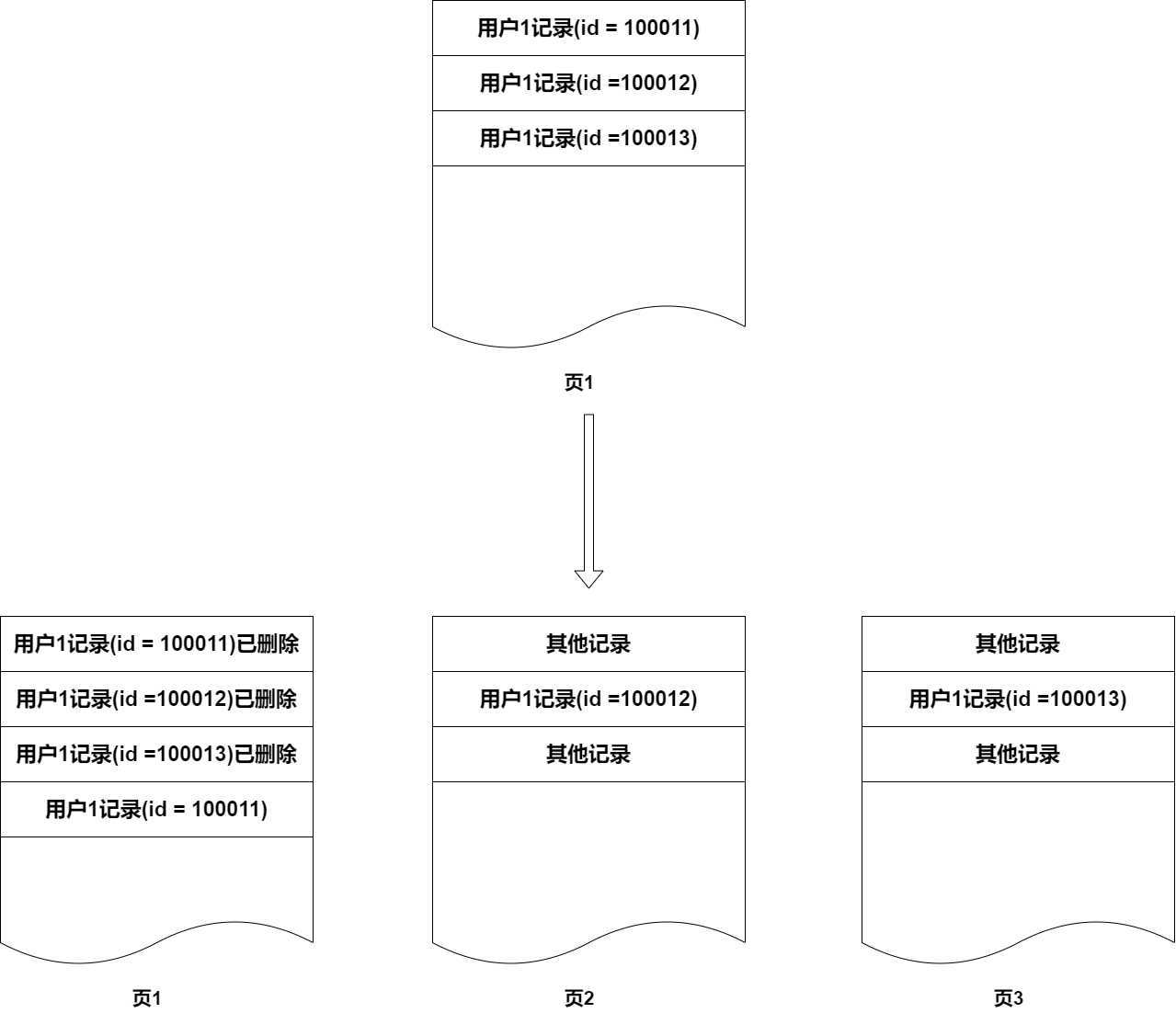
這樣導致,原來你需要掃描很少頁的數據,隨著時間的推移,碎片越來越多,要掃描的頁越來越多,這樣 SQL 執行會越來越慢。
以上是對于表本身數據存儲的影響,對于二級索引,由于 MVCC 機制的存在,導致頻繁更新索引字段會對索引也造成很多空洞。參考文檔:
https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html。
InnoDB multiversion concurrency control (MVCC) treats secondary indexes differently than clustered indexes. Records in a clustered index are updated in-place, and their hidden system columns point undo log entries from which earlier versions of records can be reconstructed. Unlike clustered index records, secondary index records do not contain hidden system columns nor are they updated in-place.
我們知道,MySQL InnoDB 對于聚簇索引是在索引原始位置上進行更新,對于二級索引,如果二級索引列發生更新則是在原始記錄上打上刪除標記,然后在新的地方記錄。這樣和之前一樣,會造成很多存儲碎片。
綜上所述:
- MySQL InnoDB 的會改變記錄長度的 Dynamic 行格式記錄 Update,以及 Delete 語句,其實是原有記錄的刪除標記打標記。雖然 MySQL InnoDB 對于這個有做預留空間的優化,但是日積月累,隨著歸檔刪除數據的增多,會有很多內存碎片降低掃描效率。
- MVCC 機制對于二級索引列的更新,是在原始記錄上打上刪除標記,然后在新的地方記錄,導致二級索引的掃描效率也隨著時間積累而變慢。
解決方案 - 重建表
對于這種情況,我們可以通過重建表的方式解決。重建表其實是一舉兩得的行為:第一可以優化這種存儲碎片,減少要掃描的行數;第二可以重新 analyze 讓 SQL 優化器采集數據更準確。
在 MySQL 5.6.17 之前,我們需要借助外部工具 pt-online-schema-change 來幫助我們完成表的重建,pt-online-schema-change 工具的原理其實就是內部新建表,在原表上加好觸發器同步更新到新建的表,并且同時復制數據到新建的表中,完成后,獲取全局鎖修改新建的表名字為原來的表名字,之后刪除原始表。MySQL 5.6.17 之后,Optimize table 命令變成了 Online DDL,僅僅在準備階段以及最后的提交階段,需要獲取鎖,中間的執行階段,是不需要鎖的,也就是不會阻塞業務的更新 DML。參考官網文檔:
https://dev.mysql.com/doc/refman/5.6/en/optimize-table.html。
Prior to Mysql 5.6.17, OPTIMIZE TABLE does not use online DDL. Consequently, concurrent DML (INSERT, UPDATE, DELETE) is not permitted on a table while OPTIMIZE TABLE is running, and secondary indexes are not created as efficiently.
As of MySQL 5.6.17, OPTIMIZE TABLE uses online DDL for regular and partitioned InnoDB tables, which reduces downtime for concurrent DML operations. The table rebuild triggered by OPTIMIZE TABLE is completed in place. An exclusive table lock is only taken briefly during the prepare phase and the commit phase of the operation. During the prepare phase, metadata is updated and an intermediate table is created. During the commit phase, table metadata changes are committed.
針對 InnoDB 表使用 Optimize Table 命令需要注意的一些點:
1.針對大部分 InnoDB 表的 Optimize Table,其實等價于重建表 + Analyze命令(等價于語句 ALTER TABLE ... FORCE),但是與 Analyze 命令不同的是, Optimize Table 是 online DDL 并且優化了機制,只會在準備階段和最后的提交階段獲取表鎖,這樣大大減少了業務 DML 阻塞時間,也就是說,這是一個可以考慮在線執行的優化語句(針對 MySQL 5.6.17之后是這樣)。
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+-------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | status | OK |
+----------+----------+----------+-------------------------------------------------------------------+1.2.3.4.5.6.7.
2.雖然如此,還是要選擇在業務低峰的時候執行 Optimize Table,因為和執行其他的 Online DDL 一樣,會創建并記錄臨時日志文件,該文件記錄了DDL操作期間所有 DML 插入、更新、刪除的數據,如果是在業務高峰的時候執行,很可能會造成日志過大,超過innodb_online_alter_log_max_size 的限制:
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | error | Creating index 'PRIMARY' required more than 'innodb_online_alter_log_max_size' bytes of modification log. Please try again.|
| test.foo | optimize | status | OK |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+1.2.3.4.5.6.7.8.
3.對于這種情況,如果我們已經處于業務低峰時段,但還是報這個錯誤,我們可以稍微調大innodb_online_alter_log_max_size 的大小,但是不能調太大,建議每次調大 128 MB(默認是 128 MB)。如果這個過大,會可能有兩個問題:(1)最后的提交階段,由于日志太大,提交耗時過長,導致鎖時間過長。(2)由于業務壓力導致一直不斷地寫入這個臨時文件,但是一直趕不上,導致業務高峰到得時候這個語句還在執行。
4.建議在執行的時候,如果要評估這個對于線上業務的影響,可以針對鎖wait/synch/sxlock/innodb/dict_sys_lock 和 wait/synch/sxlock/innodb/dict_operation_lock 這兩個鎖進行監控,如果這兩個鎖相關鎖事件太多,并且線上有明顯的慢 SQL,建立還是 kill 掉選其他時間執行 Optimize table 語句。
select thread_id,event_id,event_name,timer_wait from events_waits_history where event_name Like "%dict%" order by thread_id;
SELECT event_name,COUNT_STAR FROM events_waits_summary_global_by_event_name
where event_name Like "%dict%" ORDER BY COUNT_STAR DESC;




















