系統設計:微服務重試機制

為什么微服務重試機制很重要?
當我們單體應用時,所有的邏輯計算都在單一的進程中,除了進程斷電外幾乎不可能有處理失敗的情況。然而,當我們把單體應用拆分為一個個細分的子服務后,服務間的互相調用無論是RPC還是HTTP,都是依賴于網絡。
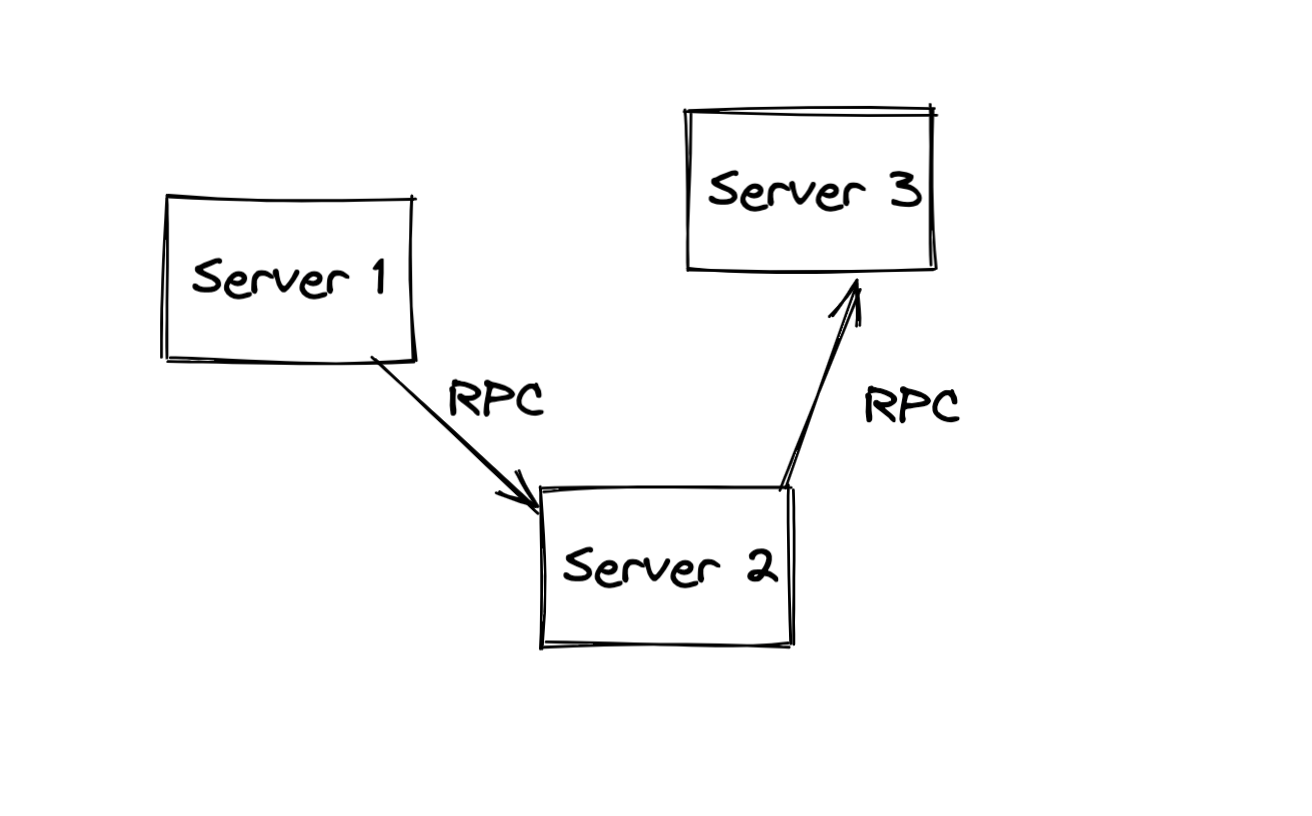
網絡是脆弱的,不時請求會出現抖動失敗。例如我們的 Server1 調用 Server2 進行下單時,可能網絡超時了,這個時候 Server1 就需要返回給用戶提示「網絡錯誤」,這樣我們的服務質量就下降了,可能會收到用戶的投訴吐槽,降低產品競爭力。
這也是為什么很多產品內部都建設接口維度的 SLA 指標,當成功率低于一定程度時需要和負責人績效掛鉤以此來推進產品的穩定性。
對于網絡抖動這種情況,解決的最簡單辦法之一就是重試。
重試機制
重試機制:同步 、異步模式
常見的重試主要有兩種模式:原地重試、異步重試。
原地重試很好理解,就是程序在調用下游服務失敗的時候重新發起一次;異步重試是將請求信息丟到某個 mq 中,后續有一個程序消費到這個事件進行重試。
總的來說,原地重試實現簡單,能解決大部分網絡抖動問題,但是如果是服務追求強一致性,并且希望在下游故障的時候不影響正常服務計算,這個時候可以考慮用異步重試,上游服務可快速響應用戶請求由異步消費者去完成重試。
重試算法
無論是異步還是同步模式,重試都有固定的幾個算法:
- 線性退避:每次失敗固定等待固定的時間。
- 隨機退避:每次失敗等待隨機的時間重試。
- 指數退避:連續重試時,每次等待的時間都是前一次等待時間的倍數。
- 綜合退避:結合多種方式,比如線性 + 隨機抖動、指數 + 隨機抖動。加上隨機抖動可以打散眾多服務失敗時對下游的重試請求,防止雪崩。
為什么需要等待下再重試?
因為網絡抖動或者下游負載高,馬上重試成功的概率必然遠遠小于稍等一會再重試,相當于是讓下游先喘一口氣。
重試風暴
在微服務架構中,務必要注意避免重試風暴的產生。那么,什么是重試風暴呢?
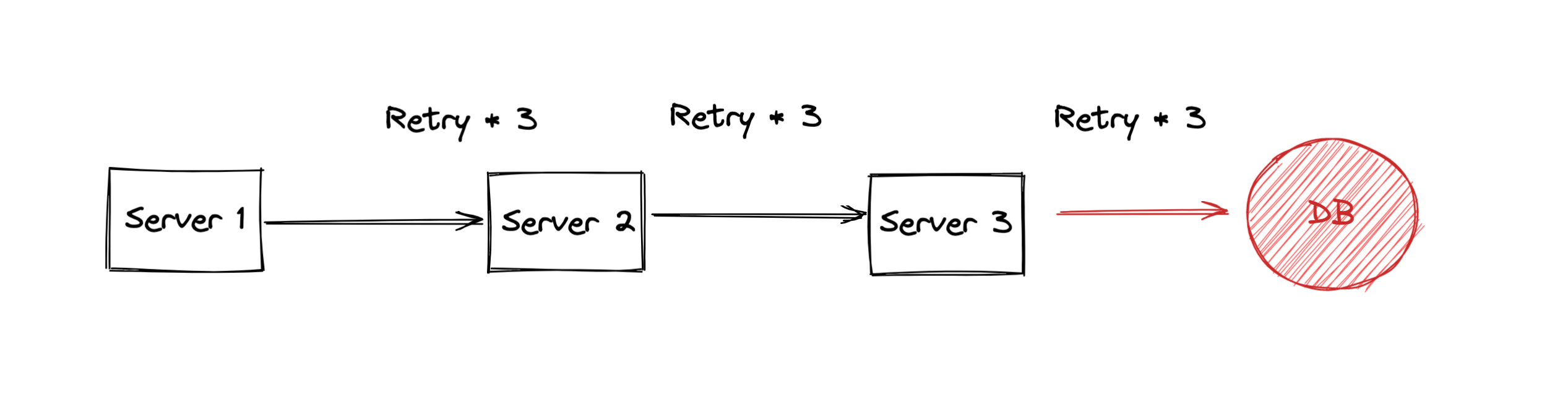
如圖所示,數據庫出現了負載過高的情況,這個時候 Server 3 對它的請求會失敗。但是因為配置了重試機制,Server 3 最多對數據庫發起了3次請求。然而,這個時候荒唐的事情就出現了,為了避免抖動上游的每個服務都設置了超時重試3次的機制,這樣明明是一次業務請求,在上述中由于有3個環節存在變成了對數據庫的 27 (3 ^(n)) 次請求!這對原本就要崩潰的數據庫,更是雪上加霜。
微服務架構通常一次請求會經過數個甚至數百個服務處理,如果每個都這樣重試,數據庫壓力稍微彪高一點本身沒啥問題,但是很可能就因為重試導致雪崩。
如何防止重試風暴
單實例限流
首先,我們接受請求的是單個實例(進程)中的線程,所以可以以單進程的粒度進行限流。
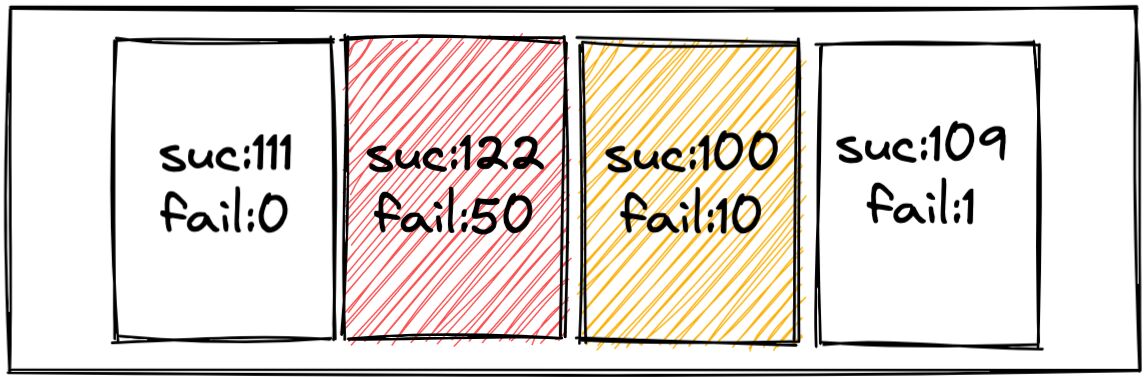
關于限流,我們常用的是令牌桶或者滑動窗口兩種實現,這里簡單實用滑動窗口實現。如下圖所示,每秒會產生一個Bucket,我們在Bucket里記錄這一秒內對下游某個接口的成功、失敗數量。進而可以統計出每秒的失敗率,結合失敗率及失敗請求數判斷是否需要重試,每個 Bucket 在一定時間后過期。
如果下游大面積失敗,這種時候是不適合重試的,我們可以配置一個比如失敗率超過10%不重試的策略,這樣在單機層面就可以避免很多不必要的重試。
規范重試狀態碼
鏈路層面防止重試的最好做法是只在最下游重試(我們上面圖的 Server3),Google SRE中指出了Google內部使用特殊錯誤碼的方式來實現:
- 約定一個特殊的業務狀態碼,它表示失敗了,但是別重試。
- 任何一個環節收到下游這個錯誤,不會重試,繼續透傳給上游。
通過這個模式,如果是數據庫抖動情況下,只有最下游的三個重試請求,上游服務判斷狀態碼知道不可重試不再重試。除此之外,在一些業務異常情況下也可通過狀態碼區分出無需重試的狀態。
這個方法可以有效避免重試風暴,但是缺陷是需要業務方強耦合上這個狀態碼的邏輯,一般需要公司層面做框架上的約束。
超時優化
在重試中,最頭疼的莫過于超時這種場景。我們知道網絡超時,有可能請求壓根沒到下游服務就產生了,也可能是已經到達下游并且被處理了,只是來不及返回,一個典型的兩軍問題。
關于超時的情況,顯然無法通過錯誤碼識別,例如 A -> B -> C -> D 情況,如果C故障了,B可以獲取到錯誤碼,并返回給 A,但是因為 A 請求 B 超時了,所以是獲取不到錯誤碼的,這個時候 A 又會發起重試。那么針對超時的情況有沒什么辦法做優化,避免無必要的重試呢?
我認為有幾個地方是可以做的:
上游重試的請求不重試
超時導致的重試請求,在請求中帶一個 Flag 標記。如果下游發現上游是因為超時而發起的請求,自己在請求下游時如果再超時出錯,不再重試。例如 A -> B -> C 時,A 請求 B 超時重試,那么重試時會帶上 Flag,B 發現 A 的重試請求中的 Flag,如果這個時候請求 C 失敗,那么也不再重試請求,這樣就避免了重試被放大。
合理設置各個環節超時時間
A -> B -> C,B -> C 加上超時最多是 1s 時間,那么 A -> B 的超時時間要 >= 1秒,否則可能 B 對 C 的重試還沒結束, A 就發起重試請求了。這類問題,我們可以通過分析離線數據發現環節中存在的不合理配置。
通過上述的優化,我們可以在一定程度上規避超時引發的重試風暴。
降低時延的重試
我們上文主要都在闡述為了保障請求 SLA 的重試以及規避重試風暴的手段,但是其實在實際應用過程中有一些低時延的業務場景也經常使用重試來優化,這個優化措施就是 backupRequest。
比方說用戶下單接口,我們希望更低的時延,因為延遲變高了用戶可能下單量就減少了,直接影響到公司的盈利。假設我們的接口時延 p95 是 300ms,也就是95%的用戶能在 300ms 內完成下單,雖然看起來很美好,但是可能存在 “長尾效應”,這尾部的 5% 對于業務來說也是至關重要的。
對于這種情況,常見的優化方案就是 backupRequest,簡單來說策略就是這樣的:
如果正常請求的超時時間是1s,那么當超時時間超過x ms(eg. 500ms)不等超時時間直接再發起一個相同的請求,如果舊的請求超時,新的請求正常落在300ms以內,那么我們這次請求不會超時且會在超時時間內完成。
這個機制對于時延敏感的業務非常有效,但是必須要保證請求是可重試的。
總結
這篇文章到這里就接近尾聲了,如果你堅持讀到這里,恭喜你已經掌握了微服務的重試機制,相信在工作中遇到的問題也都能游刃有余。下面我簡單做下總結:
- 微服務重試很重要,因為可以避免一些網絡波動導致的請求失敗,提升服務穩定性。
- 重試機制分為同步、異步兩種模式,各有各的特性,需要結合業務選擇。
- 常見的重試算法有線性退避、指數退避、隨機退避,以及結合其中兩種的綜合退避。
- 重試風暴,在微服務中是一大隱患,我們可以通過單機重試限流以及約定重試狀態碼來規避。
- 超時場景下的重試優化,上游因超時發起的流量,下游收到不再重復重試;合理配置鏈路超時時間。
- 針對時延敏感業務,可使用 backup request 減輕長尾效應。