給幾句話就能生成分子,看見分子也能生成描述,神秘的Google X把多模態AI做成了黑科技
設想一下,醫生寫幾句話來描述一種專門用于治療患者的藥物,AI 就能自動生成所需藥物的確切結構。這聽起來像是科幻小說,但隨著自然語言和分子生物學交叉領域的進展,未來很有可能成為現實。傳統意義上講,藥物創造通常依靠人工設計和構建分子結構,然后將一種新藥推向市場可能需要花費超過 10 億美元并需要十年以上的時間(Gaudelet et al., 2021)。
近來,人們對使用深度學習工具來改進計算機藥物設計產生了相當大的興趣,該領域通常被稱為化學信息學(Rifaioglu et al., 2018)。然而,其中大多數實驗仍然只關注分子及其低級特性,例如 logP,辛醇 / 水分配系數等。未來我們需要對分子設計進行更高級別的控制,并通過自然語言輕松實現控制。
來自伊利諾伊大學厄巴納-香檳分校和 Google X 的研究者通過提出兩項新任務來實現分子與自然語言轉換的研究目標:1)為分子生成描述;2)在文本指導下從頭生成分子。

論文地址:http://blender.cs.illinois.edu/paper/molt5.pdf
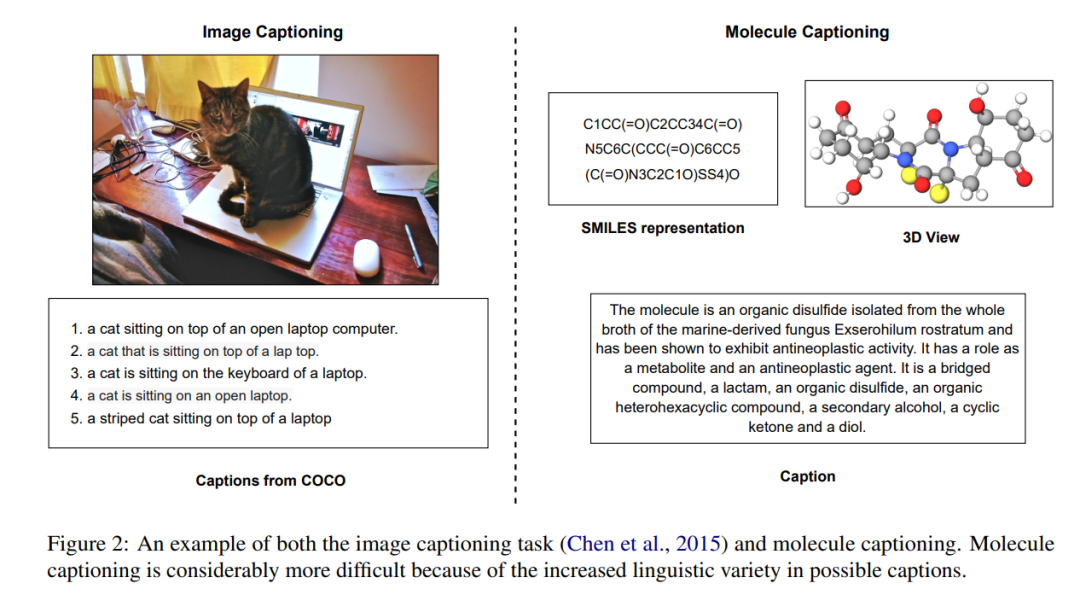
如下圖所示,文本指導分子生成任務是創建一個與給定自然語言描述相匹配的分子,這將有助于加速多個科學領域的研究。
在多模態模型領域,自然語言處理和計算機視覺 (V+L) 的交叉點已被廣泛研究。通過自然語言實現對圖像的語義級控制已取得一些進展,人們對多模態數據和模型越來越感興趣。
該研究提出的分子 - 語言任務與 V+L 任務有一些相似之處,但也有幾個特殊的難點:1)為分子創建注釋需要大量的專業知識,2)因此,很難獲得大量的分子 - 描述對,3) 同一個分子可以具有許多功能,需要多種不同的描述方式,這導致 4) 現有評估指標(例如 BLEU)無法充分評估這些任務。
為了解決數據稀缺的問題,該研究提出了一種新的自監督學習框架 MolT5(Molecular T5),其靈感來源于預訓練多語言模型的最新進展(Devlin et al., 2019; Liu et al., 2020)。MolT5 首先使用簡單的去噪目標在大量未標記的自然語言文本和分子字符串上預訓練模型。之后,預訓練模型在有限的黃金標準注釋上進行微調。
此外,為了充分評估分子描述或生成模型,該研究提出了一個名為 Text2Mol 的新指標(Edwards et al., 2021)。Text2Mol 重新調整了檢索模型的用途,以分別評估實際分子 / 描述和生成的描述 / 分子之間的相似性。
多模態文本 - 分子表示模型 MolT5
研究人員可以從互聯網上抓取大量的自然語言文本。例如,Raffel et al. (2019) 構建了一個 Common Crawl-based 數據集,該數據集包含超過 700GB、比較干凈的自然英語文本。另一方面,我們也可以從 ZINC-15 等公共數據庫中獲取超過 10 億個分子的數據集。受近期大規模預訓練進展的啟發,該研究提出了一種新的自監督學習框架 MolT5(Molecular T5),其可以利用大量未標記的自然語言文本和分子字符串。
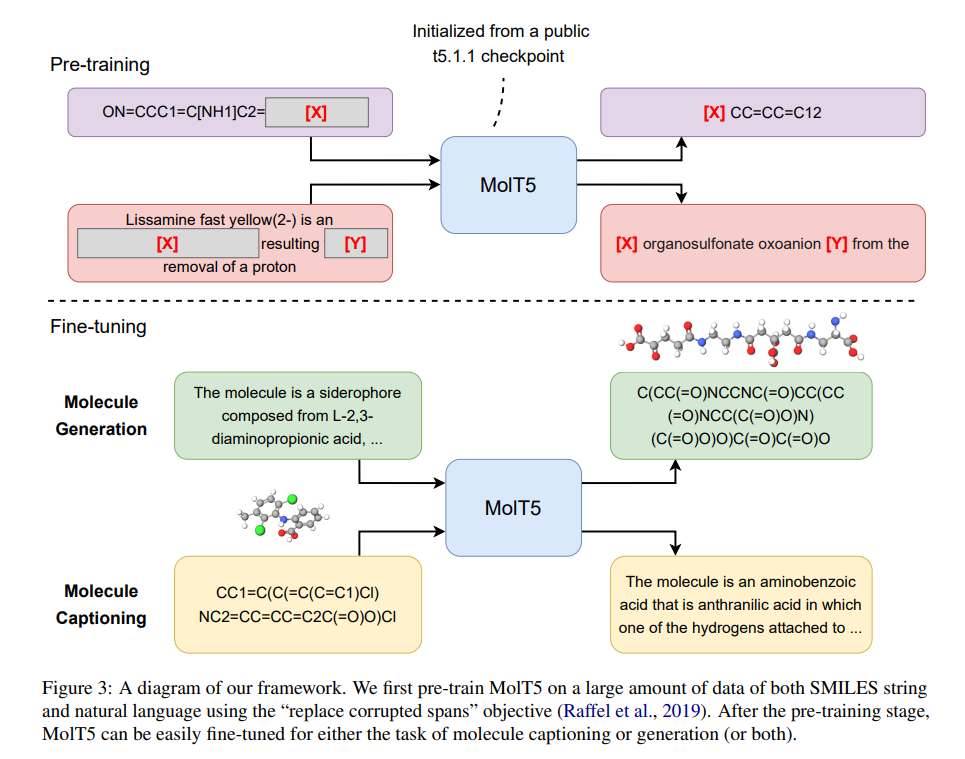
圖 3 為 MolT5 架構圖。該研究首先使用 T5.1.1(T5 的改進版本)的公共檢查點(public checkpoints)之一初始化編碼器 - 解碼器 Transformer 模型。之后,他們使用「replace corrupted spans」目標對模型進行預訓練。具體而言,在每個預訓練 step 中,該研究都會采樣一個包含自然語言序列和 SMILES 序列的 minibatch。對于每個序列來說,研究者將隨機選擇序列中的一些單詞進行修改。每個連續 span 中的 corrupted token 都被一個 sentinel token 替換(如圖 3 中的 [X] 和 [Y] 所示)。接下來的任務是預測 dropped-out span。
分子(例如,用 SMILES 字符串表示)可以被認為是一種具有非常獨特語法的語言。直觀地說,該研究的預訓練階段本質上是在來自兩種不同語言的兩個單語語料庫上訓練一個語言模型,并且兩個語料庫之間沒有明確的對齊方式。這種方法類似于 mBERT 和 mBART 等多語言語言模型的預訓練方式。由于 mBERT 等模型表現出出色的跨語言能力,該研究還期望使用 MolT5 預訓練的模型對文本 - 分子翻譯任務有用。
預訓練之后,可以對預訓練模型進行微調,以用于分子描述(molecule captioning)或生成(如圖 3 的下半部分所示)。在分子生成中,輸入是一個描述,輸出是目標分子的 SMILES 表示。另一方面,在分子描述中,輸入是某個分子的 SMILES 字符串,輸出是描述輸入分子的文字。
實驗結果
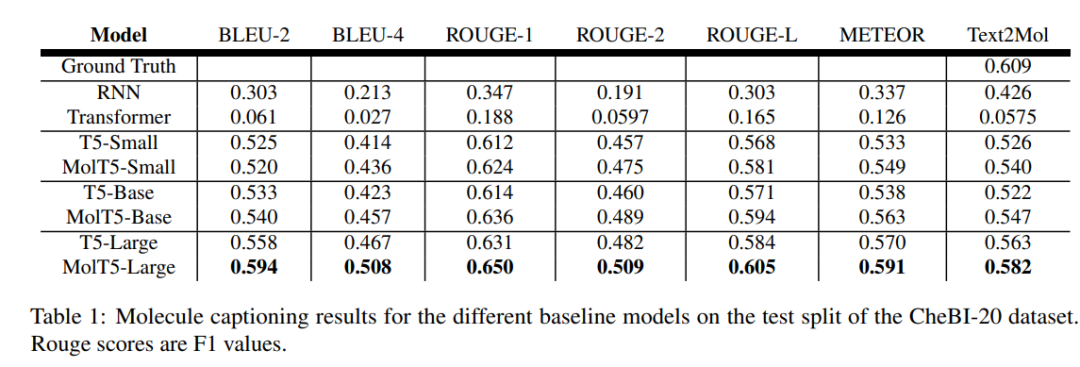
下表 1 為分子描述測試結果,研究發現,大的預訓練模型在生成逼真語言來描述分子方面,T5 或 MolT5 比 Transformer 或 RNN 要好得多。
下圖 5 顯示了幾個不同模型輸出示例。

不同模型的生成結果示例(節選)。
通常 RNN 模型在分子生成方面優于 Transformer 模型,而在分子描述任務中,大型預訓練模型比 RNN 和 Transformer 模型表現得更好。眾所周知,擴展模型大小和預訓練數據會導致性能顯著提高,但該研究的結果仍然令人驚訝。
例如,一個默認的 T5 模型,它只在文本數據上進行了預訓練,能夠生成比 RNN 更接近真值的分子,而且通常是有效的。并且隨著語言模型規模的擴展,這種趨勢持續存在,因為具有 770M 參數的 T5-large 優于具有 60M 參數的專門預訓練的 MolT5-small。盡管如此,MolT5 中的預訓練還是略微改善了一些分子生成結果,尤其是在有效性方面的大幅提升。
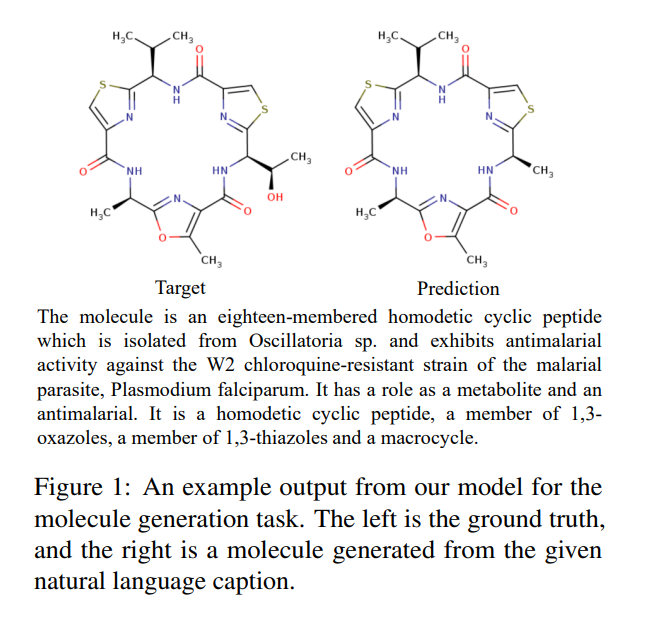
下圖 4 顯示了模型的結果,并且按輸入描述對其進行編號。實驗發現,與 T5 相比,MolT5 能夠更好地理解操作分子的指令。
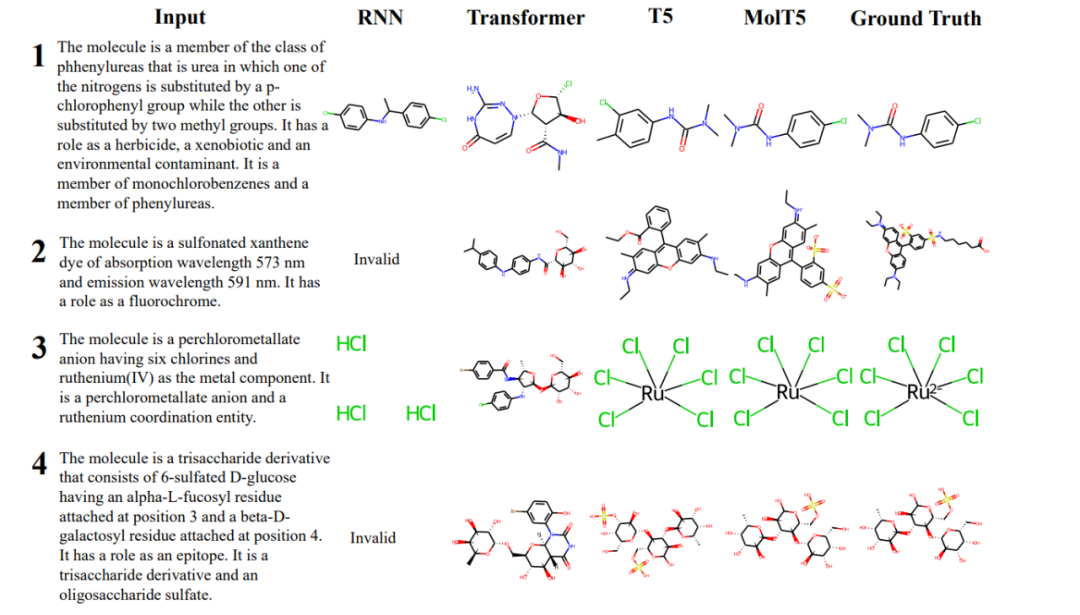
不同模型生成的分子示例展示。