爬蟲必學(xué)包 lxml,搞個有趣的

你好,我是zhenguo,今天搞點有趣的。
這篇文章講什么?
我們爬取網(wǎng)頁后,無非是先定位到html標(biāo)簽,然后取其文本。定位標(biāo)簽,最常用的一個包lxml。
在這篇文章,我會使用一個精簡后的html頁面,演示如何通過lxml定位并提取出想要的文本,包括:
- html是什么?
- 什么是lxml?
- lxml例子,包括如何定位?如何取內(nèi)容?如何獲取屬性值?
html是什么?
html,全稱HyperText Markup Language,是超文本標(biāo)記結(jié)構(gòu)。
html組織結(jié)構(gòu)對應(yīng)數(shù)據(jù)結(jié)構(gòu)的樹模型。
因為是樹,所以只有一個根節(jié)點,即一對<html></html>標(biāo)簽。一對<>和名稱組合稱為標(biāo)簽,例如,<html>被稱為開始標(biāo)簽,</html>被稱為結(jié)束標(biāo)簽。
開始標(biāo)簽中可以添加附加信息,風(fēng)格為屬性名=屬性值。
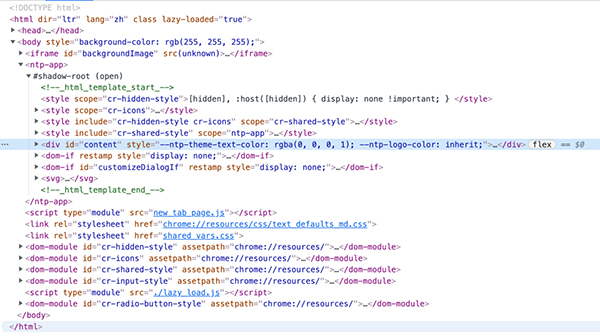
如下所示,選中的<div>就是一個開始標(biāo)簽,它有屬性id,值為content,還有屬性style等:
什么是lxml?
lxml官檔截圖如下,按照官檔的說法,lxml是Python語言中,處理XML和HTML,功能最豐富、最易于使用的庫。

不難猜想,lxml中一定實現(xiàn)了查詢樹中某個節(jié)點功能,并且應(yīng)該性能極好。
lxml例子
廢話不多說,舉例演示lxml超簡便的定位能力。
導(dǎo)入lxml中的etree:
from lxml import etree
my_page是html風(fēng)格的字符串,內(nèi)容如下所示:
my_page = '''
<html>
<title>程序員zhenguo</title>
<body>
<div>我的文章</div>
<h1>我的網(wǎng)站</h1>
<div id="photos">
<img src="pic1.png" />
<span id="pic1"> 從零學(xué)Python </span>
<img src="pic2.png" />
<span id="pic2">大綱</span>
<p>
<a href="http://www.zglg.work">更多詳情</a>
</p>
<a href="http://www.zglg.work/python-packages/">Python包</a>
<a href="http://www.zglg.work/python-intro/">Python小白</a>
<a href="http://www.zglg.work/python-level/">Python進階</a>
</div>
<div id="explain">
<p class="md-nav__item">本站總訪問量159323次</p>
</div>
<div class="foot">Copyright ? 2019 - 2021 程序員zhenguo</div>
</body>
</html>
'''
使用etree.fromstring轉(zhuǎn)化為可以使用xpath的對象。
html = etree.fromstring(my_page)
定位
接下來,就能方便的定位:
- 定位出所有div標(biāo)簽,寫法//div
# 定位
divs1 = html.xpath('//div')
- 定位出含有屬性名為id的所有標(biāo)簽,寫法為://div[@id]
divs2 = html.xpath('//div[@id]')- 定位出含有屬性名class等于foot的所有div標(biāo)簽,寫法為://div[@class="foot"]
divs3 = html.xpath('//div[@class="foot"]')- 定位出含有屬性名的所有div標(biāo)簽,寫法為://div[@*]
divs4 = html.xpath('//div[@*]')- 定位出不含有屬性名的所有div標(biāo)簽,寫法為:not(@*)
divs5 = html.xpath('//div[not(@*)]')- 定位出第一個div標(biāo)簽,寫法為://div[1]
divs6 = html.xpath('//div[1]')- 定位出最后一個div標(biāo)簽,寫法為://div[last()]
divs7 = html.xpath('//div[last()]')- 定位出前兩個div標(biāo)簽,寫法為//div[position()<3],注意從1開始:
divs8 = html.xpath('//div[position()<3]')- 定位出所有div標(biāo)簽和h1標(biāo)簽,寫法為://div|//h1,使用|表達:
divs9 = html.xpath('//div|//h1')取內(nèi)容
取出一對標(biāo)簽中的內(nèi)容,使用text()方法。
如下所示,取出屬性名為foot的標(biāo)簽div中的text:
text1 = html.xpath('//div[@class="foot"]/text()')取屬性
除了定位標(biāo)簽,獲取標(biāo)簽間的內(nèi)容外,也會需要提取屬性對應(yīng)值。
獲取標(biāo)簽a下所有屬性名為href的對應(yīng)屬性值,寫法為://a/@href
value1 = html.xpath('//a/@href')得到結(jié)果:
['http://www.zglg.work', 'http://www.zglg.work/python-packages/', 'http://www.zglg.work/python-intro/', 'http://www.zglg.work/python-level/']
還可以做一些特殊的定制操作,如使用findall方法,定位到div標(biāo)簽下帶有a的標(biāo)簽。
使用text獲取內(nèi)容,a.attrib.get獲取對應(yīng)屬性值。
divs = html.xpath('//div[position()<3]')
for div in divs:
ass = div.findall('a') # div/a
for a in ass:
if a is not None:
# print(dir(a))
print(a.text, a.attrib.get('href'))最后注意一個區(qū)別,a_href等于第二個div標(biāo)簽下的子標(biāo)簽a的href屬性值;
b_href等于第二個div標(biāo)簽下的子或所有后代標(biāo)簽下a的href屬性值:
a_href = html.xpath('//div[position()=2]/a/@href')
print(a_href)
b_href = html.xpath('//div[position()=2]//a/@href')
print(b_href)