基于間距自適應查找表的實時圖像增強方法
近日,阿里巴巴大淘系技術與上海交通大學圖像通信與網絡工程研究所(簡稱圖像所)合作論文《AdaInt:Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement》被國際頂級會議CVPR2022接收,全部代碼及模型均已開源。
作為計算機視覺領域的三大頂級會議之一,CVPR是每年學術界的重要事件之一。CVPR全稱為The Conference on Computer Vision and Pattern Recognition,即計算機視覺與模式識別會議,是由IEEE主辦的國際最高級別的學術會議。該會議每年在世界范圍內召開一次,討論內容涵蓋了與圖像或視頻模式提取或識別相關的廣泛主題,常見主題包括對象識別、目標檢測、圖像分割、圖像恢復和圖像增強等。今年的CVPR會議接收了來自世界各地總計8,161份的有效論文投稿,經過會議主席和眾多審稿人的努力,共計2,067份論文投稿被會議接收,總接收率約為25.33%。
本文首次提出了通過深度學習對輸入圖像自適應地學習具有非均勻布局的三維顏色查找表,從而對輸入圖像進行高效色彩增強的創新性技術,并在學術界公開仿真數據集上取得了最優客觀指標(PSNR)的同時做到了當前運行速度最快。文中提到的色彩增強技術具有效果優、速度快的特點,可做到對4K視頻的實現高效處理并提升其色彩飽和度對比度,故而適用于實時流媒體場景,可用較普惠化的方式幫助改善直播間的畫質呈現。

論文地址:https://arxiv.org/abs/2204.13983
項目地址:https://github.com/ImCharlesY/AdaInt
作者單位:大淘寶技術,上海交通大學,大連理工大學
背景
色彩增強是圖像處理的基本內容之一,是相機成像系統的核心部件之一,并廣泛體現在數字圖像成像鏈路中的各階段應用中。其主要目的是通過處理原始圖像,使其更加符合人的視覺特性或顯示設備的展示要求。近年來,主流的基于深度學習的色彩增強方法將增強流程簡化歸并到單個全卷積網絡中。通過數據驅動下的端到端學習,這類方法可以在公開數據集上取得先進的色彩增強效果。然而,全卷積范式也給網絡的推理,特別是在超高分辨率的圖像(如4K及以上分辨率)上,帶來了高昂的時空計算復雜度,限制了這些方法的實際應用。
最新的研究工作[1]表明,大部分的色彩增強/美化算子(如白平衡、飽和度控制、色調映射、對比度調整、曝光補償等)屬于點運算的范疇。變換算子的參數會根據圖像整體或局部統計特性來確定,但變換算子本身對圖像的操作和編輯是位置無關、像素獨立的。它們的級聯在整體效應上近似等效為單次三維顏色變換,即一個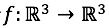 的函數映射式。該映射將輸入圖像中的一個顏色點映射為同一顏色空間或不同顏色空間的另一個顏色點。一個直觀的思路是將一系列增強變換算子合并為單個顏色變換算子,從而減少一系列變換操作帶來的計算量,并減小累積誤差對增強效果的影響。
的函數映射式。該映射將輸入圖像中的一個顏色點映射為同一顏色空間或不同顏色空間的另一個顏色點。一個直觀的思路是將一系列增強變換算子合并為單個顏色變換算子,從而減少一系列變換操作帶來的計算量,并減小累積誤差對增強效果的影響。
在這種情況下,三維查找表(3D Lookup Tables,3D LUTs)是一種極具價值的數據結構,它通過遍歷變換函數的所有可能輸入顏色組合,記錄對應的輸出顏色結果,可以對一個復雜的顏色變換函數進行高效建模,在計算機硬件設計、相機成像系統中有廣泛的應用。然而,完整輸入空間的遍歷往往帶來沉重的內存開銷,更常用的方式是稀疏查找表:對輸入空間進行稀疏采樣,僅記錄采樣點的對應輸出;對于不被采樣到的點,其變換輸出由最近鄰采樣點的輸出線性插值獲得。因此稀疏查找表實質是對原始變換函數的一種有損近似,其變換能力的損失體現在通過分段線性函數擬合原始變換函數中潛在的非線性部分。
工作動機
由于3D LUT的計算高效性和穩定魯棒的顏色變換能力,最新的研究工作[2]結合了3D LUT的高效計算性能和深度神經網絡的強大數據特征提取能力,通過深度網絡從圖像中自適應地生成稀疏三維查找表以進行實時色彩增強,證明了3D LUT在基于深度學習的自適應色彩增強中的可行性和有效性。然而,通過深度網絡自適應預測稀疏3D LUT時,現有工作僅考慮了3D LUT中記錄的輸出值的圖像自適應性,而卻對所有不同圖像均采用統一的均勻稀疏點采樣策略(將三維輸入顏色空間等間隔地離散化成三維網格),未能有效考慮到稀疏3D LUT中采樣點在輸入空間中的分布也應根據圖像內容自適應調整。這一重要建模能力的缺失導致該方法學習到的3D LUT中稀疏采樣點分配策略次優,從而限制了最終所得3D LUT的模型變換能力。這具體表現為:由于采樣點的稀疏性和3D LUT變換中采用的線性插值帶來的非線性變換表達能力的損失,均勻采樣策略可能將顏色相近的輸入像素量化到3D LUT的同一網格區間內;當這些輸入像素的對應輸出值需要較高的非線性對比度時(如增強圖像中處于暗光條件下具有顯著色彩差異的紋理區域時),單個LUT網格卻僅能提供線性的顏色拉伸變換,從而可能導致變換結果的顏色平滑。這種現象可以類比為數字信號處理領域中因采樣頻率不滿足奈奎斯特-香農采樣定律而導致的信號失真,如下左邊示意圖所示。理想情況下,增加稀疏采樣點的數量或引入非線性插值也許可以有效緩解這種非線性變換能力不足的問題,但也會顯著增加3D LUT方法的計算和內存復雜度,犧牲了LUT方法的實時性。此外,如下右半部分的示意圖所示,在均勻采樣策略中直接增加采樣點的數量也會加劇3D LUT對顏色變換平坦區域(如輸出顏色僅為輸入顏色的線性拉伸)甚至對輸入顏色空間中鮮有像素分布的區域的過采樣,從而造成了3D LUT模型容量和內存消耗的浪費。
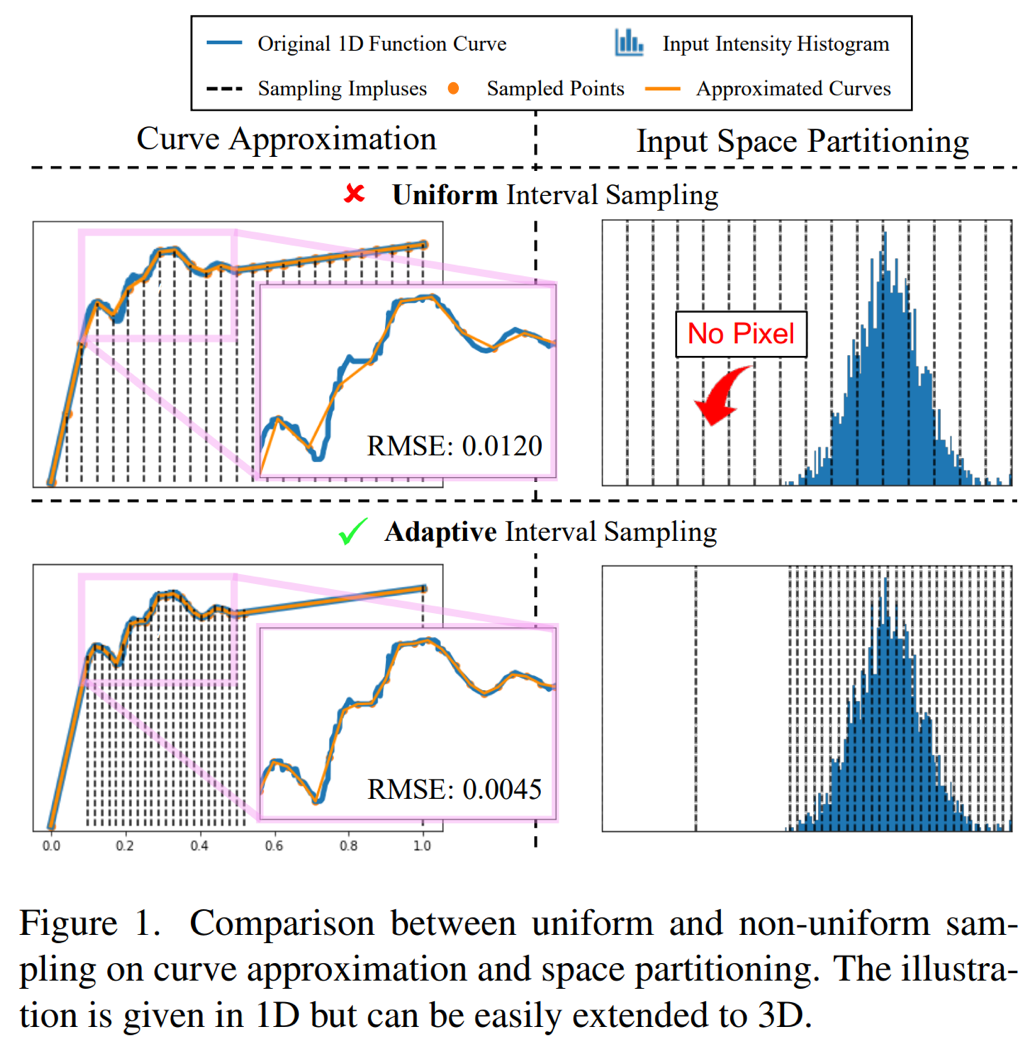
方法介紹
針對現有工作因其在輸入空間中通過均勻量化間隔的有限稀疏采樣點完成3D LUT的構建而存在的局部非線性顏色變換建模能力不足的挑戰,我們提出基于采樣間距自適應學習的3D LUT方法來為上述挑戰提供一種先進的解決方案,即Adaptive Intervals Learning (AdaInt)。具體而言,我們提出并設計一種輕量緊支的三維顏色空間動態采樣間隔預測機制,作為3D LUT方法的一種即插即用模塊,自適應地根據輸入圖像內容預測3D LUT中稀疏采樣點的分布方式。通過提供給模型在三維顏色空間中自適應、非均勻采樣的能力,模型有望在需要較強非線性變換的顏色空間內分配更多的采樣點以提高3D LUT的局部非線性變換能力,在變換較為平坦的區域分配較少的采樣點以減少3D LUT的容量冗余,從而提高3D LUT方法的靈活性和圖像自適應性。
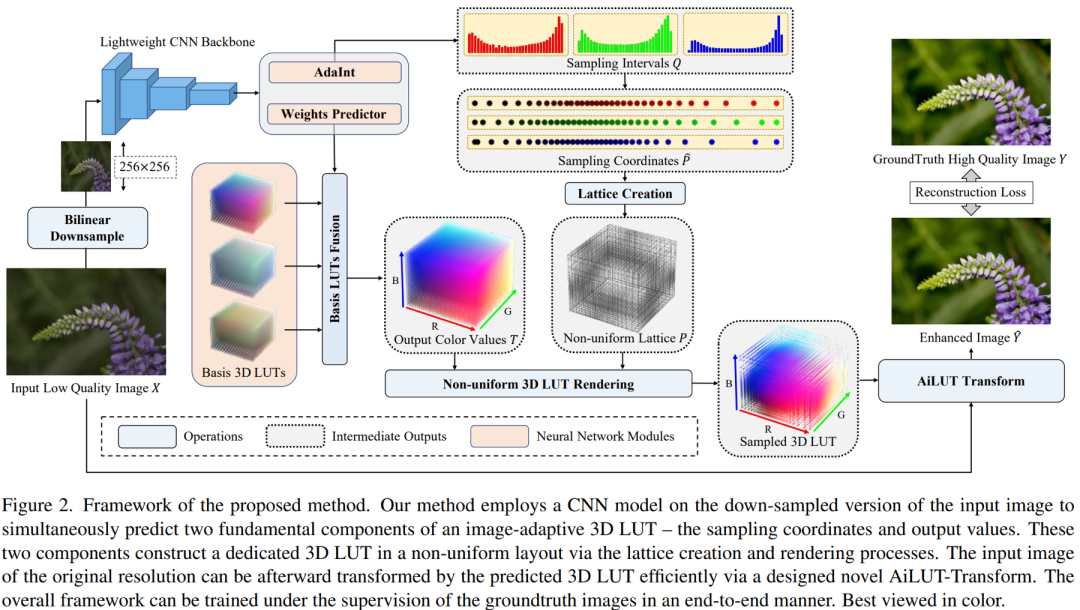
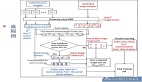
所提方法的整體模型框架如上圖所示。我們以待增強的圖像作為模型輸入,自動輸出經過顏色增強的高質圖像,并將輸出圖像與經過人為美化的目標圖像計算MSE重建損失,從而實現整個方法框架的端到端學習。
具體模型結構上,我們使用一個輕量的卷積神經網絡將下采樣到固定分辨率(256x256像素)的輸入圖像作為輸入,通過該網絡同時預測圖像自適應3D LUT的兩個核心組成部件——非均勻的輸入顏色采樣坐標和相應的輸出顏色值。
在3D LUT的輸出顏色值上,我們延續現有工作[2]采用的方式——通過網絡自動預測系數來針對每張圖像動態加權合并若干個可學習的Basis 3D LUTs,以避免直接回歸全部輸出顏色值所帶來的大量網絡參數和計算復雜度的引入。
對于非均勻輸入顏色采樣坐標,我們假設在查找過程中3D LUT的三個顏色維度是相互獨立的;通過這種方式,我們可以分別預測每個顏色維度的一維采樣坐標序列,并通過笛卡兒積(n-ary Cartesian Product)得到對應的三維采樣坐標。
這兩個組成部件組合在一起構成一個具有自適應、非均勻三維布局的3D LUT,它可以通過我們精心設計的一種稱為 AiLUT-Transform 的新型可微算子對原始輸入圖像進行高效的顏色變換和增強。具體而言,我們通過在標準的查找表變換的查找過程中引入低復雜度的二分搜索來確定輸入顏色在非均勻布局查找表中所在的網格,并通過推導偏微分為網絡自動預測的非均勻顏色采樣坐標提供梯度以進行端到端學習。
實驗結果
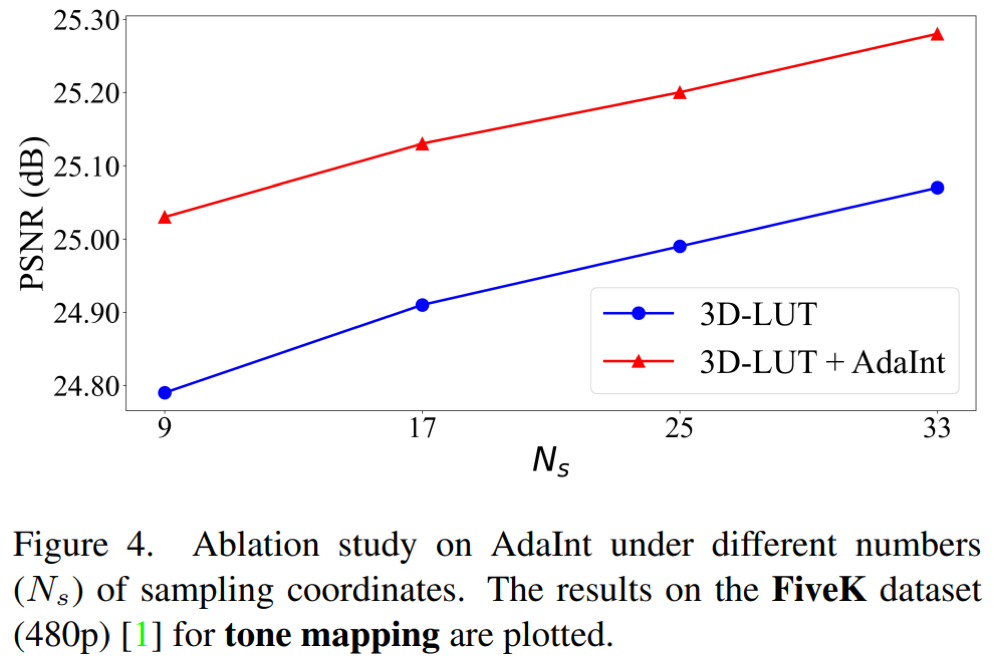
本文所提出的AdaInt模塊可以在可忽略不計的參數和計算量增加下顯著提高基線三維查找表方法的增強效果,如下圖所示。
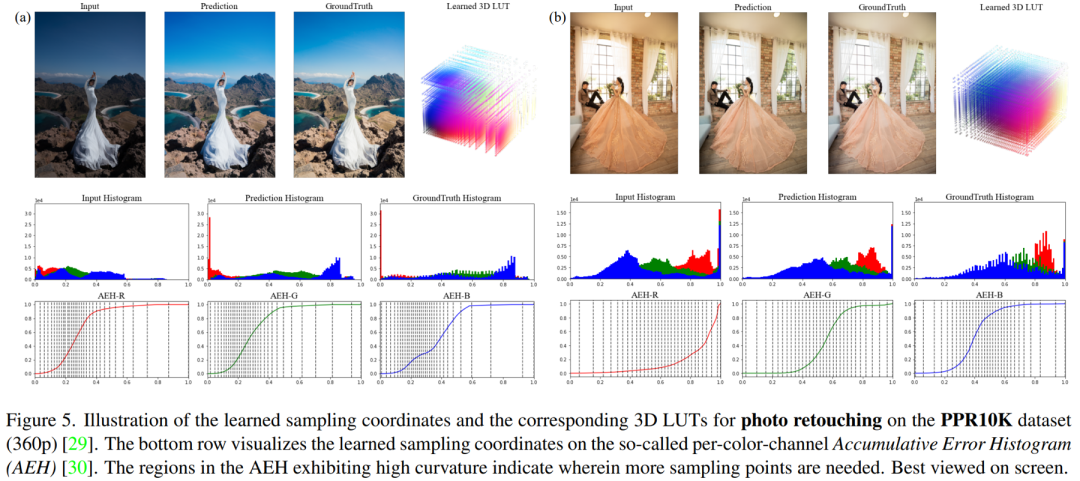
通過對不同輸入圖像可視化網絡學習得到3D LUTs,如下圖所示,我們可以觀察到針對曝光較弱(左子圖)和曝光較強(右子圖)的不同輸入圖像,網絡預測的采樣坐標(如第三行中豎線所示)分別聚集在了圖像的不同灰度值區域。這體現了所提方法如預期一般在大規模數據先驗中一定程度學習到了在三維顏色空間自適應采樣3D LUT的能力。
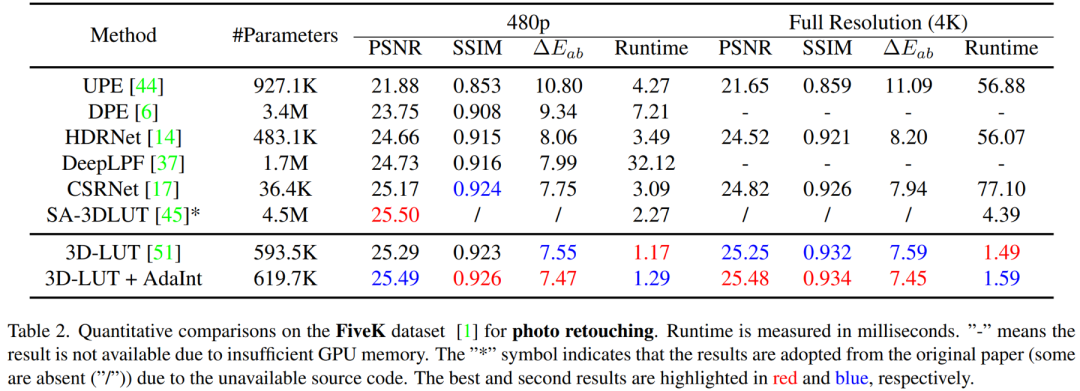
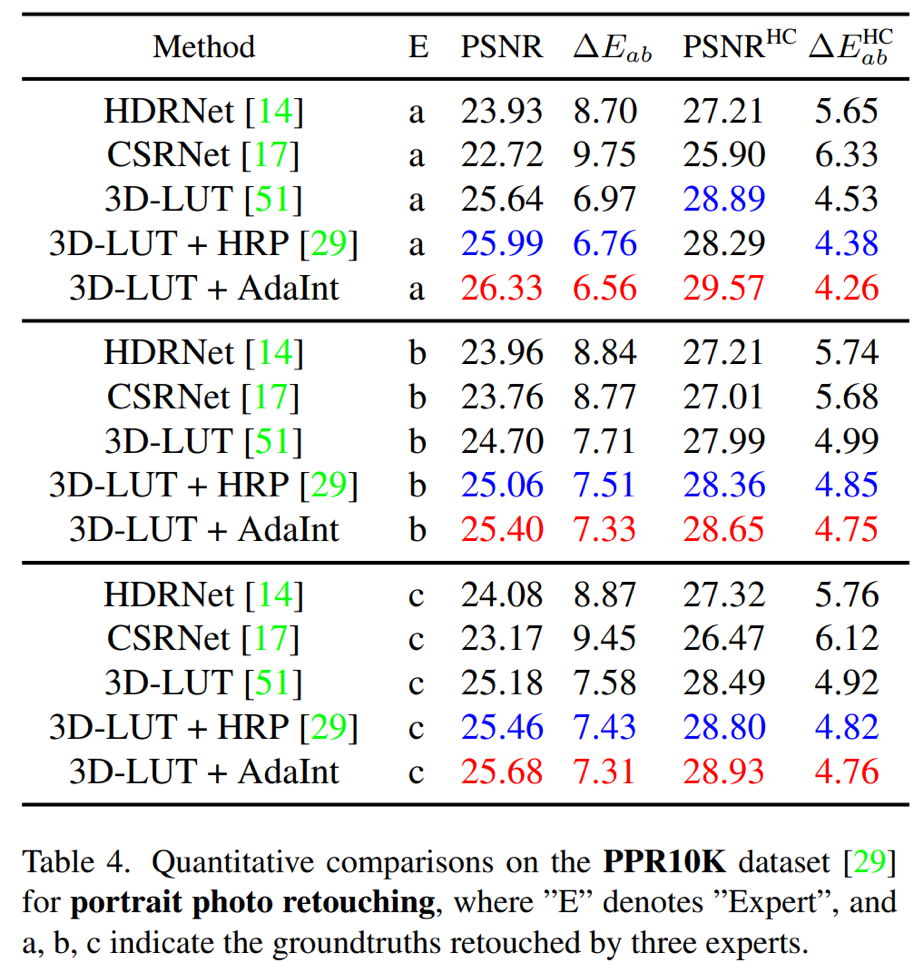
在兩個公開圖像增強/美化數據集FiveK和PPR10K上,所提方法以總體較低的參數量和實時推理時間在增強圖像的客觀評價指標上超過了現有方法,達到了先進性能。
總結
在本文中,我們簡要介紹了一種新穎的,可用于強化可學習 3D LUT 以進行實時顏色增強的學習機制——AdaInt。其中心思想是引入圖像自適應采樣間隔來學習非均勻的3D LUT布局。兩個公開數據集的實驗結果驗證了方法在性能和效率方面優于其他先進的現有方法。此外,作者相信本文方法中所蘊含的思想,即對復雜的底層變換函數或表示進行非均勻采樣的觀點不僅局限于 3D LUTs,也有望指導其他應用的改進,我們將其留作我們未來的工作。