













基于Python查找圖像中很常見的顏色
如果我們能夠得知道一幅圖像中最多的顏色是什么的話,可以幫助我們解決很多實際問題。例如在農(nóng)業(yè)領(lǐng)域中想確定水果的成熟度,我們可以通過檢查水果的顏色是否落在特定范圍內(nèi),來判斷它們是否已經(jīng)成熟。
接下來我們將使用Python和一些常用庫(例如Numpy,Matplotlib和OpenCV)來解決這個問題。
01. 準(zhǔn)備工作
第一步:添加程序包
我們將在此處加載基本軟件包。另外,由于我們要使用Jupyter進(jìn)行編程,因此小伙伴們不要忘記添加%matplotlib inline命令。
第二步:加載并顯示示例圖像
我們將并排顯示兩個圖像,因此我們需要做一個輔助函數(shù)。接下來我們將加載一些在本教程中將要使用的示例圖像,并使用上述功能對其進(jìn)行顯示。

02. 常用方法
方法一:平均值
第一種方法是最簡單(但無效)的方法-只需找到平均像素值即可。使用numpy的average功能,我們可以輕松獲得行和寬度上的平均像素值-axis=(0,1)
- img_temp = img.copy()
- img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = np.average(img, axis=(0,1))
- img_temp_2 = img_2.copy()
- img_temp_2[:,:,0], img_temp_2[:,:,1], img_temp_2[:,:,2] = np.average(img_2, axis=(0,1))
- show_img_compar(img, img_temp)
- show_img_compar(img_2, img_temp_2)

從上面圖像中可以看出,平均方法可能會產(chǎn)生錯誤結(jié)果,它給出的最常見的顏色可能并不是我們想要的顏色,這是因為平均值考慮了所有像素值。當(dāng)我們具有高對比度的圖像(一張圖像中同時包含“淺色”和“深色”)時這個問題會很嚴(yán)重。在第二張圖片中,這一點更加清晰。它為我們提供了一種新的顏色,該顏色在圖像中根本看不到。
方法二:最高像素頻率
第二種方法將比第一種更加準(zhǔn)確。我們的工作就是計算每個像素值出現(xiàn)的次數(shù)。numpy給我們提供了一個函數(shù)可以完成這個任務(wù)。但是首先,我們必須調(diào)整圖像數(shù)據(jù)結(jié)構(gòu)的形狀,以僅提供3個值的列表(每個R,G和B通道強度一個)。
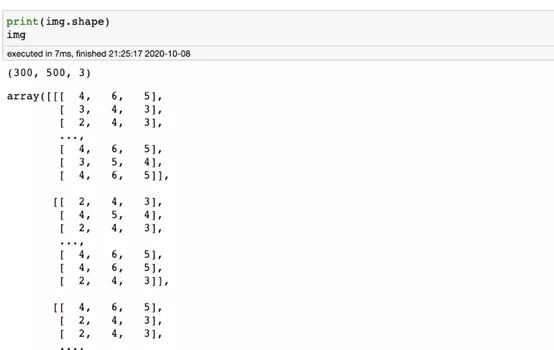
我們可以使用numpy的reshape函數(shù)來獲取像素值列表。
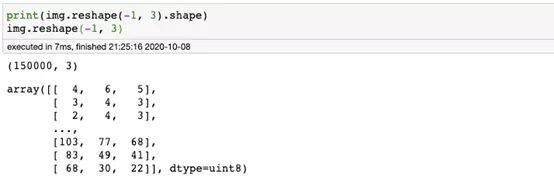
現(xiàn)在我們已經(jīng)有了正確結(jié)構(gòu)的數(shù)據(jù),可以開始計算像素值的頻率了,使用numpy中的unique函數(shù)即可。
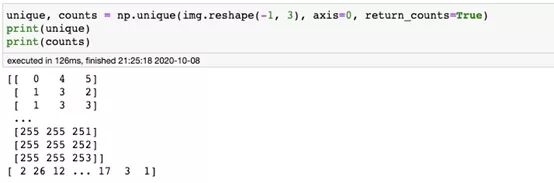
- img_temp = img.copy()
- unique, counts = np.unique(img_temp.reshape(-1, 3), axis=0, return_counts=True)
- img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = unique[np.argmax(counts)]
- img_temp_2 = img_2.copy()
- unique, counts = np.unique(img_temp_2.reshape(-1, 3), axis=0, return_counts=True)
- img_temp_2[:,:,0], img_temp_2[:,:,1], img_temp_2[:,:,2] = unique[np.argmax(counts)]
- show_img_compar(img, img_temp)
- show_img_compar(img_2, img_temp_2)

比第一個更有意義嗎?最常見的顏色是黑色區(qū)域。但是如果我們不僅采用一種最常見的顏色,還要采用更多的顏色怎么辦?使用相同的概念,我們可以采用N種最常見的顏色。換句話說,我們要采用最常見的不同顏色群集該怎么辦。
方法三:使用K均值聚類
我們可以使用著名的K均值聚類將顏色組聚類在一起。
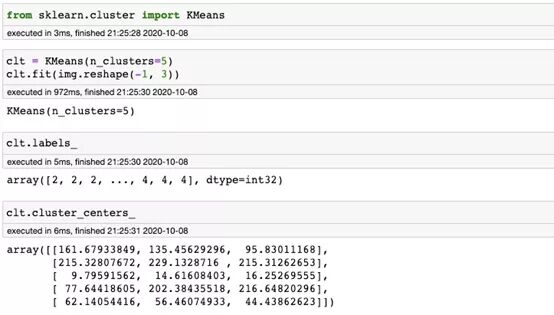
- def palette(clusters):
- width=300
- palette = np.zeros((50, width, 3), np.uint8)
- steps = width/clusters.cluster_centers_.shape[0]
- for idx, centers in enumerate(clusters.cluster_centers_):
- palette[:, int(idx*steps):(int((idx+1)*steps)), :] = centers
- return palette
- clt_1 = clt.fit(img.reshape(-1, 3))
- show_img_compar(img, palette(clt_1))
- clt_2 = clt.fit(img_2.reshape(-1, 3))
- show_img_compar(img_2, palette(clt_2))
容易吧!現(xiàn)在,我們需要的是一個顯示上面的顏色簇并立即顯示的功能。我們只需要創(chuàng)建一個高度為50,寬度為300像素的圖像來顯示顏色組/調(diào)色板。對于每個顏色簇,我們將其分配給我們的調(diào)色板。

是不是很漂亮?就圖像中最常見的顏色而言,K均值聚類給出了出色的結(jié)果。在第二張圖像中,我們可以看到調(diào)色板中有太多的棕色陰影。這很可能是因為我們選擇了太多的群集。讓我們看看是否可以通過選擇較小的k值來對其進(jìn)行修復(fù)。
- def palette(clusters):
- width=300
- palette = np.zeros((50, width, 3), np.uint8)
- steps = width/clusters.cluster_centers_.shape[0]
- for idx, centers in enumerate(clusters.cluster_centers_):
- palette[:, int(idx*steps):(int((idx+1)*steps)), :] = centers
- return palette
- clt_3 = KMeans(n_clusters=3)
- clt_3.fit(img_2.reshape(-1, 3))
- show_img_compar(img_2, palette(clt_3))

由于我們使用K均值聚類,因此我們?nèi)匀槐仨氉约捍_定適當(dāng)數(shù)量的聚類。三個集群似乎是一個不錯的選擇。但是我們?nèi)匀豢梢愿纳七@些結(jié)果,并且仍然可以解決集群問題。我們還如何顯示群集在整個圖像中所占的比例?
方法四:K均值+比例顯示
我們需要做的就是修改我們的palette功能。代替使用固定步驟,我們將每個群集的寬度更改為與該群集中的像素數(shù)成比例。
- from collections import Counter
- def palette_perc(k_cluster):
- width = 300
- palette = np.zeros((50, width, 3), np.uint8)
- n_pixels = len(k_cluster.labels_)
- counter = Counter(k_cluster.labels_) # count how many pixels per cluster
- perc = {}
- for i in counter:
- perc[i] = np.round(counter[i]/n_pixels, 2)
- perc = dict(sorted(perc.items()))
- #for logging purposes
- print(perc)
- print(k_cluster.cluster_centers_)
- step = 0
- for idx, centers in enumerate(k_cluster.cluster_centers_):
- palette[:, step:int(step + perc[idx]*width+1), :] = centers
- step += int(perc[idx]*width+1)
- return palette
- clt_1 = clt.fit(img.reshape(-1, 3))
- show_img_compar(img, palette_perc(clt_1))
- clt_2 = clt.fit(img_2.reshape(-1, 3))
- show_img_compar(img_2, palette_perc(clt_2))

它不僅為我們提供了圖像中最常見的顏色。這也給了我們每個像素出現(xiàn)的比例。
03. 結(jié)論
我們介紹了幾種使用Python以及最知名的庫來獲取圖像中最常見顏色的技術(shù)。另外,我們還看到了這些技術(shù)的優(yōu)缺點。到目前為止,使用k> 1的K均值找到最常見的顏色是找到圖像中最頻繁的顏色的最佳解決方案之一。





















