OpenHarmony啃論文俱樂部——物聯網搖擺門趨勢算法

【本期看點】
- Hadoop和Spark框架的性能優化系統。
- 云計算重復數據刪除技術降低冗余度。
- 壓縮框架Ares如何統一不同算法。
- 在線數據壓縮“搖擺門趨勢”。
- 揭秘新型移動云存儲SDM。
【技術DNA】
物聯網
什么是物聯網?物聯網是通過信息傳感設備,按照某種協議,把任何物品與互聯網連接起來,進行信息交換和通信,在這個網絡中,物與物之間能夠彼此進行“交流”,現實世界的物與數字世界相連,而無需人的干預,實現智能化。它的滲tou性強、帶動作用大、綜合效益好,能夠實現“物物相連的互聯網”,像智能家居、智能醫療、智能城市…
而由設備收集的數據的傳輸和存儲是物聯網(IoT)的重要組成部分。如今,數據生成的增長速度遠遠快于存儲能力。云計算可以以最小的管理工作快速啟動和供應,并為物聯網帶來巨大的優勢。但當傳輸無關或冗余數據時會消耗更多能,使用通信信道,處理對應用程序貢獻很小的數據,無疑是一種浪費。
壓縮傳輸和存儲的數據是必要的,所以提出了在物聯網應用中使用擺動門趨勢(SDT)。
擺動門趨勢(SDT)
擺動門趨勢(SDT)是一種在線有損數據壓縮算法,通常用于監看控制和數據采集系統,目的在于存儲來自過程信息系統的歷史數據。壓縮偏差(CD)是它最重要的參數,它代表當前樣本和當前用于表示之前收集的數據的線性趨勢之間的最大差異。
傳統SDT算法是在一定誤差范圍內,用起點和終點確定的直線代替兩點之間其他的數據點,SDT 算法的壓縮率關鍵取決于容差(門)的大小。而在起點上下距離為CD的地方有上邊界UP和下邊界LP,構成了旋轉的兩扇門。這兩扇門在壓縮過程中一旦打開之后就不能關閉,直到該壓縮區間壓縮結束。如果兩扇門的內角和大于或者等于180度,壓縮停止,否則壓縮繼續。該壓縮區間結束之后,以壓縮區間的終點為下一壓縮區間的起點繼續壓縮。
SDT結構簡單,計算復雜度較低,并且使用線性趨勢來表示一個數據量。通過帶有固定樞軸的“擺動門”連續構造圖形來過濾數據。但因為容差CD參數應該是預先運行時定義的“門”,所以有時候并不準確,后文將提出改進方法。
八個步驟
- 接收到第一點。
- 建立上下樞軸點。
- 接收下一點。
- 計算相對于上下樞軸的當前坡度。
- 比較當前坡度與之前的極端坡度。
- 當某個點在平行四邊形外時,計算最后一個點與當前點之間的斜率。交叉的邊界被調整為與其他邊界平行。計算出交叉邊界與斜率之間的一個攔截點,并確定一個新的第一點。
- 傳送點c作為輸出信號的壓縮數據流中的輸出點。
性能標準
壓縮誤差(CE)和壓縮率(CR)是評估壓縮算法性能的重要指標。
CE測量壓縮后觀察到的相對誤差量,它的計算方法是將未壓縮數據(Ti)與解壓縮過程(T0i)后的壓縮數據結果之間的差異的總和,除以未壓縮數據的絕對值的總和。
CR旨在評估壓縮過程的效率,并表示使用壓縮算法實現的樣本的減少。它被計算為壓縮樣本除以未壓縮樣本的補充。
提出稱為壓縮標準(CC),良好的壓縮體現于CC值接近于1,對應于高CR和低CE值。
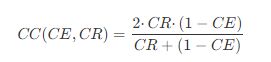
論文中提出4個不同數學方程版本:
算術平均值(MEAN):
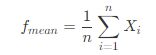
指數移動平均線:
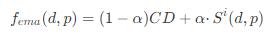
沒有零的平均數:
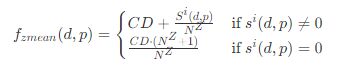
范圍:
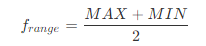
運用這四種方程式更方便找到最優解。
相關工作
這一部分介紹一些物聯網環境的數據壓縮算法以及SDT的更多內容。
物聯網中的數據壓縮
對物聯網輸入數據流的近似算法
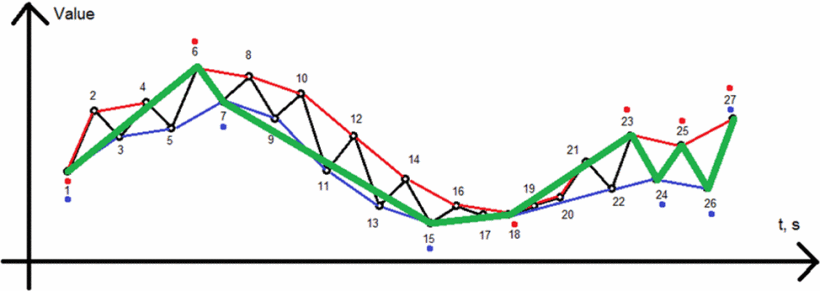
這個算法的主要的思想是利用數據中的一部分值去近似表示所有的數據。算法的特點是計算復雜度低,壓縮率高,但是錯誤率高。
下面結合原論文中的一組圖來直觀地感受算法的過程:
輸入一組具有相同時間間隔的離散時序數據,并按照時間將其從1開始編號。
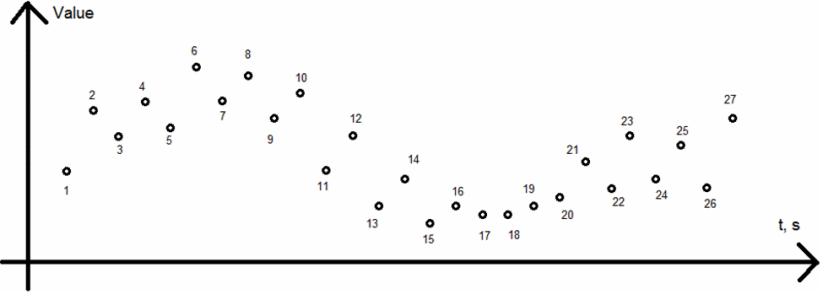
將上述編好號的數據分為“最大值”和“最小值”兩個部分,其中最大值的定義為比前一個數據大的值,最小值的定義為比前一個數據小的值,如果一個數據位于序列的開始或結尾或者與前一個數據的值相等,則可以同時標記為兩個狀態。
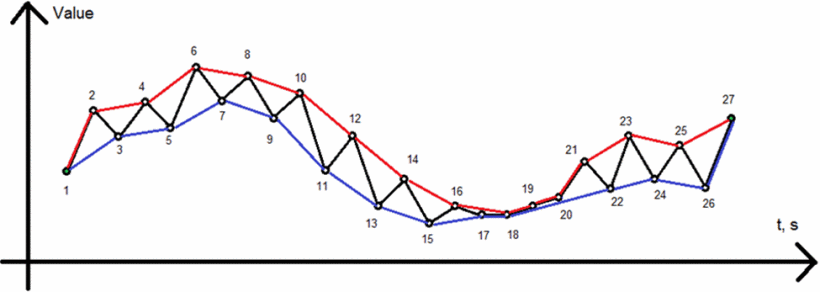
分別在“最大值”和“最小值”中找到它們對應的極值。
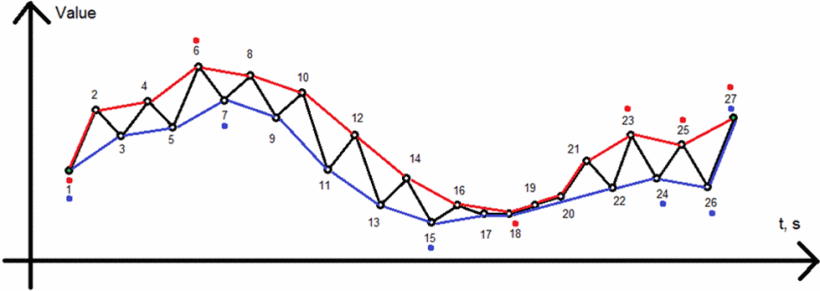
按順序連接“最大值”和“最小值”對應的極值點。
增量壓縮編碼方案
所謂增量,指的是一組數據中相鄰值之間的差,通過記錄一組差值和初始值即可表示整個數據。下面介紹基于增量壓縮的編碼方案,論文中的分析場景是一組溫度數據的壓縮。
數據特點:
傳感器通過ADC將現實世界中的溫度轉換為一個個離散的數據,而且這個數據是有限的,假設ADC可以將溫度映射到包含1024個值的集合,那么對應的某一時刻的溫度也即該時刻的狀態一定對應狀態空間S中的一個狀態。假設傳感器記錄溫度的頻率為f_sfs,則數據之間的時間間隔為T=1/f_sT=1/fs,我們用u(nT)\in S, n=0, 1, ..., \inftyu(nT)∈S,n=0,1,...,∞表示一組ADC的輸出,那么增量可以表示為\Delta(kT)=u[kT]-u[(k-1)T]Δ(kT)=u[kT]?u[(k?1)T],或者簡寫為\Delta(k)=u(k)-u(k-1)Δ(k)=u(k)?u(k?1),對一組增量進行統計分析:
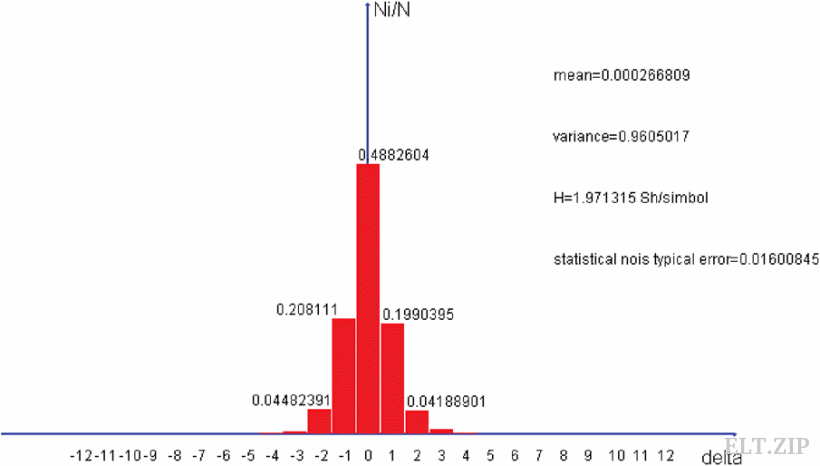
可以看出\DeltaΔ出現的頻率服從正態分布,而且-1、0、和1這三個值的頻率加起來接近0.9。參考Huffman編碼的思想,如果可以設計一套編碼方案,可以用較短的編碼代替出現頻率高的\DeltaΔ,那么可以達到比較好的壓縮效果。
增量壓縮:
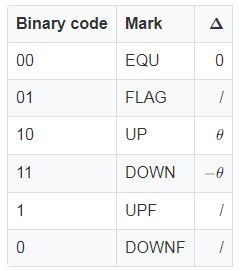
考慮到傳感器、ADC能夠檢測出的溫度的變化是有限的,即當數據變化量小于一個閾值\thetaθ時,可以認為它們是相等的。作者設計了六個基本的符號,其中三個可以直接表示\DeltaΔ的值為0,\theta,-\theta0,θ,?θ,剩余的三個符號需要結合起來表示\DeltaΔ的絕對值大于\thetaθ的情況:
表一 六個基本符號。
表二 \Delta的絕對值大于\theta的情況。
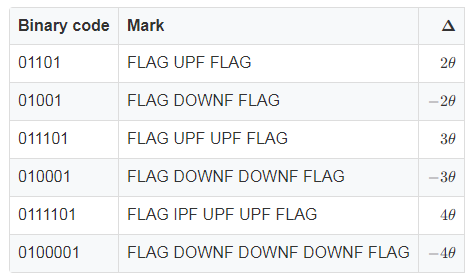
如果增量的絕對值超過一個閾值,那么采用FLAG+UPF/DOWNF+FLAG的方式表示增量的大小,其中UPF或者DOWNF的個數為abs(\Delta/\theta)-1abs(Δ/θ)?1。當增量很大時,數據不進行編碼,否則編碼后的比特數比原比特數還要大,但是這種情況出現的概率極低。
云存儲中物聯網傳感器數據的壓縮和存儲優化
在論文中作者提出一種用于 IoT 數據的兩層壓縮框架,該框架可減少數據量,同時保持最小錯誤率并且避免帶寬浪費。在該方案中,首先在霧節點以 50% 的壓縮率進行了初始壓縮,在云存儲中再將數據壓縮到了 90%。論文還表明解壓后誤差與原始數據相差 0% 到 1.5%。
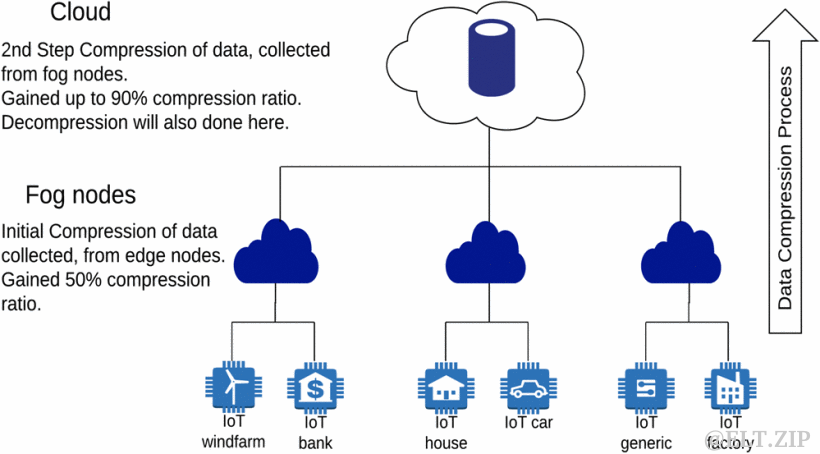
具體步驟為:
1、霧節點的壓縮。
a. 從傳感器節點接受一組數據。
b. 判斷傳感器節點是否注冊,如果是則進行下一步驟,否則拋棄數據。
c. 對數據進行升序排序,并且計算兩個連續值的平均值,通過此步驟將數據壓縮為原來的50%。
d. 將壓縮后的數據寫入文件發送到云端。
2、云壓縮。
a. 接受來自霧節點的數據文件。
b. 判斷霧節點是否注冊,如果是則進行下一個步驟,否則拋棄數據。
c. 從文件中讀取數據,然后統計每一個值出現的頻率,重新寫入文件,記錄為兩列,此時壓縮率達到90%。
例:數據由1到10的100個值組成,最終得到十個數和它們對應的頻率。
SDT
自適應SDT
自適應SDT(Adaptive Swinging Door Trending)基本過程與SDT相同,只是采用了自適應的壓縮偏差CD。通過使用指數移動平均(EMA)為過濾器分析數據。指數移動平均與線性移動平均不同的是可以在使數據趨于平滑的同時突出局部的變化,因此采用了加權平均,離當前時刻越近的值權重越大。
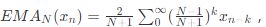 式中的N是需要人為設定的參數,所以ASDT的一個缺點在于需要提前設置EMA的參數。
式中的N是需要人為設定的參數,所以ASDT的一個缺點在于需要提前設置EMA的參數。
改進的SDT
改進的SDT(ISDT)的目標是1) 檢測并消除異常值,2) 采用自適應的壓縮偏差獲得更好的壓縮效果。
ISDT相比于之前提到的SDT多了強制存儲記錄限制(Forced Storage-Recording Limit, FSRL)和調整因子(adjustment factor, F_{adj}\in(0, 1)Fadj∈(0,1)),這兩個值是自適應調整壓縮偏差的關鍵。
ISDT檢測異常值
SDT算法結束當前壓縮區間、開啟新的壓縮區間的條件是最大上角(a_{umax})和最大下角(a_{lmax})最大上角(aumax)和最大下角(almax)之和大于等于180。在ISDT中,當一個數據值x_kxk滿足開啟新的壓縮區間時,并不會立即關閉當前區間,而是檢查下一個數據值x_{k+1}xk+1是否可以包含在當前的壓縮區間內。如果可以,則表明x_kxk是一個異常值,因此不記錄這個值,而是從x_{k+1}xk+1開始繼續當前壓縮區間。
ISDT自適應壓縮偏差
我們先理解FSRL,即強制存儲記錄限制,意思是當一個壓縮區間記錄k個值且k=FSRL時,即使下一個值可以包含在當前的區間內,但是強制關閉當前區間并以當前點為下一個區間的初始值。
如果一個區間在區間長度達到FSRL后被強制截斷,說明當前的壓縮偏差偏大或者數據處于穩定階段,那么可以用CD:=CD\times f_{adj}CD:=CD×fadj替換原來的壓縮區間;反之,如果在區間長度達到FSRL前關閉,說明當前壓縮偏差設置地偏小或者數據波動較大,這時可以用CD:=CD/f_{adj}CD:=CD/fadj替換原來的壓縮區間。
分布式SDT
支持智能電網的電力物聯網具有以下特點:
- 具有大量傳感器。
- 具有多種傳感器。
- 具有非常高的數據采集頻率。
- 具有高度異構的網絡。
正式因為由于上述特點,如果將傳感器收集的所有原始時間序列數據通過網絡傳輸到傳感數據中心,然后壓縮和保留,帶寬和計算網絡和傳感數據中心的資源需求分別是不可接受的。傳感器對原始傳感數據進行壓縮,然后將初始壓縮的數據傳輸到傳感數據中心,在傳感數據中心進一步壓縮和保留數據。這樣,網絡和傳感數據中心的帶寬和計算資源需求都會顯著降低。
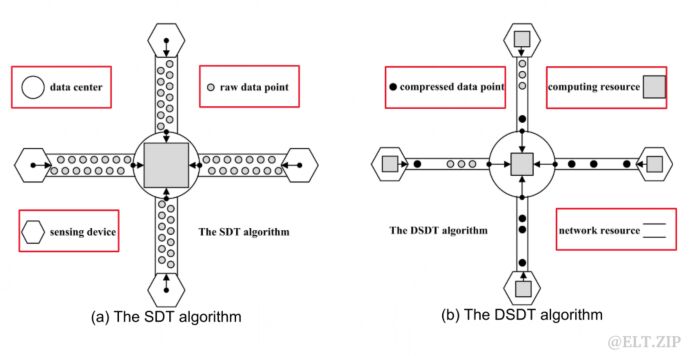
DSDT是傳統SDT的分布式版本,與上文提到的 IoT 數據的兩層壓縮框架類似,在傳感器節點壓縮數據可以減少傳輸的壓力。而且,由于SDT算法本身的優點,每次更新壓縮區間只需要確定一個初始點和壓縮偏差即可,所以可以實現壓縮中心轉移的操作,即壓縮中心在傳感數據中心和傳感器之間可以動態的變化,具體如何轉移取決于計算資源和帶寬資源的分配。下圖為SDT和DSDT區別的直觀解釋: