Redis 高可用之 Sentinel
Sentinel 結構

在 redis3.0 以前的版本要實現集群一般是借助哨兵 sentinel 工具來監控 master 節點的狀態,如果 master 節點異常,則會做主從切換,將某一臺 slave 作為 master,哨兵的配置略微復雜,并且性能和高可用性等各方面表現一般,特別是在主從切換的瞬間存在訪問瞬斷的情況,而且哨兵模式只有一個主節點對外提供服務,沒法支持很高的并發,且單個主節點內存也不宜設置得過大,否則會導致持久化文件過大,影響數據恢復或主從同步的效率。
Sentinel 初始化
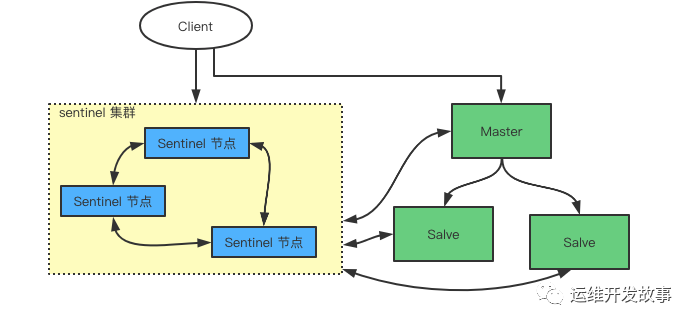
Sentinel(哨兵)是 Redis 高可用(high availability) 解決方案,由一個或者多個 Sentinel 實例(instance)組成的 Sentinel 系統(system)可以監視一個或者多個 Redis 主服務器和其跟隨的從服務器,并且在被監視的主服務進入下線狀態時,自動進行將當前主服務器的從服務器其中一個升級為主服務器,然后將下線的主服務器設置為新主服務器的從節點。
Sentinel 本身我們可以理解為一個特殊的 Redis 服務器, 它也可以通過 redis-server xxx.conf --sentinel啟動。
下面是我們實驗環境的一個 Sentinel 服務器和 Redis 服務器列表(由于實驗都在本機進行,我們采用端口的方式來區分多個服務),服務和端口大致如下:
IP | 端口 | 集群 |
127.0.0.1 | 6379 | Master |
127.0.0.1 | 6380 | Slave |
127.0.0.1 | 6381 | Slave |
127.0.0.1 | 26379 | Sentinel |
127.0.0.1 | 26380 | Sentinel |
127.0.0.1 | 26381 | Sentinel |
首先我們找到 Redis 的配置文件目錄,修改 redis-sentinel.conf文件中的以下參數:
# sentinel 端口
port 26381
# 后臺運行
daemonize yes
# 監控主服務器和有一個 slave 節點
sentinel monitor mymaster 127.0.0.1 6379 2
Sentinel 啟動命令如下:
redis-server redis-sentinel-26379.conf --sentinel
redis-server redis-sentinel-26380.conf --sentinel
redis-server redis-sentinel-26381.conf --sentinel
登錄到 Sentinel 節點, 查詢集群狀態, 使用 info命令即可。

sentinel 服務和其他 redis 服務節點啟動區別,就是在啟動的過程中,不會加載 RDB 或者 AOF 來還原數據。
Sentinel 和 Redis 服務之間的通訊
- _命令連接_,建立一個鏈接接收主/從服務器的回復 (默認 10 秒一次發送請求 info 信息獲取節點狀態,故障轉移的時候會變為 1 秒一次。并且每一秒向服務器節點發一個 PING 命令判斷服務是否在線)。

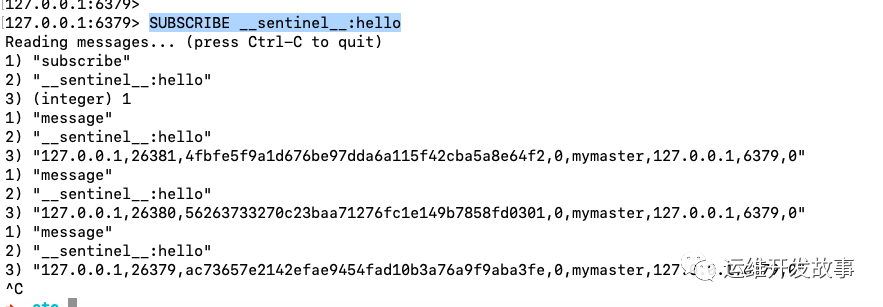
- 訂閱鏈接,用于訂閱主服務器的 __sentinel__:hello 頻道。
我們先驗證一下在主節點上查詢,執行 SUBSCRIBE __sentinel__:hello。
主節點服務上的同步信息,我們可以通過 INFO 命令來查詢。
從節點服務器上通過 INFO 命令查詢同步信息。

Sentinel 之間通訊
- 對于監視同一個主/從服務器的多個 Sentinel 節點,他們會以每兩秒一次的頻率,向被監視的服務器的 __sentinel__:hello 頻道發送消息來宣告自己存在。
- Sentinel 之間不會創建訂閱鏈接,通過命令通訊。因為已經可以通過主/從服務器獲取未知的 Sentinel 服務節點。
Sentinel 獲取 Redis 節點列表
** Sentinel 會默認 10 秒一次向主服務器信息,通過發送 info 命令**,的回復來獲取當前主服務器的信息。
# Server
run_id:5e4d6e3ee147ff231d540ae2add485e906944f2a
...
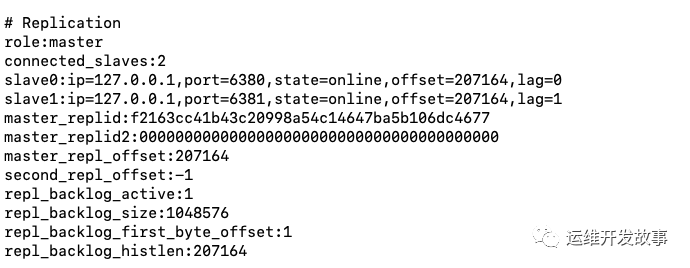
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=2712947,lag=0
slave1:ip=127.0.0.1,port=6380,state=online,offset=2712947,lag=0
master_replid:f2163cc41b43c20998a54c14647ba5b106dc4677
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2713213
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1664638
repl_backlog_histlen:1048576
....
通過分析主服務器的 info 命令可以獲取到以下兩方面的信息:
- 關于服務器本身的信息,包括 run_id 記錄服務器運行的 id, 以及服務器 role 角色等。
- 另外一方面就是獲取主服務器下面的所有從服務器信息,比如:slave0:ip=127.0.0.1,port=6381,state=online,offset=2712947,lag=0這樣就不需要我們在 conf 文件中配置從服務器的信息,Sentinel 可以自動發現。
當 Sentinel 從主服務器獲取到從服務器信息過后,也會 10 秒鐘向從服務器發送 INFO 命令來獲取從服務器信息 我們可以執行命令 redis-cli -h 127.0.0.1 -p 6380 info 得到以下信息:
# Server
run_id:7ef635af0d3e0b1d60d2776eba0a15883db06245
...
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:2779874
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:f2163cc41b43c20998a54c14647ba5b106dc4677
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2779874
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1731299
repl_backlog_histlen:1048576
...
我們從結果中可以得到以下信息:
- 服務器的運行 Id run_id。
- 服務器的角色 role。
- 主服務器的信息 master_host, master_port。
- 主從服務器的連接狀態 master_link_status。
- 從服務器的優先級 slave_priority。
- 從服務器的復制偏移量 slave_repl_offset。
服務下線
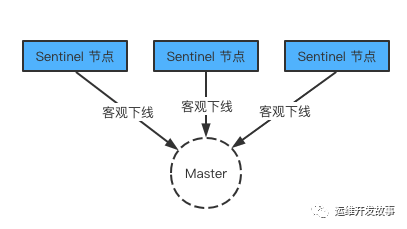
主觀下線:一臺 sentinel 判斷下線 客觀下線:主觀下線后會詢問其他的 sentinel 節點判斷是否該主節點下線,如果是真的下線了,那么就是客觀下線。
判斷下線的方式
sentinel 配置文件中 down-after-millseconds 選項制定了 sentinel 實例進入主觀下線所需的時間;如果一個實例在 down-after-millseconds毫秒內,連續向 Sentinel 返回無效回復,那么 Sentinel 會修改這個實例所對應的實例結構,在結構的 flags 屬性中打開 SIR_S_DOWN 標示,來表示這個實例主觀下線。當超過一半的哨兵節監測到一個redis 節點下線后此刻在該集群中該節點才算真正被判斷為下線,也叫客觀下線。
選舉領頭 sentinel
當發生 master 節點客觀下線后,會進行 sentinel 選舉,進行選舉出領頭 sentinel 對 redis sentinel 集群做故障轉移。領頭 sentinel 選舉規則:
- 所有在線的 sentinel 都具有選舉資格。
- 每次選舉后,不管是否選舉成功,sentinel 配置紀元(configuration epoch)都會自增一次。
- 每個配置紀元里面都有一次將某個 sentinel 設置為局部領頭 sentinel 的機會,且局部領頭 sentinel 一旦設置當前配置紀元里面不可修改。
- 每個發現主服務器客觀下線的 sentinel 都會要求其他的 sentinel 將自己設置為局部的 領頭 sentinel
- sentinel 局部領頭 sentinel 的規則是先到先的,最先向目標 sentinel 發送設置要求的 sentinel 先設置成功,之后的都會被拒絕。
- 如果某個 sentinel 被半數以上的 sentinel 設置成了局部領頭 sentinel ,那么這個 sentinel 就成為領頭 sentinel。
- 因為領頭 sentinel 產生需要半數的 sentinel 的支持,并且每個配置紀元里面只能設置一次 領頭 sentinel ,所以只會出現一個領頭 sentinel。
- 如果在指定的時間內沒有產生領頭 sentinel 那么就會進行再次選舉,直到選出領頭 sentinel 為止。
故障轉移
故障轉移分為三個步驟:
- 在已經下線的主服務器下的所有服務器里中,選擇一個從服務器,將器作為主服務器。
- 讓已經下線的主服務器下的所有從服務器復制新的主服務器。
- 將已經下線的主服務器設置為新主服務器的從服務器,當這個舊的主服務器重新上線后它就會成為新的主服務器的從服務器。
選擇新主服務器
- 對從服務器進行過濾。
- 刪除處于下線的從服務器,保證都是正常在線的。
- 刪除列表中所有 5 秒沒有回復過 sentinle leader 的 info 命令的服務器,可以保證列表中剩余的從服務器通訊正常。
- 保證從服務器的數據是最新的,主要是刪除與主服務器斷開鏈接超過 down-after-millseconds * 10 毫秒的服務器。保證沒有過早的斷開鏈接。
- 最后按照上面的篩選過后,進行排序,選擇其中優先級最高的。
1) 如果存在多個相同優先級的,考慮偏移量(slave_repl_offset)最大的從服務器,因為偏移量最大說明保存的數據是最新的。
2) 如果還是存在相同的偏移量的從服務器,那么就選擇運行 id(run_id)最小的從服務器。
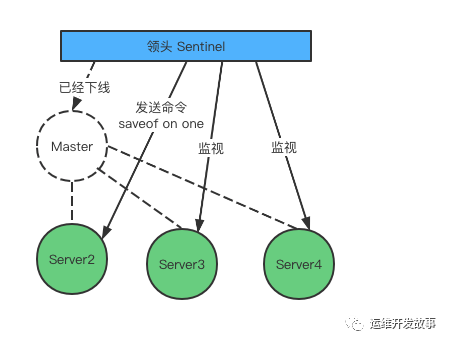
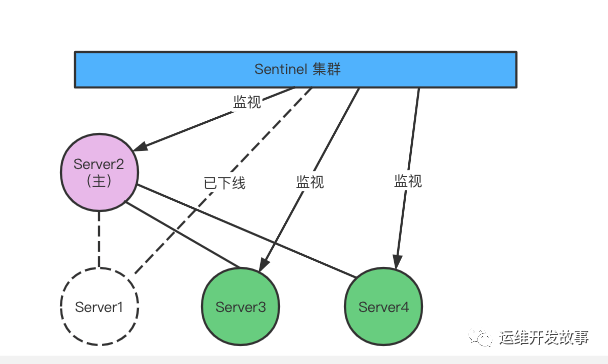
發生故障轉移后 Server2 升級為主服務器
修改從服務器的復制目標
當新的主服務器出現后 ,領頭的 Sentinel 會讓其他的服務器節點,去復制新的主節點的數據可以通過向從服務器發送 saveof 命令來實現。
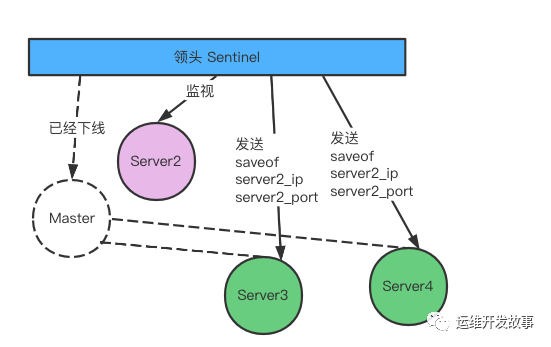
將舊的主服務器變成從服務器
故障轉移的最后操作,就是將已經下線的的主服務器設置為新的主服務的從服務器。