聊聊 Redis 高可用原理
大家好,我是樓仔!
Redis 的高可用,太重要啦!之前找工作面試,這個問題面試的頻率都能排到前幾,尤其是一些大廠,先不要著急看文章,如果面試官給你拋這么個問題,你會怎么回答呢,可以先想 5 分鐘。
這里要等待 5 分鐘 ...
其實我也可以偷個懶,完全轉載其它博客,但是沒有找到我想要的,為了不辜負廣大粉絲,樓哥還是單獨給大家寫一篇,主要根據這塊知識,再結合之前的一些面試情況,給大家嘮嘮。
1. Redis 分片策略
1.1 Hash 分片
我們都知道,對于 Reids 集群,我們需要通過 hash 策略,將 key 打在 Redis 的不同分片上。
假如我們有 3 臺機器,常見的分片方式為 hash(IP)%3,其中 3 是機器總數。

目前很多小公司都這么玩,上手快,簡單粗暴,但是這種方式有一個致命的缺點:當增加或者減少緩存節點時,總節點個數發生變化,導致分片值發生改變,需要對緩存數據做遷移。
那如何解決該問題呢,答案是一致性 Hash。
1.2 一致性 Hash
一致性哈希算法是 1997 年由麻省理工學院提出的一種分布式哈希實現算法。
環形空間:按照常用的 hash 算法來將對應的 key 哈希到一個具有 2^32 次方個桶的空間中,即 0~(2^32)-1 的數字空間中,現在我們可以將這些數字頭尾相連,想象成一個閉合的環形。

Key 散列 Hash 環:現在我們將 object1、object2、object3、object4 四個對象通過特定的 Hash 函數計算出對應的 key 值,然后散列到 Hash 環上。

機器散列 Hash 環:假設現在有 NODE1、NODE2、NODE3 三臺機器,以順時針的方向計算,將所有對象存儲到離自己最近的機器中,object1 存儲到了 NODE1,object3 存儲到了 NODE2,object2、object4 存儲到了 NODE3。

節點刪除:如果 NODE2 出現故障被刪除了,object3 將會被遷移到 NODE3 中,這樣僅僅是 object3 的映射位置發生了變化,其它的對象沒有任何的改動。

添加節點:如果往集群中添加一個新的節點 NODE4,object2 被遷移到了 NODE4 中,其它對象保持不變。

通過對節點的添加和刪除的分析,一致性哈希算法在保持了單調性的同時,還使數據的遷移達到了最小,這樣的算法對分布式集群來說是非常合適的,避免了大量數據遷移,減小了服務器的的壓力。
如果機器個數太少,為了避免大量數據集中在幾臺機器,實現平衡性,可以建立虛擬節點(比如一臺機器建立 3-4 個虛擬節點),然后對虛擬節點進行 Hash。
2. 高可用方案
很多時候,公司只給我們提供一套 Redis 集群,至于如何計算分片,我們一般有 2 套成熟的解決方案。
客戶端方案:也就是客戶端自己計算 Redis 分片,無論你使用Hash 分片,還是一致性 Hash,都是由客戶端自己完成。
客戶端方案簡單粗暴,但是只能在單一語言系統之間復用,如果你使用的是 PHP 的系統,后來 Java 也需要使用,你需要用 Java 重新寫一套分片邏輯。
為了解決多語言、不同平臺復用的問題,就衍生出中間代理層方案。
中間代理層方案:將客戶端解決方案的經驗移植到代理層中,通過通用的協議(如 Redis 協議)來實現在其他語言中的復用,用戶無需關心緩存的高可用如何實現,只需要依賴你的代理層即可。
代理層主要負責讀寫請求的路由功能,并且在其中內置了一些高可用的邏輯。

你可以看看,你們公司的 Redis 使用的是哪種方案呢?對于“客戶端方案”,其實有的也不用自己去寫,比如負責維護 Redis 的部門會提供不同語言的 SDK,你只需要去集成對應的 SDK 即可。
3. 高可用原理
3.1 Redis 主從
Redis 基本都通過“主 - 從”模式進行部署,主從庫之間采用的是讀寫分離的方式。

同 MySQL 類似,主庫支持寫和讀,從庫只支持讀,數據會先寫到主庫,然后定時同步給從庫,具體的同步規則,主要將 RDB 日志從主庫同步給從庫,然后從庫讀取 RDB 日志,這里比較復雜,其中還涉及到 replication buffer,就不再展開。
這里有個問題,一次同步過程中,主庫需要完成 2 個耗時操作:生成 RDB 文件和傳輸 RDB 文件。
如果從庫數量過多,主庫忙于 fock 子進程生成 RDB 文件和數據同步,會阻塞主庫正常請求。
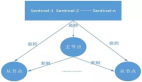
這個如何解決呢?答案是 “主 - 從 - 從” 模式。
為了避免所有從庫都從主庫同步 RDB 日志,可以借助從庫來完成同步:比如新增 3、4 兩個 Slave,可以等 Slave 2 同步完后,再通過 Slave 2 同步給 Slave 3 和 Slave 4。

如果我是面試官,我可能會繼續問,如果數據同步了 80%,網絡突然終端,當網絡后續又恢復后,Redis 會如何操作呢?
3.2 Redis 分片
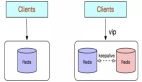
這個有點像 MySQL 分庫分表,將數據存儲到不同的地方,避免查詢時全部集中到一個實例。

其實還有一個好處,就是數據進行主從同步時,如果 RDB 數據過大,會嚴重阻塞主線程,如果用分片的方式,可以將數據分攤,比如原來有 10 GB 的數據,分攤后,每個分片只有 2 GB。
可能有同學會問,Redis 分片,和“主 - 從”模式有啥關系呢?你可以理解,圖中的每個分片都是主庫,每個分片都有自己的“主 - 從”模式結構。
那么數據如何找到對應的分片呢,前面其實已經講過,假如我們有 3 臺機器,常見的分片方式為 hash(IP)%3,其中 3 是機器總數,hash 值為機器 IP,這樣每臺機器就有自己的分片號。

對于 key,也可以采用同樣的方式,找到對應的機器分片號 hash(key)%3,hash 算法有很多,可以用 CRC16(key),也可以直接取 key 中的字符,通過 ASCII 碼轉換成數字。
3.3 Redis 哨兵機制
3.3.1 什么是哨兵機制 ?
在主從模式下,如果 master 宕機了,從庫不能從主庫同步數據,主庫也不能提供讀寫功能。

怎么辦呢 ?這時就需要引入哨兵機制 !
哨兵節點是特殊的 Redis 服務,不提供讀寫服務,主要用來監控 Redis 實例節點。

那么當 master 宕機,哨兵如何執行呢?
3.3.2 判斷主機下線
哨兵進程會使用 PING 命令檢測它自己和主、從庫的網絡連接情況,用來判斷實例的狀態,如果哨兵發現主庫或從庫對 PING 命令的響應超時了,哨兵就會先把它標記為“主觀下線”。
那是否一個哨兵判斷為“主觀下線”,就直接下線 master 呢?
答案肯定是不行的,需要遵循 “少數服從多數” 原則:有 N/2+1 個實例判斷主庫“主觀下線”,才判定主庫為“客觀下線”。

比如上圖有 3 個哨兵,有 2 個判斷 “主觀下線”,那么就標記主庫為 “客觀下線”。
3.3.3 選取新主庫
我們有 5 個從庫,需要選取一個最優的從庫作為主庫,分 2 步:
篩選:檢查從庫的當前在線狀態和之前的網絡連接狀態,過濾不適合的從庫;
打分:根據從庫優先級、和舊主庫的數據同步接近度進行打分,選最高分作為主庫。

如果分數一致怎么辦 ? Redis 也有一個策略:ID 號最小的從庫得分最高,會被選為新主庫。
當 slave 3 選舉為新主庫后,會通知其它從庫和客戶端,對外宣布自己是新主庫,大家都得聽我的哈!
今天就講這么多,我們下期見,大家都學廢了么 ?