













一日一技:如何從大量商品數據里面找到降價商品?
作者:kingname
每個商品每天都會爬一次,一共有61w+條數據。里面有N個商品降價了,現在需要把這些降價的商品找出來。
相信很多做爬蟲的同學都會爬電商網站,每天爬一次,然后監控商品是否降價。如果你只監控一個商品,那么是否降價這非常容易判斷,但如果你要找到這個網站里面所有降價的商品,那就非常麻煩了。
如下圖所示,是美國電商沃爾瑪的全站商品數據:

每個商品每天都會爬一次,一共有61w+條數據。里面有N個商品降價了,現在需要把這些降價的商品找出來。
商品有十幾萬個,如果你分別找到每個商品的ID,然后用ID再找到這個商品每一天的數據,最后看它是否降價,這個工作量非常大,速度也會非常慢。
Pandas內部使用了SIMB技術來對并行計算進行優化,我們需要盡量在不使用for循環的情況下,完成這個任務。
為了簡單起見,我們假設降價就是指今天比昨天的價格低,不考慮先漲價再降價的情況。
要解決這個問題,我們需要使用DataFrame的pct_change()方法。它就像是reduce一樣,給出一系列數據,它會計算數據改變量的百分比——第二條相對于第一條數據的改變,第三條數據相對于第二條數據的改變,第四條數據相對于第三條數據的改變。
首先我們使用date字段對數據進行排序,確保價格是按時間排列的。然后對商品的id進行分組,這樣就能拿到每一個商品每天的價格了。然后對price字段使用pct_change():
df2['pct'] = df2.sort_values(['date', 'id']).groupby(['id']).price.pct_change()
運行效果如下圖所示:
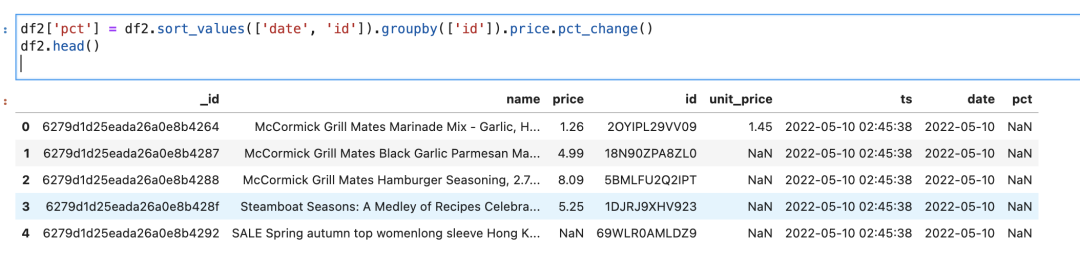
圖中最右側pct字段是NaN,是因為這是這些商品的第一條數據,所以始終是NaN.
我們篩選出今天(2022-05-16),pct小于0的商品:
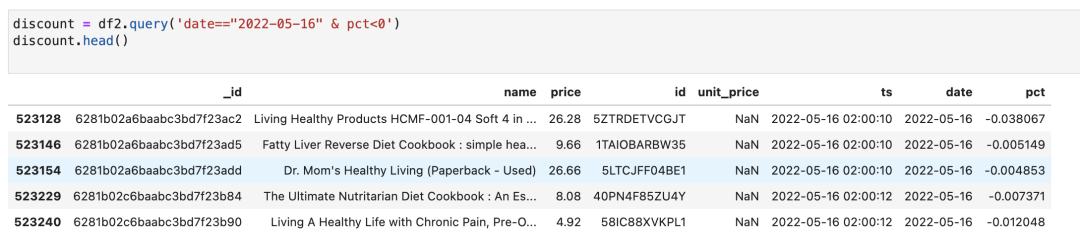
這些就是降價的商品了。我們可以隨便篩選一個商品來檢查一下:
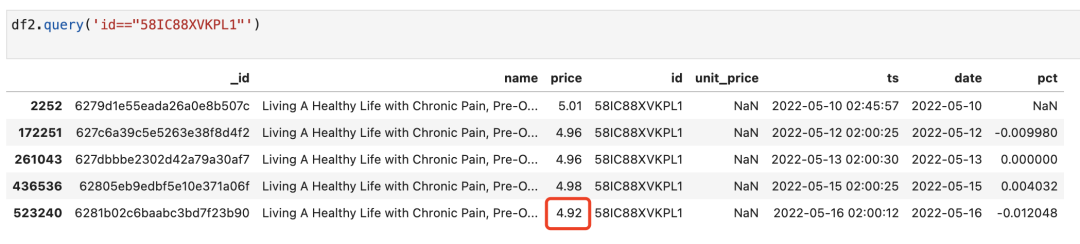
使用pct_change()速度非常快,60w數據幾乎秒出。比for循環快多了。
責任編輯:武曉燕
來源:
未聞Code























