再也不用敲SQL DDL了!數據湖時代Google的元數據自動管理技術
一、閱讀目的
目前不管是數倉、Lakehouse、數據湖都把開放數據湖中數據的分析作為當下的一個能力突破點。前面有看過論文“Data lake management: Challenges and opportunities”主要分析數據湖管理領域趨勢和挑戰(zhàn),里面有提到google的Goods在元數據管理方面做了不錯的工業(yè)實踐。
二、解決的核心問題(場景/技術)
1、Goods在Google元數據體系的位置
從Google bigquery相關資料可以看出google有一套統(tǒng)一的Data catalog,Goods可以理解是基于這套Data catalog基礎服務提供的面向數據湖場景元數據管理的完善能力。另外googole還有一篇論文“Big Metadata: When Metadata is Big Data”則是講在large scale表的元數據及統(tǒng)計信息管理的創(chuàng)新,也是基于Data catalog的工作,這篇文章的解析可以參考本公眾號的“Delta Lake&Hudi很火!Google更是Lakehouse的領跑者”文章。
2、Goods的場景定位
面向數據湖場景避免數據孤島,需要對數據進行統(tǒng)一的管理,而統(tǒng)一管理的可落地方式就是把元數據統(tǒng)一管理起來。Goods的定位不只做統(tǒng)一元數據服務,而是在元數據服務之上解決元數據上下游的處理,并支持用戶高效的從大量數據中找到自己需要的數據集。核心技術難點在于準確發(fā)現(xiàn)、大規(guī)模存儲、提供元數據查詢能力。
產生很多dataset的原因是為了快速的使用數據,來驅動他們的競爭優(yōu)勢,但是在存儲數據的時候沒有進行統(tǒng)一的元數據管理,這樣就只能事后進行元數據的管理。不改變原有使用元數據的方式,goods后臺執(zhí)行并采集元數據,并記錄和其他dataset之間的血緣關系,從而對外提供高效的元數據查詢服務。
三、論文內幕
本文的特點是方向新穎、問題開放,因此行文邏輯和其他論文有一些不同,側重在問題的定義。主要包括幾方面:挑戰(zhàn)、數據發(fā)現(xiàn)能力、后端存儲計算服務、查詢服務、相關工作及未來
1、挑戰(zhàn)
下面是整體的架構,可以看到goods支持多種數據源的元數據發(fā)現(xiàn)、對外提供豐富的數據管理能力。挑戰(zhàn)包括下面的:
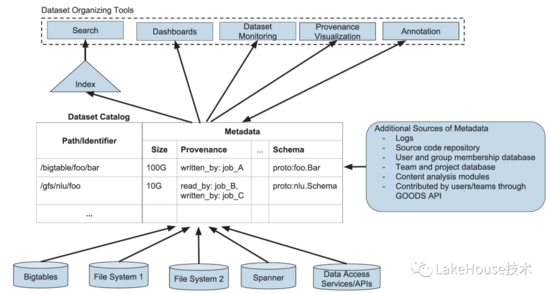
- 海量dataset的元數據發(fā)現(xiàn):支持google所有依賴的26 billion datasets的發(fā)現(xiàn),未來加速需要做dataset關聯(lián)的元數據推斷
- dataset多樣性:不同的數據源有不同的類型系統(tǒng),怎么做一套統(tǒng)一的元數據管理很有挑戰(zhàn)。比如bigtable的表需要按照列簇進行表的拆分
- dataset的TTL能力:因為元數據會有版本,全部保留數據量很大,因此需要有TTL的能力
- 后置元數據發(fā)現(xiàn)具有一定不確定性:利用dataset自包含的content和dataset本身的隱藏關系
- 計算dataset的重要性:通過比如計算訪問頻率,主動推理dataset對用戶的重要性
- 恢復dataset的語義:dataset的語義對于后續(xù)的查詢、搜索、描述更有意義
2、Goods數據發(fā)現(xiàn)能力
存儲的元數據包括從不同系統(tǒng)獲取的,goods彌補自由度和統(tǒng)一視圖之間的gap,同時具備對多個版本進行聚合處理的能力。
- 元數據
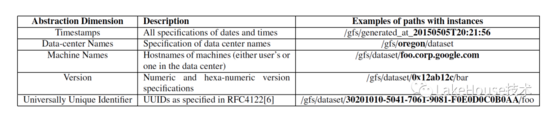
多種方式來爬取元數據并進行組裝,獲取的這些元數據不僅支持元數據恢復,同時能夠滿足數據的血緣和流動管理。goods支持構建一個圖來描述元信息之間的關系。發(fā)現(xiàn)元數據的手段包括:結構化的元數據都是使用pb來存儲、讀取一部分的數據來識別schema、使用一種算法識別潛在的key關鍵字、通過注釋來消除語義的歧義。
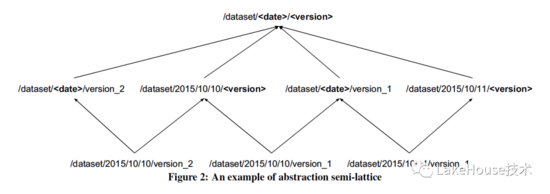
- 對數據進行聚集處理
按照邏輯集群級別進行聚集分類,分類后可以進行一些智能的schema推斷和傳播,從而減少schema推斷的開銷。
3、后端存儲計算服務
- Catalog storage:有特點的是支持dataset添加描述、以及一些維度的標簽信息
- 批處理作業(yè)性能及調度
后臺有分析生成元數據的作業(yè)、schema識別可能會比較久,做了一些同質元數據比如分區(qū)的元數據發(fā)現(xiàn)的數據裁剪
- 容錯:status的metadata里面存儲作業(yè)的運行狀態(tài),做了執(zhí)行作業(yè)的隔離
- 元數據的垃圾收集:這里主要是有一些TTL
4、查詢服務
- Dataset profile pages:支持dataset添加profile級別的配置,為了防止通過壓縮來減少使用空間。
- dataset 搜索:這里主要是一些索引相關
- 團隊報表:可以監(jiān)控dataset的屬性的變化
5、相關工作
業(yè)界工作:Goods的特點是管理海量數據湖的元數據,不需要元數據再創(chuàng)建的時候就進行預處理。與現(xiàn)有比如hive管理元數據,核心的區(qū)別就在與數據湖場景,以及事后的元數據發(fā)現(xiàn)。
未來工作包括:
- 對dataset的重要性進行標記還沒有完全做好
- 區(qū)分生產、測試、開發(fā)的datasets
- 整合更多的信息來做dataset的推理和管理
- 語義發(fā)現(xiàn)和識別
四、學習感悟
goods對于數據湖場景海量的數據集,進行元數據做事后的發(fā)現(xiàn)提取、收集、管理、查詢。這個和筆者前面在阿里云云原生數據湖分析做的數據湖管理的元數據發(fā)現(xiàn)工作基本是一致的,這塊工作對于數據湖場景有很大的價值,可以看出goods在數據集血緣、發(fā)現(xiàn)的規(guī)模、模糊數據集的準確性做了更加體系化的思考。