













作者 | 瞿勛和涂佳瑤
背景
項目的目標是為客戶交付一個ToC的APP,其后端是基于RESTful的微服務架構,同時后端還采用了Protobuf協議來提高傳輸效率。在最終上線之前,我們需要執行性能測試以確定系統在正常和預期峰值負載條件下的表現,從而識別應用程序的最大運行容量以及存在的瓶頸,并針對性能問題進行優化以提升用戶體驗。
性能測試是一個較為復雜的任務,包括確定性能測試目標,工具選擇,腳本開發,CI集成,結果分析,性能調優等過程,需要QA,Dev,Devops協力合作。本文將對這一系列過程進行詳細描述。

為什么選擇k6
在得知需要做性能測試后,我們就開始針對性能測試做了一番調研,在閱讀了一些性能測試工具對比的文章后,最終挑選了k6,locust和Gatling做了進一步對比,下面是對比的結果。
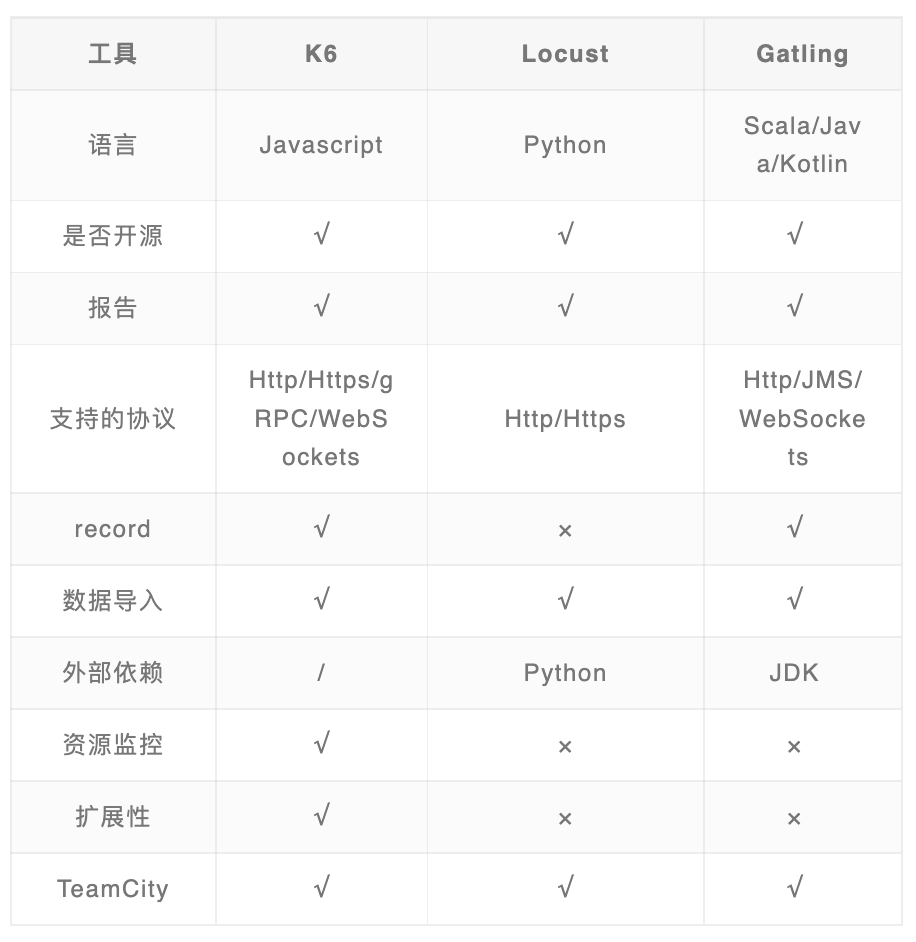
對我們來說,k6的優勢在于:
- k6支持TypeScript,由于項目上已經有TypeScript使用經驗,因此該工具學習成本相對更少;
- k6本身支持metrics的輸出,可以滿足大部分metrics的需求,有需要還可以進行自定義;
- k6官方支持與多種CI工具,數據可視化系統的集成,開箱即用;
- Gatling支持Scala/Java/Kotlin,項目上沒有使用相關的技術棧,需要和客戶申請,成本高于k6。
動手寫第一個case
有了上面的基礎,我們便開始嘗試在項目中集成k6,在選了一個簡單的API寫第一個case的時候,發現有以下一些挑戰需要解決:
挑戰1-獲取Access Token和保證token時效性
由于當前項目的API都集成了OAuth,任何操作都要有一個有效的用戶和Access Token,因此需要提前生成token和測試數據。這一部分因為項目的不同會有一些差異,需要具體情況具體分析。在此次測試中具體包括以下幾項:
- 用戶賬號準備,比如生成200個用戶,并進行一系列的前置處理,讓它們變成可用的正常測試賬號,并且需根據項目安全規范,保存到合適地方,比如AWS Secrets Manager或者AWS Parameter Store,這里的賬號可以復用。
- token生成,運行測試前,生成最新的有效token,執行測試的時候只需要去讀取token數據。
- token刷新,由于token基本上都具有時效性,如果有效時間短,還需要考慮renew token,這里我們采用refresh token去獲取新access token的方式。
- 需要注意的是測試過程中刷新token會計入請求,對性能測試數據會有些許影響,刷新機制需要納入考慮范圍。
挑戰2-Protobuf數據的編解碼
下圖簡要說明了前后端的架構,Mobile和BFF是以Protobuf格式做數據交換,BFF和Backend是以Json格式做數據交換。
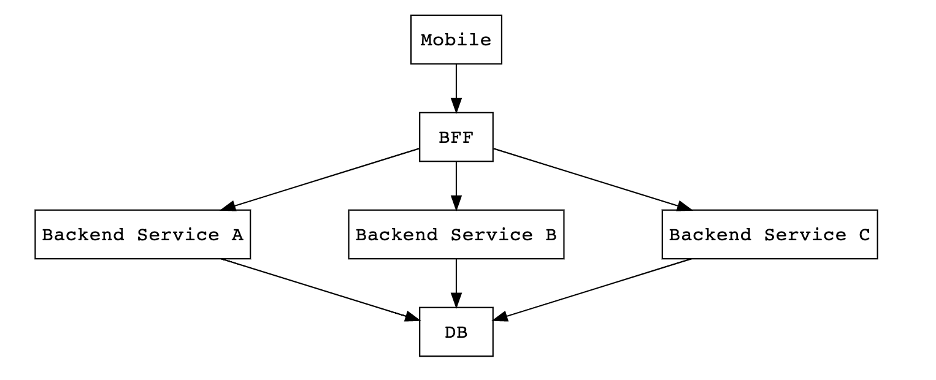
我們的性能測試是針對BFF的,因此需要根據項目中定義的Protobuf格式對請求數據進行編碼再發送給BFF,從BFF接受到響應數據時也需要根據Protobuf定義的響應格式進行解碼,從而解析出想要的數據。
另外由于性能測試采用的是TypeScript語言,我們還需要將Protobuf文件編譯成TS版本,這一點在Protobuf官方文檔上給出了解決辦法,可以很容易的生成TS版本代碼。
由于每個API的編解碼結構都是一份單獨的proto,因此還涉及到代碼復用的問題,需要設計合適的方法,讓不同的API只需要提供對應的encode和decode schema即可。
當解決掉前面的兩個挑戰后,可以初步得到符合項目需求的測試框架。
├── protobuf file/ --- protobuf文件
├── dist/ --- ts轉成js的測試文件
└── src/
├── command/ --- 一些腳本文件
├── config/ --- config文件
├── httpClient/ --- http client
├── ProtobufSchema/ --- 編譯好的protobuf文件
├── test/ --- 測試case
└── testAccount/ --- 測試賬戶
優化項目&集成CI&可視化報告
測試用例設計
當測試case逐漸增多后,我們對測試用例進行了多次的調整,例如對API進行了分類,并通過不同的方式來對他們進行性能測試。
獨立API
獨立API是指不依賴其他接口提供參數輸入,即可完成請求的API,例如部分Get類API。
非獨立API
非獨立API是指依賴于其他API結果作為參數輸入才可完成請求的API,例如部分Put、Delete類API。由于此類API依賴于其他API的結果數據,無法單獨做性能測試,在本次性能測試中以整體journey的形式來測這些非獨立的API,在測試case中將前一步的結果傳給后一步,從而完成整體的journey測試。
我們通過一個例子來說明,我們的test case目錄結構如下:
└── test
├── orderService
│ ├── createOrder
│ │ ├── createOrderRequestBuilder.ts
│ │ ├── createOrderRequestClient.ts
│ │ └── createOrderTest.ts
│ ├── getOrders
│ │ ├── getOrdersRequestClient.ts
│ │ └── getOrdersTest.ts
│ ├── orderJourney
│ │ └── orderJourneyTest.ts
│ └── updateOder
│ ├── updateOrderRequestBuilder.ts
│ └── updateOrderRequestClient.ts
├── payService
└── userService
其中:
- 對于createOrder,getOrders是獨立API,可以方便的進行單個API調用,直接進行測試即可;
- 對于updateOder,它依賴于createOrder的結果,所以我們將它們組合起來在Journey中測試,orderJourneyTest里面可以組合createOrder -> getOrder -> updateOrder。
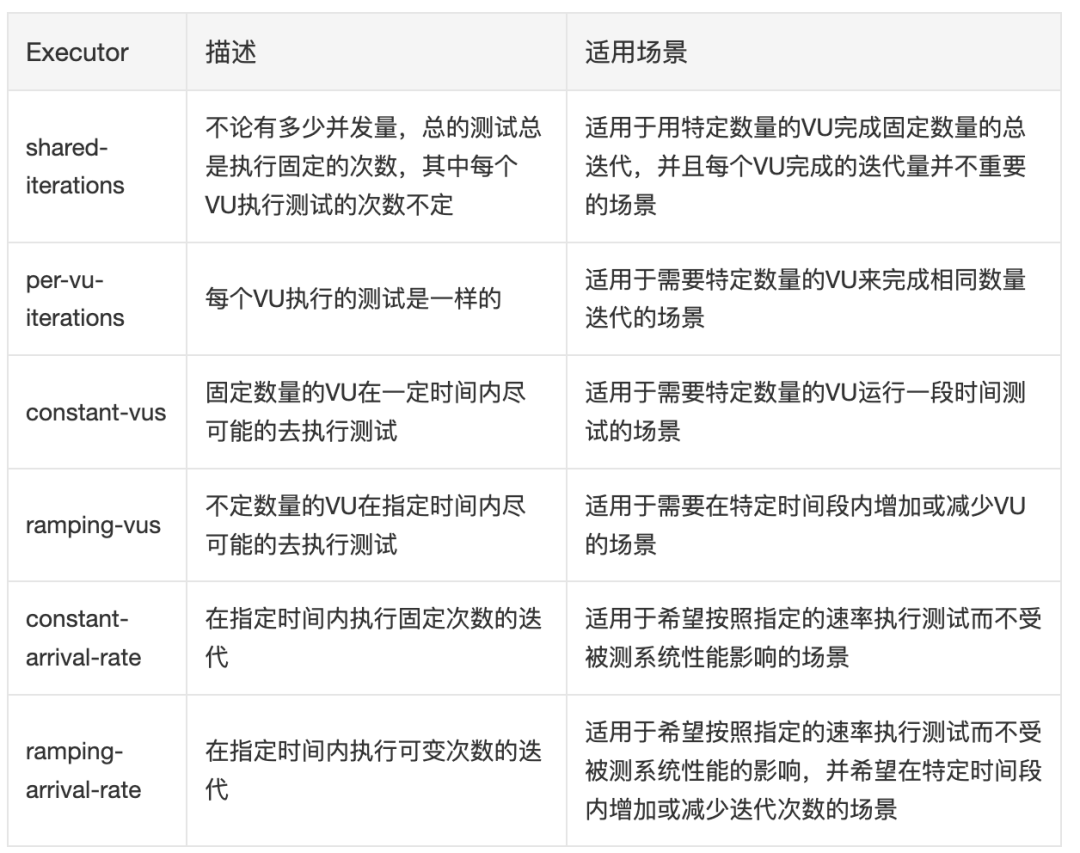
k6的executor選擇
k6提供了多個executor,不同的executor會以不同的方式去執行測試。我們可以根據項目的需求來選擇不同的executor來執行測試。

讓性能測試在CI上跑起來-集成TeamCity
k6官方提供了目前主流CI工具的How to文檔,非常容易上手。
唯一需要注意的點就是需要手動設置thresholds,當性能結果不達標時,k6會返回非0讓CI知道test失敗。
展示報告-集成New Relic
(1) 數據的采集
k6支持多種數據數據可視化工具,例如Datadog,New Relic,Grafana等,加個參數就可以輕松搞定。我們用的是New Relic,通過K6_STATSD_ENABLE_TAGS=true配置,可以方便的通過k6提供的tag進行數據分類,分類統計不同API,Journey的性能數據。
(2) 指標的展示
指標展示主要是在數據可視化平臺上,通過自定義各種圖表展示性能指標
(3) 指標的核對
這里其實是對上面的指標進行核對,以保證我們設置的指標是準確的,為后續性能分析做準備
測試執行&結果分析及調優
測試執行
在執行測試時,我們需要分析出影響性能的因素,并盡量控制變量,從而對多次的執行結果進行對比分析,例如都在pipeline上執行來減少網絡影響,定期檢查數據庫數據量,關注K8s的pod數量等等。結合我們的項目特點,我們總結了以下一些因素:
(1) 數據庫數據量
我們系統從架構上來比較簡單清晰,后端用到了AWS DynamoDB,所以數據量會對性能有較大的影響,特別是查詢類,計算類的API,這里就需要了解用戶各個維度的數據量,比如每個月,每天等。
(2) 請求的body大小
這主要是針對post和put類接口,因為涉及到文件上傳,所以文件大小也會對性能有較大影響,需要了解正常用戶使用場景下,附件的大小范圍
(3) K8s pod數量,開啟了HPA會觸發Auto Scaling
測試中發現性能不穩定,后來發現是UAT環境開啟了HPA會觸發Auto Scaling,所以在執行測試時,需要考慮不同的場景:
- 測試固定pod下的性能,方便優化對比性能
- 測試Auto Scaling的Policy有效性
(4) 網絡影響
這是一個比較通用的問題,測試時應注意網絡變化對性能指標的影響,防止變量太多,性能數據分析不準確
(5) 不同API的性能差距較大
這里主要是用例設計時需要考慮,k6會統計所有的請求數據,導致API之間會相互影響,數據失真:
- 比如token獲取的數據也會被收集,導致實際的業務接口數據受到影響;
- 再者像delete類的接口,對create有依賴,如果把兩個API一起測試,create API的性能數據與delete API差距較大,導致delete接口的數據嚴重失真。可以通過tag進行篩選,拿到單個API的部分數據,比如response time, 這種還是有意義的,像是rps這種數據,如果兩個一起跑的,主要還是取決于create,這樣收集到的rps對delete來說意義不大了。
(6) 多個后端API間的相互影響,例如文件上傳對性能的影響
由于我們是有BFF和BE,BFF會組合多個BE,所以需要識別多個BE之間的相互影響,盡量保證能準確的測試到目標,減少其他API的影響。比如在準備單獨測試某個服務時,可以考慮不添加文件,避免文件服務的干擾
結果分析及優化
對于結果分析來說,k6自身提供了豐富的Metrics可供查看,并且我們也集成了New Relic,因此可結合這兩者來進行數據收集,分析及調優。
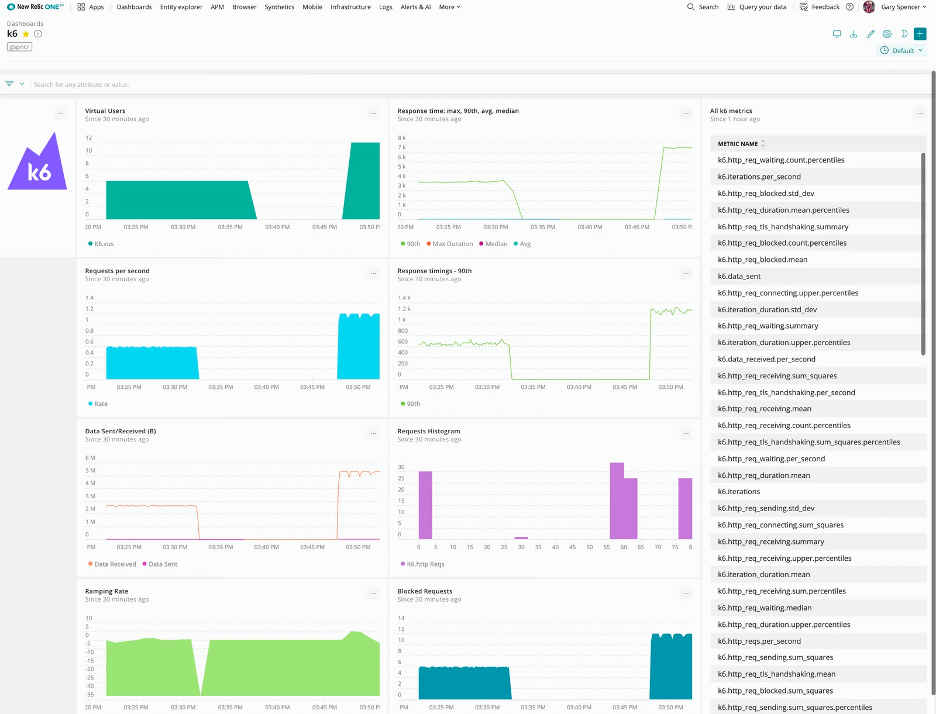
原圖鏈接:https://k6.io/docs/static/f9df206f5a86e9b4c59d2bdb6a9e351f/485a2/new-relic-dashboard.webp
如上圖所示,New Relic可以將收集到的數據以圖的形式展示出來,并且我們可以按照需求來定制化Report,這里不僅僅可以用k6收集的數據,還可以疊加一些APM的數據,比如CPU,Memory,Pod數量等信息。通過鼠標定位橫坐標上的某一個點,可以清晰的看到該時刻對應的并發量,總請求數,響應時間,失敗率等等數據。
另外,在執行測試時,我們通過在控制變量的前提下,進行橫向對比,將同類API在相同的配置下,對性能數據進行比較,如果數據相差明顯,則可以進一步調查。也可以通過工具對請求進行深入調查,拆解請求中各個模塊的耗時,找到最終的原因。
這里舉兩個例子來說明這個過程。
案例1 - 某獲取配置類信息API
此API邏輯比較簡單,主要是讀取一些配置信息,然后做一些簡單的處理返回即可。
運行完測試后,http_req_duration的平均值大概在1s左右,平均rps在108左右,而且VU最高達到了300,說明此時已經拉滿了用戶,還有0.7%的錯誤。而其他需要查詢數據庫的API同樣的設置下,http_req_duration只有23ms,rps有204,VU最高才到76。這個API只是取一些配置信息,沒有其他太復雜的操作,也不用訪問數據庫,顯然這個性能數據是異常的,于是拉著Dev一起先排查一下邏輯,發現是配置文件內容的緩存邏輯有問題,每次請求都會去讀配置文件,導致性能數據異常。
在修改完之后,相同配置下,http_req_duration為12ms,平均rps為145,VU最高為50,錯誤率為0,很顯然,這個數據說明我們還可以繼續加大Rate,當把Rate加到500時,平均的http_req_duration依舊是12ms,VU最大也才80,依舊沒有到達瓶頸,由此可見修改后性能提升非常明顯。
案例2 - 某getAPI
這個API是一個get類型的API,職責是去數據庫中獲取一個值,沒有其他額外操作。
運行完測試后,http_req_duration的平均值大概在320ms左右,橫向對比其他get API能夠發現duration的結果是非常不合理的。但是k6只給出最后的運行結果,我們無法從這些結果中得知具體的問題在哪。好在new relic上提供了一些具體的API信息,其中有一項中提供了API的詳細調用流程,以及每一流程中花費的具體時間。由于項目安全需要,這里以new relic提供的圖為例。
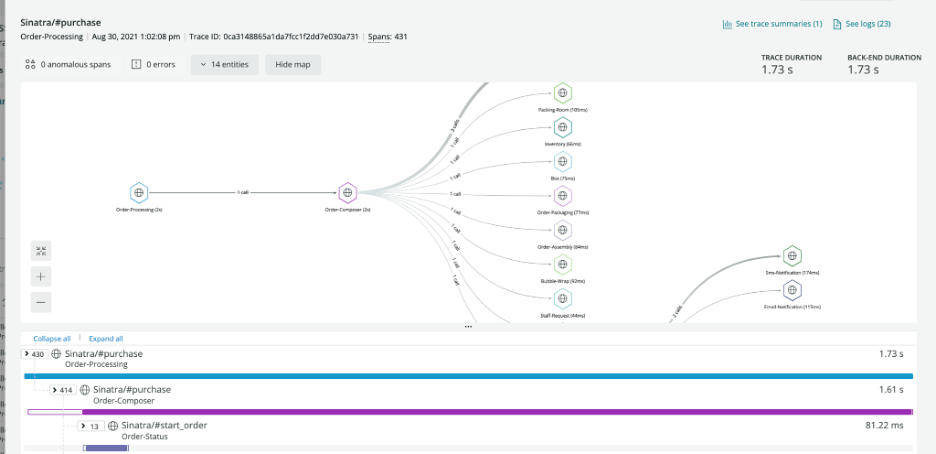
原圖鏈接:https://docs.newrelic.com/static/distributed-tracing-trace-details-page-1c064ef6a7607f95be583786b6af9251.png
從圖中,可以清楚的看到API的service調用流程圖,以及與不同的service互相call的個數。并還能清楚地看到每一步花費的時間,從而找到最費時間的那一步調用。
最后根據這個圖,我們發現原本只是去數據庫取一個值回來,卻由于實現方式不對,導致了和數據庫之間產生了200多個call。這才使得response time高達320ms。經過重新編碼后,該API的response time降到了20ms,性能提升了15倍。
寫在最后
此次性能測試復雜度較高,非一兩人之力能夠完成,作為QA,我們可以主導事情的發生,并成為其中的主力承擔者,要及時提出問題和尋求幫助,通過團隊的協作,讓問題盡快得到解決,最終順利完成性能測試任務。


















