Apache Kylin 歷險記
1. Kylin 概述
1.1 Kylin 定義
Apache Kylin(麒麟)是一個開源的分布式分析引擎,提供Hadoop/Spark之上的SQL查詢接口及多維分析(OLAP)能力以支持超大規模數據,最初由eBay Inc開發并貢獻至開源社區。它能在亞秒內查詢巨大的Hive表。
官網:https://kylin.apache.org/cn
1.2 Kylin特點
Kylin的主要特點包括支持SQL接口、支持超大規模數據集、亞秒級響應、可伸縮性、高吞吐率、BI工具集成等。
- 標準SQL接口:Kylin是以標準的SQL作為對外服務的接口。
- 支持超大數據集:Kylin對于大數據的支撐能力可能是目前所有技術中最為領先的。早在2015年eBay的生產環境中就能支持百億記錄的秒級查詢,之后在移動的應用場景中又有了千億記錄秒級查詢的案例。
- 亞秒級響應:Kylin擁有優異的查詢相應速度,這點得益于預計算,很多復雜的計算,比如連接、聚合,在離線的預計算過程中就已經完成,這大大降低了查詢時刻所需的計算量,提高了響應速度。
- 可伸縮性和高吞吐率:單節點Kylin可實現每秒70個查詢,還可以搭建Kylin的集群。
- BI工具集成,Kylin可以與現有的BI工具集成,具體包括如下內容。
ODBC:與Tableau、Excel、PowerBI等工具集成ODBC:與Tableau、Excel、PowerBI等工具集成
JDBC:與Saiku、BIRT等Java工具集成
RestAPI:與JavaScript、Web網頁集成
Kylin開發團隊還貢獻了Zepplin的插件,也可以使用Zepplin來訪問Kylin服務。
1.3 預備知識
1.3.1 Data Warehouse(數據倉庫)
數據倉庫是一個各種數據 (包括歷史數據和當前數據)的中心存儲系統,是 BI (business intelligence ,商業智能) 的核心部件。
1.3.2 事實表 & 維表
在維度建模中,將度量稱為“事實” ,將環境描述為“維度”。維度是用于分析事實所需要的多樣環境。例如,在分析交易過程時,可以通過買家、賣家、商品和時間等維度描述交易發生的環境。事實則緊緊圍繞著業務過程來設計,通過獲取描述業務過程的度量來表達業務過程,包含了引用的維度和與業務過程有關的度量。例如訂單作為交易行為的核心載體,直觀反映了交易的狀況。訂單的流轉會產生很多業務過程,而下單、支付和成功完結三個業務過程是整個訂單的關鍵節點。獲取這三個業務過程的筆數、金額以及轉化率是日常數據統計分析的重點,事務事實表設計可以很好地滿足這個需求。
1.3.3 維度
即觀察數據的角度。比如員工數據,可以從性別角度來分析,也可以更加細化,從入職時間或者地區的維度來觀察。維度是一組離散的值,比如說性別中的男和女,或者時間維度上的每一個獨立的日期。因此在統計時可以將維度值相同的記錄聚合在一起,然后應用聚合函數做累加、平均、最大和最小值等聚合計算。
1.3.4 度量
即被聚合(觀察)的統計值,也就是聚合運算的結果。比如說員工數據中不同性別員工的人數,又或者說在同一年入職的員工有多少。
1.3.5 Business Intelligence (商業職能)
商業智能通常被理解為將企業中現有的數據 轉化為知識,幫助企業做出明智的業務經營決策的工具。為了將數據轉化為知識,需要利用數據倉庫 、聯機分析處理( OLAP )工具和數據挖掘等技術。
1.3.6 OLAP(online analytical processing)
OLAP是一種軟件技術,它使分析人員能夠迅速、一致、交互地 從各個方面觀察信息 ,以達到深入理解數據的目的。從各方面觀察信息,也就是從不同的維度分析數據,因此 OLAP 也成為 多維分析。
1.3.7 ROLAP & MOLAP
ROLAP : 基于關系型數據庫,不需要預計算。
MOLAP:基于多維數據集(一個多維數據集稱為一個OLAP Cube),需要預計算。
1.3.8 Cube & Cubeid
有了維度跟度量后就有了根據維度和度量做預計算的Cube理論。給定一個數據模型,我們可以對其上的所有維度進行聚合,對于N個維度來說,組合的所有可能性共有2n種。對于每一種維度的組合,將度量值做聚合計算,然后將結果保存為一個物化視圖,稱為Cuboid。所有維度組合的Cuboid作為一個整體,稱為Cube。
1.3.9 星型模型
當所有維表都直接連接到事實表上時,整個圖解就像星星一樣,故將該模型稱為星型模型。該模型通過大量的冗余來提升查詢效率,對OLAP場景較友好。
當有一個或多個維表沒有直接連接到事實表上,而是通過其他維度表連接到事實表上時,其圖解就像多個雪花連接在一起,故稱雪花模型。該模型在MySQL、Oracle中常見。
當有一個或多個維表沒有直接連接到事實表上,而是通過其他維度表連接到事實表上時,其圖解就像多個雪花連接在一起,故稱雪花模型。該模型在MySQL、Oracle中常見。
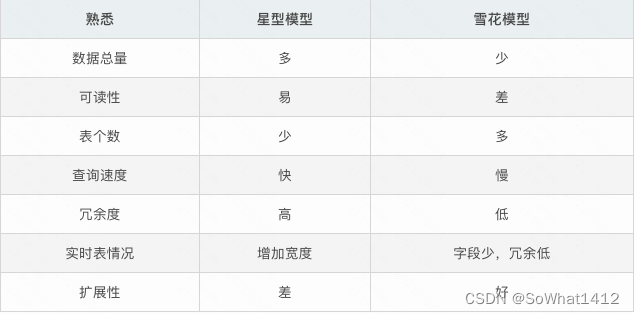
星型模型 VS 雪花模型
2 Kylin架構
2.1 核心架構
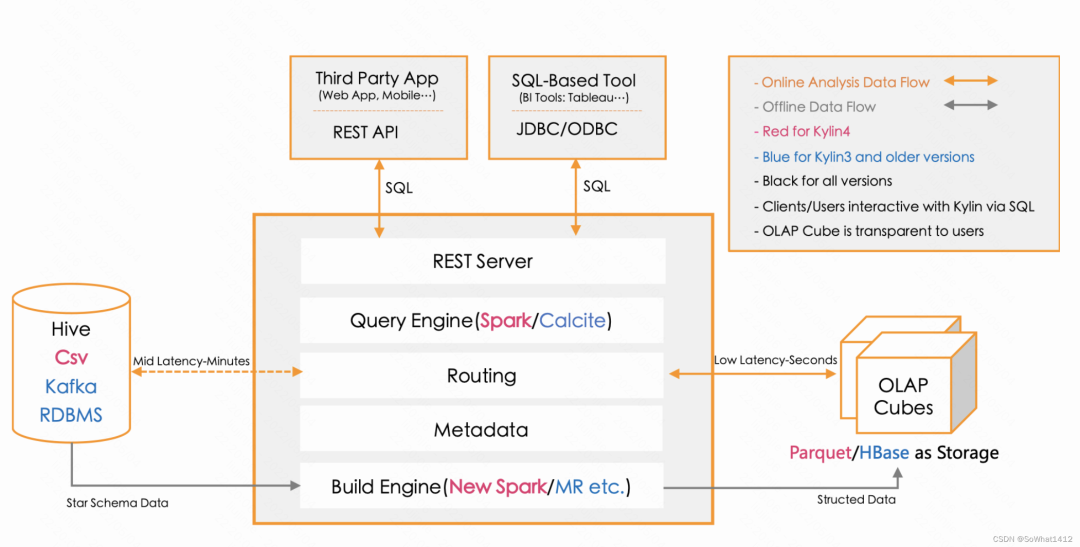
Kylin官方架構圖
2.1.1 REST Server
REST Server是一套面向應用程序開發的入口點,旨在實現針對Kylin平臺的應用開發工作。此類應用程序可以提供查詢、獲取結果、觸發Cube構建任務、獲取元數據以及獲取用戶權限等等。另外可以通過Restful接口實現SQL查詢。
2.1.2 查詢引擎(Query Engine)
當Cube準備就緒后,查詢引擎就能夠獲取并解析用戶查詢。它隨后會與系統中的其它組件進行交互,從而向用戶返回對應的結果。查詢SQL轉化為底層任務, 數據存儲到HBase。
2.1.3 Routing
負責將解析的SQL生成的執行計劃轉換成Cube緩存的查詢,Cube是通過預計算緩存在hbase中,這部分查詢可以在秒級設置毫秒級完成,而且還有一些操作使用過的查詢原始數據(存儲在Hadoop的HDFS中通過Hive查詢)。這部分查詢延遲較高(為避免查詢原始數據,默認關閉)。
2.1.4 元數據管理工具(Metadata)
Kylin是一款元數據驅動型應用程序。元數據管理工具是一大關鍵性組件,用于對保存在Kylin當中的所有元數據進行管理,其中包括最為重要的Cube元數據。其它全部組件的正常運作都需以元數據管理工具為基礎。Kylin的元數據存儲在Hbase中。
2.1.5 任務引擎(Cube Build Engine)
這套引擎的設計目的在于處理所有離線任務,其中包括Shell腳本、Java API以及Map Reduce任務等等。任務引擎對Kylin當中的全部任務加以管理與協調,從而確保每一項任務都能得到切實執行并解決其間出現的故障。
2.2 核心算法
2.2.1 工作原理
Kylin的工作原理就是對數據模型做Cube預計算,并利用計算的結果加速查詢:
- 指定數據模型,定義維度和度量;
- 預計算Cube,計算所有Cuboid并保存為物化視圖,預計算過程是Kylin從Hive中讀取原始數據,按照我們選定的維度進行計算,并將結果集保存到Hbase中,默認的計算引擎為MapReduce,可以選擇Spark作為計算引擎。一次build的結果,我們稱為一個Segment。構建過程中會涉及多個Cuboid的創建,具體創建過程由kylin.Cube.algorithm參數決定,參數值可選 auto,layer 和 inmem, 默認值為 auto,即 Kylin 會通過采集數據動態地選擇一個算法 (layer or inmem),如果用戶很了解 Kylin 和自身的數據、集群,可以直接設置喜歡的算法。
- 執行查詢,讀取Cuboid,運行,產生查詢結果。
2.2.2 構建方法
主要有逐層構建算法、快速構建算法 兩種。
2.2.2.1 逐層構建算法(layer)
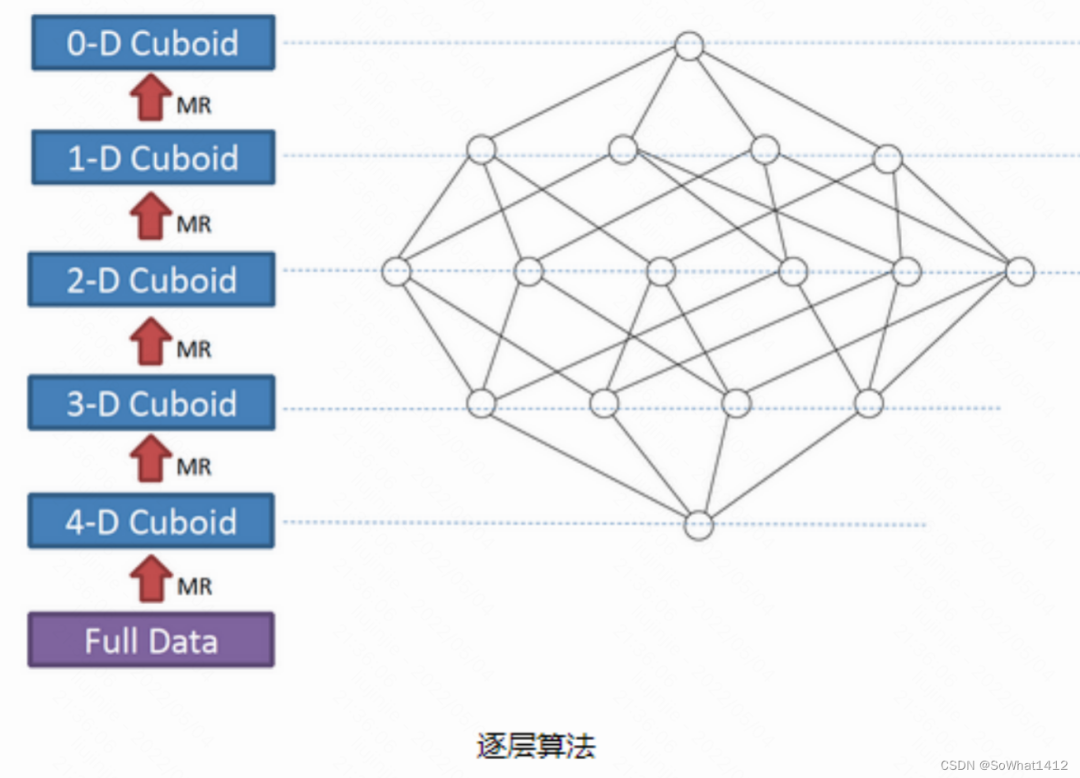
一個N維的Cube,是由1個N維子立方體、N個(N-1)維子立方體、N*(N-1)/2個(N-2)維子立方體、……、N個1維子立方體和1個0維子立方體構成,總共有2^N個子立方體組成,在逐層算法中,按維度數逐層減少來計算,每個層級的計算(除了第一層,它是從原始數據聚合而來),是基于它上一層級的結果來計算的。比如,[Group by A, B]的結果,可以基于[Group by A, B, C]的結果,通過去掉C后聚合得來的;這樣可以減少重復計算;當 0維度Cuboid計算出來的時候,整個Cube的計算也就完成了。
每一輪的計算都是一個MapReduce任務,且串行執行;一個N維的Cube,至少需要N+1次MapReduce Job。
算法優點:
- 此算法充分利用了MapReduce的能力,處理了中間復雜的排序和洗牌工作,故而算法代碼清晰簡單,易于維護;
- 受益于Hadoop的日趨成熟,此算法對集群要求低,運行穩定;在內部維護Kylin的過程中,很少遇到在這幾步出錯的情況;即便是在Hadoop集群比較繁忙的時候,任務也能完成。
算法缺點:
- 當Cube有比較多維度的時候,所需要的MapReduce任務也相應增加;由于Hadoop的任務調度需要耗費額外資源,特別是集群較龐大的時候,反復遞交任務造成的額外開銷會相當可觀;
- 此算法會對Hadoop MapReduce輸出較多數據; 雖然已經使用了Combiner來減少從Mapper端到Reducer端的數據傳輸,所有數據依然需要通過Hadoop MapReduce來排序和組合才能被聚合,無形之中增加了集群的壓力;
- 對HDFS的讀寫操作較多:由于每一層計算的輸出會用做下一層計算的輸入,這些Key-Value需要寫到HDFS上;當所有計算都完成后,Kylin還需要額外的一輪任務將這些文件轉成HBase的HFile格式,以導入到HBase中去;總體而言,該算法的效率較低,尤其是當Cube維度數較大的時候。
2.2.2.2 快速構建算法(inmem)
快速構建算法也被稱作“逐段”(By Segment) 或“逐塊”(By Split) 算法,從1.5.x開始引入該算法,利用Mapper端計算先完成大部分聚合,再將聚合后的結果交給Reducer,從而降低對網絡瓶頸的壓力。該算法的主要思想是,對Mapper所分配的數據塊,將它計算成一個完整的小Cube 段(包含所有Cuboid);每個Mapper將計算完的Cube段輸出給Reducer做合并,生成大Cube,也就是最終結果;如圖所示解釋了此流程。
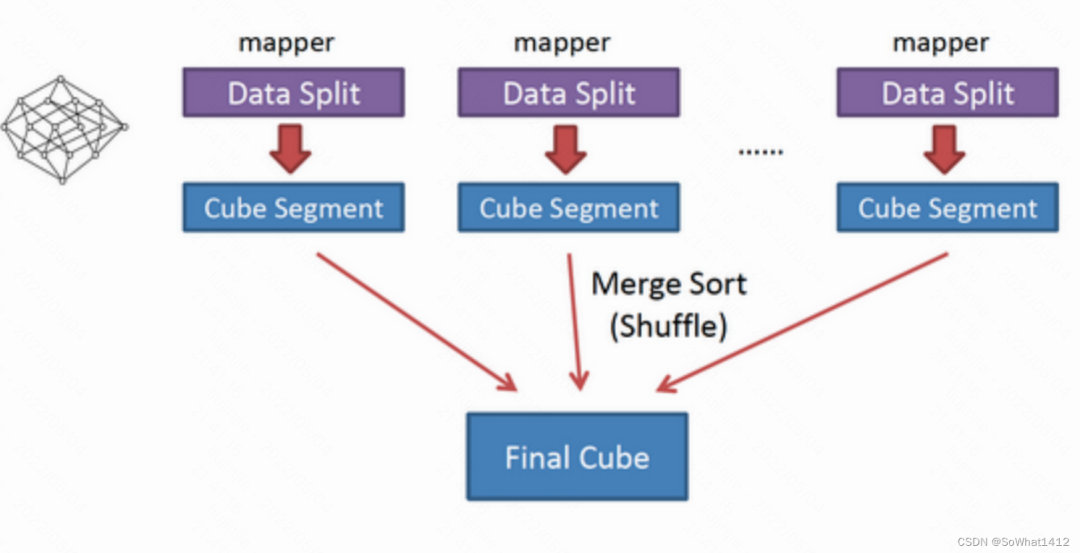
快速Cube算法
與舊算法相比,快速算法主要有兩點不同。
- Mapper會利用內存做預聚合,算出所有組合;Mapper輸出的每個Key都是不同的,這樣會減少輸出到Hadoop MapReduce的數據量;
- 一輪MapReduce便會完成所有層次的計算,減少Hadoop任務的調配,所以如果機器性能不錯推薦用此種方法。
2.2.3 Cube存儲原理
假設維度字典表具體信息如下。
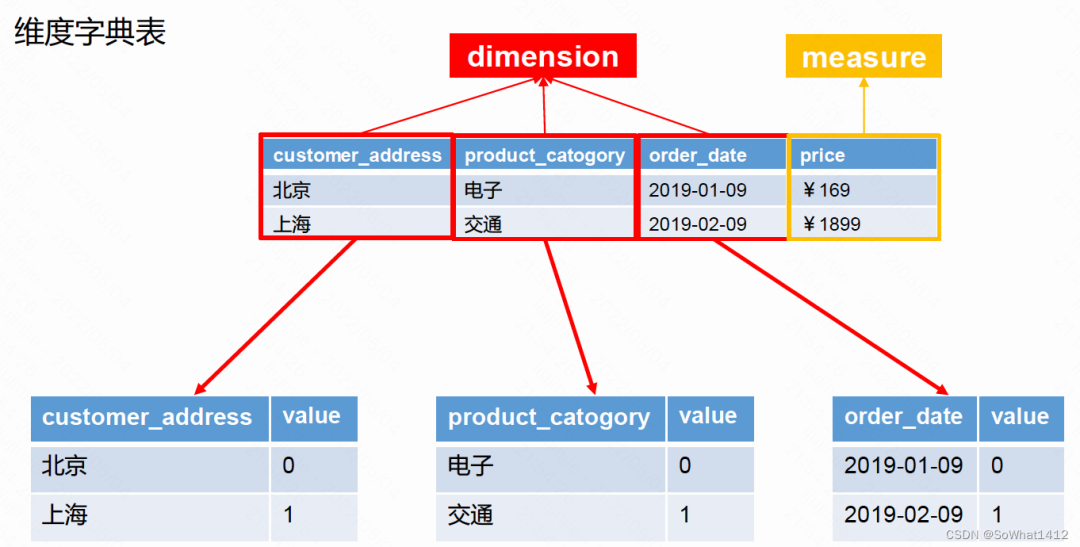
字典表信息
加入我們選擇了 address、catogory、date為維度進行Cube聚合。我們需要知道Cube底層是如何預聚合后把數據存儲到HBase中的。
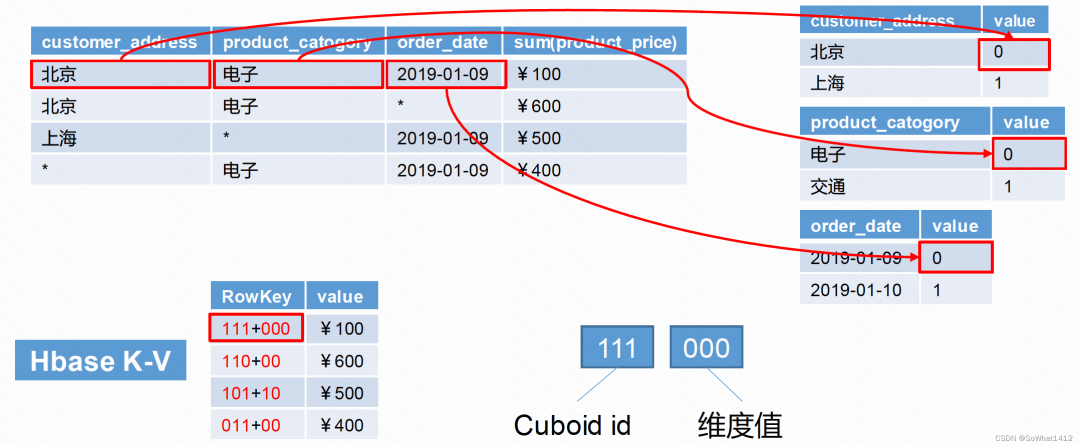
Cube存儲
系統會按照所有的維度選跟不選做01映射,然后每個維度選了后也有對應的維度值做映射。此時 key = Cubeid + 緯度值, value = 對應預聚合結果。
2.3 Kylin入手
2.3.1 Kylin 安裝
Kylin 是依賴于Hadoop、HBase、Zookeeper、Spark的,所以安裝時需確保所有的前置依賴是OK的。至于安裝細節,找個百度教程即可。
2.3.2 數據準備
在Kylin安裝完畢后,需要構建數據源、創建Model、創建Cube等操作,都是一些常規操作,沒啥說的。創建模型時整體有點類似PowerBI,需要選擇表Join的方式跟字段,選擇事實表跟維度的指標跟維度。
2.4 注意事項
因為Routing默認關閉,為了保證OLAP查詢的性能穩定,不會出現忽快忽慢的場景,有如下個約束條件。
2.4.1 只能按照構建 Model的連接條件來寫 SQL
創建時候如果是A join B,則查詢時也只能這樣查詢。
2.4.2 只能按照構建 Cube時選擇的維度字段分組統計
如果我們選擇了4個維度,則在進行OLAP查詢時候也只能選擇這個四個維度進行groupBy。
2.4.3 只能統計構建 Cube時選擇的度量值字段
如果在構建Cube時,只添加兩個指標,則查詢時候也只能查詢這倆。別的都不能查詢。
3. Cube 構建優化
3.1 使用衍生維度
衍生維度用于在有效維度內將維度表上的非主鍵維度排除掉,并使用維度表的主鍵(其
實是事實表上相應的外鍵)來替代它們。Kylin 會在底層記錄維度表主鍵與維度表其他維度之間的映射關系,以便在查詢時能夠動態地將維度表的主鍵“翻譯”成這些非主鍵維度,并進行實時聚合,(一般不建議開,可能會導致查詢耗時變大)。

衍生維度
3.2 使用聚合組(Aggregation Group)
聚合組就是一個強大的剪枝工具,通過指定不同的剪枝策略可以縮小維度組合個數。
3.2.1 強制維度
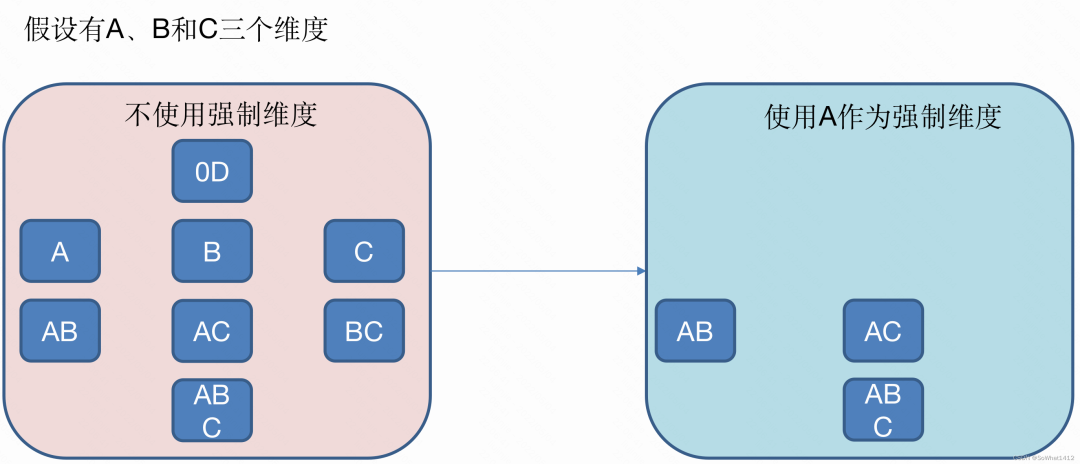
強制維度
強制維度(Mandatory),如果一個維度被定義為強制維度,分組后的維度組合結果一定要包含該維度,但是強制維度不能自己出現。
3.2.2 層級維度
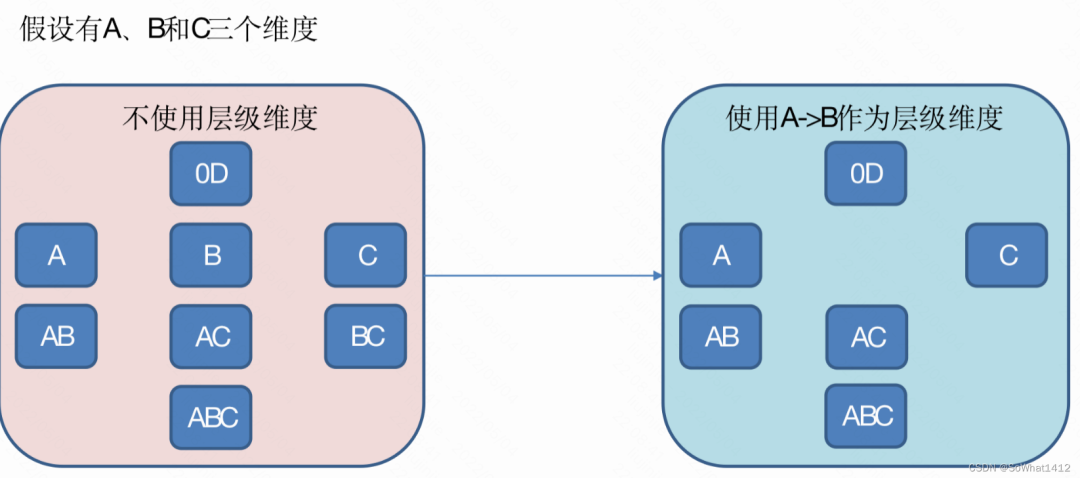
層級維度
如果指定了維度直接的依賴關系,比如 維度A(年) -> 維度B(月)。維度B不能單獨出現,必須B想出現的話必須有A。
3.2.3 聯合維度
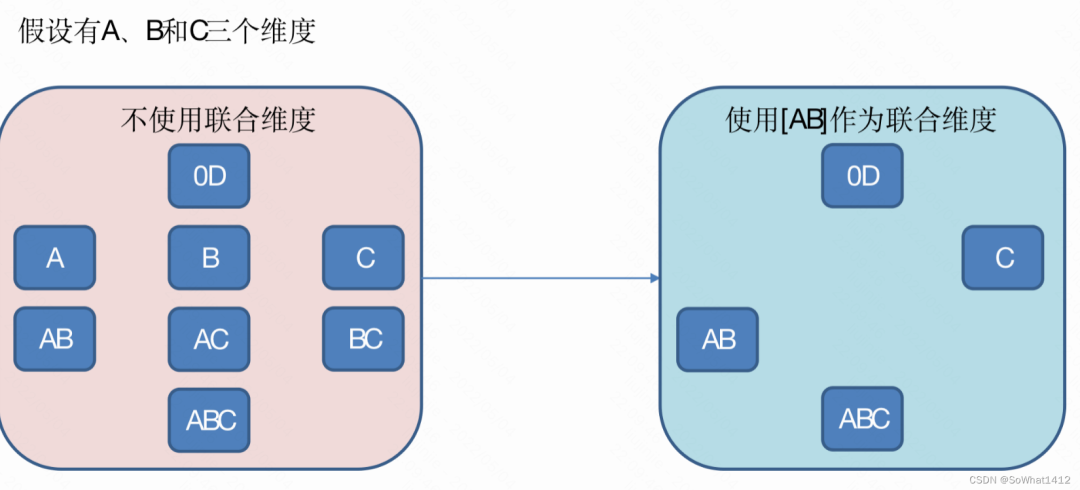
聯合維度
每個聯合中包含兩個或更多個維度,如果某些列形成一個聯合,那么在該分組產生的任何Cuboid中,這些聯合維度要么一起出現,要么都不出現。
3.3 Row Key 優化Kylin 會把所有的維度按照順序組合成一個完整的Rowkey,并且按照這個Rowkey 升序
排列Cuboid 中所有的行。設計良好的Rowkey 將更有效地完成數據的查詢過濾和定位,減少IO 次數,提高查詢速度,維度在rowkey 中的次序,對查詢性能有顯著的影響。
3.3.1 被過濾的維度放在前面
如果A的枚舉值是1、2、3、4。B的枚舉值a、b、c、d。

過濾
3.3.2 基數打的維度放在基數小的維度前面
如下,想生成AB的結果,則可從ABC、ABD中出結果(ABD結果行數更少),因為kylin系統默認選擇cubeid小的,所以基數打的維度盡量前調。
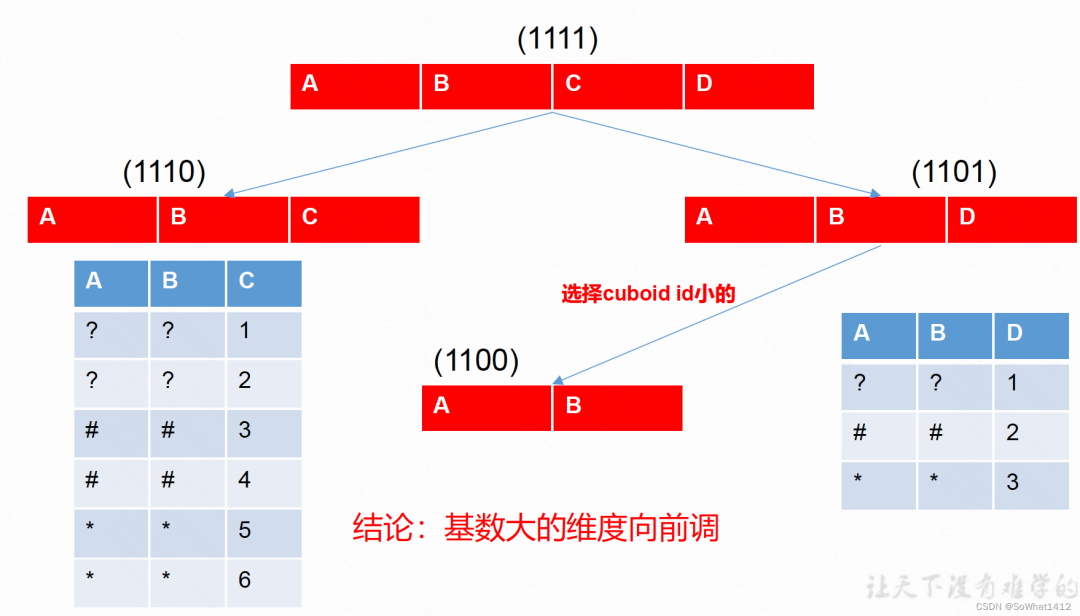
由三個維度生成兩個維度
4. 參考
Kylin : https://www.bilibili.com/video/BV1QU4y1F7QH?p=19