Apache Kylin優化–高級設置:聚合組(Aggregation Group)原理解析
“隨著維度數目的增加,Cuboid 的數量會爆炸式地增長。為了緩解 Cube 的構建壓力,Apache Kylin 引入了一系列的高級設置,幫助用戶篩選出真正需要的 Cuboid。這些高級設置包括聚合組(Aggregation Group)、聯合維度(Joint Dimension)、層級維度(Hierachy Dimension)和必要維度(Mandatory Dimension)等。”
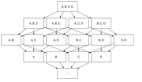
眾所周知,Apache Kylin 的主要工作就是為源數據構建 N 個維度的 Cube,實現聚合的預計算。理論上而言,構建 N 個維度的 Cube 會生成 2N 個 Cuboid, 如圖 1 所示,構建一個 4 個維度(A,B,C, D)的 Cube,需要生成 16 個Cuboid。
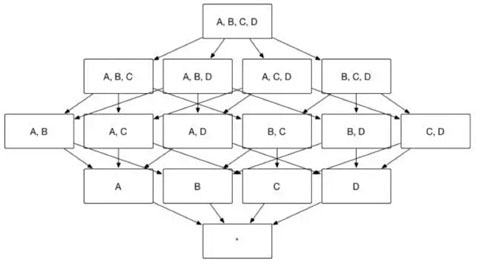
圖1
隨著維度數目的增加 Cuboid 的數量會爆炸式地增長,不僅占用大量的存儲空間還會延長 Cube 的構建時間。為了緩解 Cube 的構建壓力,減少生成的 Cuboid 數目,Apache Kylin 引入了一系列的高級設置,幫助用戶篩選出真正需要的 Cuboid。這些高級設置包括聚合組(Aggregation Group)、聯合維度(Joint Dimension)、層級維度(Hierachy Dimension)和必要維度(Mandatory Dimension)等,本系列將深入講解這些高級設置的含義及其適用的場景。
本文將著重介紹聚合組的實現原理與應用場景實例。
聚合組(Aggregation Group)
用戶根據自己關注的維度組合,可以劃分出自己關注的組合大類,這些大類在 Apache Kylin 里面被稱為聚合組。例如圖 1 中展示的 Cube,如果用戶僅僅關注維度 AB 組合和維度 CD 組合,那么該 Cube 則可以被分化成兩個聚合組,分別是聚合組 AB 和聚合組 CD。如圖 2 所示,生成的 Cuboid 數目從 16 個縮減成了 8 個。

圖2
用戶關心的聚合組之間可能包含相同的維度,例如聚合組 ABC 和聚合組 BCD 都包含維度 B 和維度 C。這些聚合組之間會衍生出相同的 Cuboid,例如聚合組 ABC 會產生 Cuboid BC,聚合組 BCD 也會產生 Cuboid BC。這些 Cuboid不會被重復生成,一份 Cuboid 為這些聚合組所共有,如圖 3 所示。

圖3
有了聚合組用戶就可以粗粒度地對 Cuboid 進行篩選,獲取自己想要的維度組合。
應用實例
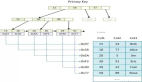
假設創建一個交易數據的 Cube,它包含了以下一些維度:顧客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和買家所在的城市 city。有時候,分析師需要通過分組聚合 city、cal_dt 和 pay_type 來獲知不同消費方式在不同城市的應用情況;有時候,分析師需要通過聚合 city 、cal_dt 和 buyer_id,來查看顧客在不同城市的消費行為。在上述的實例中,推薦建立兩個聚合組,包含的維度和方式如圖 4 :
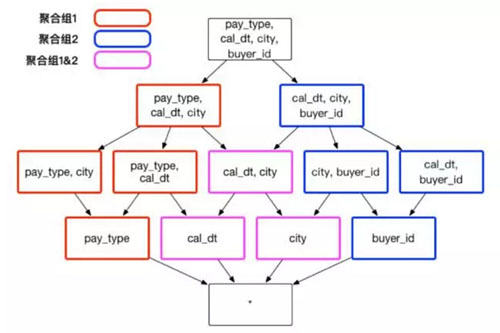
聚合組 1: [cal_dt, city, pay_type]
聚合組 2: [cal_dt, city, buyer_id]
在不考慮其他干擾因素的情況下,這樣的聚合組將節省不必要的 3 個 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,節省了存儲資源和構建的執行時間。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 則將從 Cuboid [cal_dt, city, pay_type] 中獲取數據。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 則將從 Cuboid [cal_dt, city, pay_type] 中獲取數據。
Case3 如果有一條不常用的查詢:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 則沒有現成的完全匹配的 Cuboid。
此時,Apache Kylin 會通過在線計算的方式,從現有的 Cuboid 中計算出最終結果。
小結
Apache Kylin 作為一種多維分析工具,其采用預計算的方法,利用空間換取時間,提高查詢效率。本文介紹了 Apache Kylin 的高級設置中聚合組的部分,聚合組適用于當分析師粗粒度地關注某些維度去進行分組聚合的場景。