Kafka 負載均衡在 vivo 的落地實踐
作者 | vivo 互聯網服務器團隊-You Shuo
副本遷移是Kafka最高頻的操作,對于一個擁有幾十萬個副本的集群,通過人工去完成副本遷移是一件很困難的事情。Cruise Control作為Kafka的運維工具,它包含了Kafka 服務上下線、集群內負載均衡、副本擴縮容、副本缺失修復以及節點降級等功能。顯然,Cruise Control的出現,使得我們能夠更容易的運維大規模Kafka集群。
備注:本文基于 Kafka 2.1.1開展。
一、 Kafka 負載均衡
1.1 生產者負載均衡
Kafka 客戶端可以使用分區器依據消息的key計算分區,如果在發送消息時未指定key,則默認分區器會基于round robin算法為每條消息分配分區;
否則會基于murmur2哈希算法計算key的哈希值,并與分區數取模的到最后的分區編號。
很顯然,這并不是我們要討論的Kafka負載均衡,因為生產者負載均衡看起來并不是那么的復雜。
1.2 消費者負載均衡
考慮到消費者上下線、topic分區數變更等情況,KafkaConsumer還需要負責與服務端交互執行分區再分配操作,以保證消費者能夠更加均衡的消費topic分區,從而提升消費的性能;
Kafka目前主流的分區分配策略有2種(默認是range,可以通過partition.assignment.strategy參數指定):
- range: 在保證均衡的前提下,將連續的分區分配給消費者,對應的實現是RangeAssignor;
- round-robin:在保證均衡的前提下,輪詢分配,對應的實現是RoundRobinAssignor;
- 0.11.0.0版本引入了一種新的分區分配策略StickyAssignor,其優勢在于能夠保證分區均衡的前提下盡量保持原有的分區分配結果,從而避免許多冗余的分區分配操作,減少分區再分配的執行時間。
無論是生產者還是消費者,Kafka 客戶端內部已經幫我們做了負載均衡了,那我們還有討論負載均衡的必要嗎?答案是肯定的,因為Kafka負載不均的主要問題存在于服務端而不是客戶端。
二、 Kafka 服務端為什么要做負載均衡
我們先來看一下Kafka集群的流量分布(圖1)以及新上線機器后集群的流量分布(圖2):
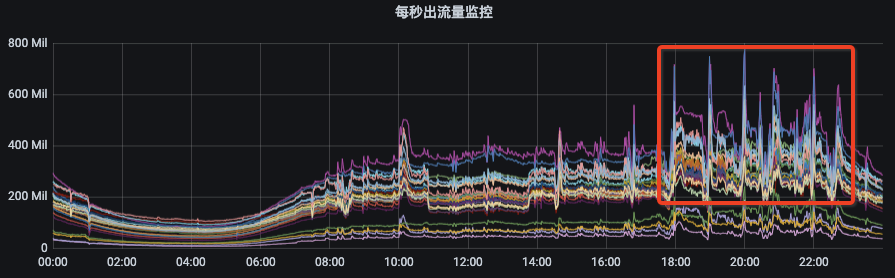
圖1
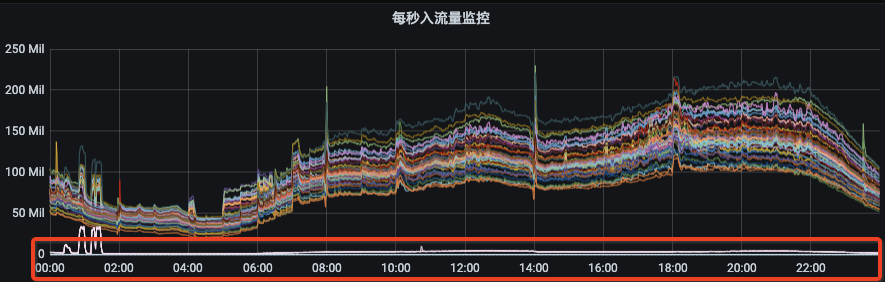
圖2
從圖1可以看出資源組內各broker的流量分布并不是很均衡,而且由于部分topic分區集中分布在某幾個broker上,當topic流量突增的時候,會出現只有部分broker流量突增。
這種情況下,我們就需要擴容topic分區或手動執行遷移動操作。
圖2是我們Kafka集群的一個資源組擴容后的流量分布情況,流量無法自動的分攤到新擴容的節點上。此時,就需要我們手動的觸發數據遷移,從而才能把流量引到新擴容的節點上。
2.1 Kafka 存儲結構
為什么會出現上述的問題呢?這個就需要從Kafka的存儲機制說起。
下圖是Kafka topic的存儲結構,其具體層級結構描述如下:
- 每個broker節點可以通過logDirs配置項指定多個log目錄,我們線上機器共有12塊盤,每塊盤都對應一個log目錄。
- 每個log目錄下會有若干個[topic]-[x]字樣的目錄,該目錄用于存儲指定topic指定分區的數據,對應的如果該topic是3副本,那在集群的其他broker節點上會有兩個和該目錄同名的目錄。
- 客戶端寫入kafka的數據最終會按照時間順序成對的生成.index、.timeindex、.snapshot以及.log文件,這些文件保存在對應的topic分區目錄下。
- 為了實現高可用目的,我們線上的topic一般都是2副本/3副本,topic分區的每個副本都分布在不同的broker節點上,有時為了降低機架故障帶來的風險,topic分區的不同副本也會被要求分配在不同機架的broker節點上。
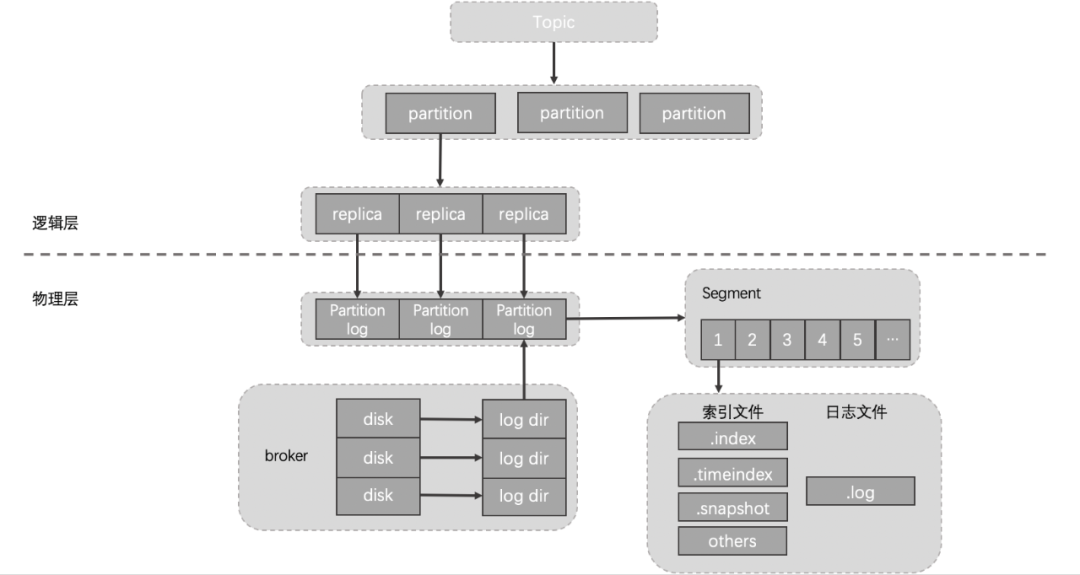
了解完Kafka存儲機制之后,我們可以清晰的了解到,客戶端寫入Kafka的數據會按照topic分區被路由到broker的不同log目錄下,只要我們不人工干預,那每次路由的結果都不會改變。因為每次路由結果都不會改變,那么問題來了:
隨著topic數量不斷增多,每個topic的分區數量又不一致,最終就會出現topic分區在Kafka集群內分配不均的情況。
比如:topic1是10個分區、topic2是15個分區、topic3是3個分區,我們集群有6臺機器。那6臺broker上總會有4臺broker有兩個topic1的分區,有3臺broke上有3個topic3分區等等。
這樣的問題就會導致分區多的broker上的出入流量可能要比其他broker上要高,如果要考慮同一topic不同分區流量不一致、不同topic流量又不一致,再加上我們線上有7000個topic、13萬個分區、27萬個副本等等這些。
這么復雜的情況下,集群內總會有broker負載特別高,有的broker負載特別低,當broker負載高到一定的時候,此時就需要我們的運維同學介入進來了,我們需要幫這些broker減減壓,從而間接的提升集群總體的負載能力。
當集群整體負載都很高,業務流量會持續增長的時候,我們會往集群內擴機器。有些同學想擴機器是好事呀,這會有什么問題呢?問題和上面是一樣的,因為發往topic分區的數據,其路由結果不會改變,如果沒有人工干預的話,那新擴進來機器的流量就始終是0,集群內原來的broker負載依然得不到減輕。
三、如何對 Kafka 做負載均衡
3.1 人工生成遷移計劃和遷移
如下圖所示,我們模擬一個簡單的場景,其中的T0-P0-R0表示topic-分區-副本,假設topic各分區流量相同,假設每個分區R0副本是leader。
我們可以看到,有兩個topic T0和T1,T0是5分區2副本(出入流量為10和5),T1是3分區2副本(出入流量為5和1),如果嚴格考慮機架的話,那topic副本的分布可能如下:
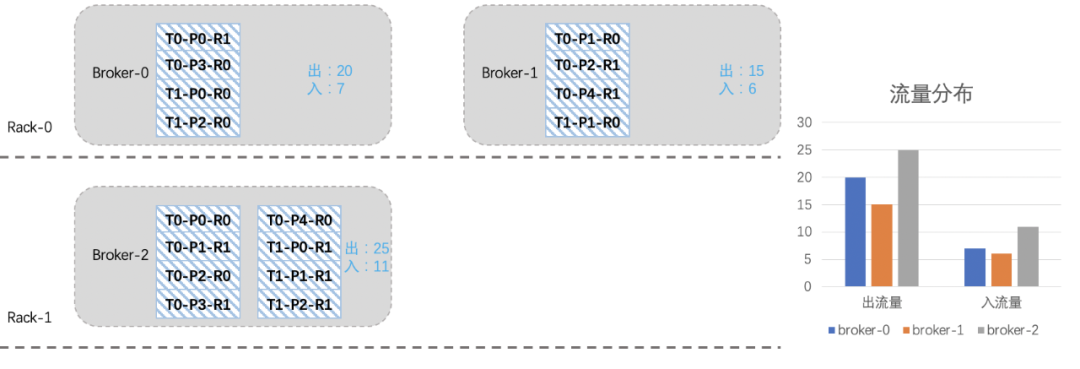
假設我們現在新擴入一臺broker3(Rack2),如下圖所示:由于之前考慮了topic在機架上的分布,所以從整體上看,broker2的負載要高一些。
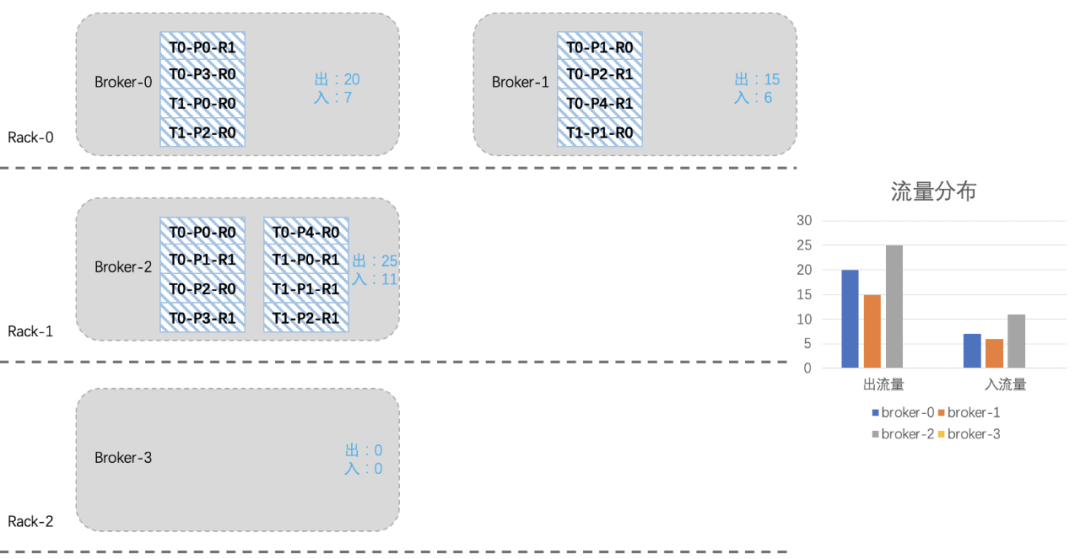
我們現在想把broker2上的一些分區遷移到新擴進來的broker3上,綜合考慮機架、流量、副本個數等因素,我們將T0-P2-R0、T0-P3-R1、T0-P4-R0、T1-P0-R1四個分區遷移到broker3上。
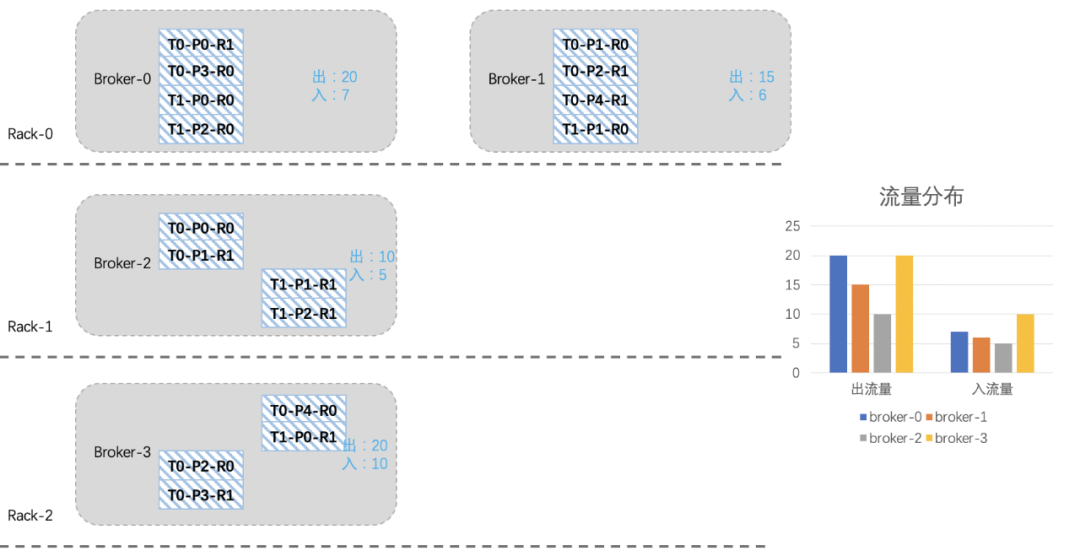
看起來還不是很均衡,我們再將T1-P2分區切換一下leader:
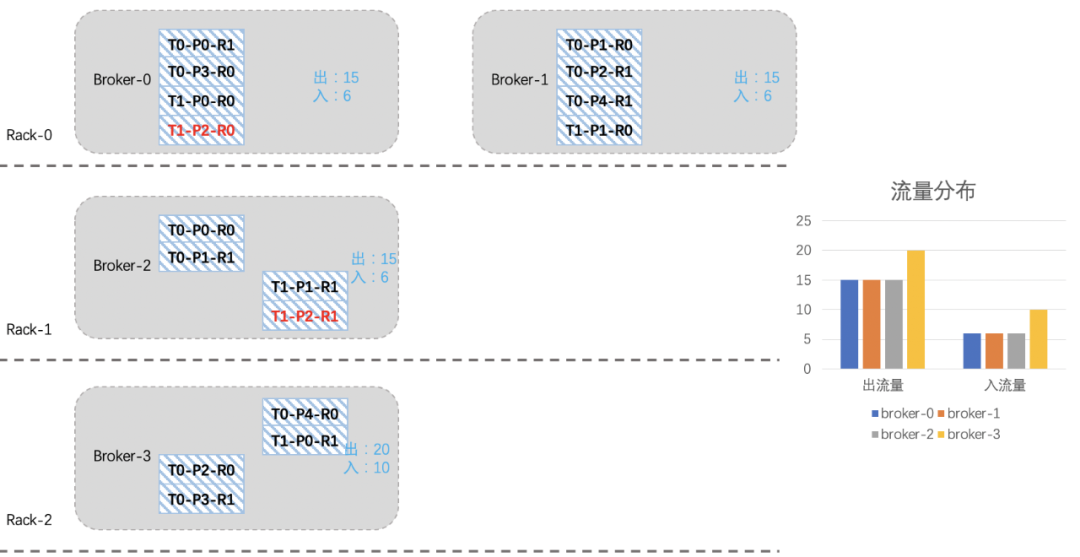
經歷一番折騰后,整個集群就均衡許多了,關于上面遷移副本和leader切換的命令參考如下:
Kafka 副本遷移腳本
# 副本遷移腳本:kafka-reassign-partitions.sh
# 1. 配置遷移文件
$ vi topic-reassignment.json
{"version":1,"partitions":[
{"topic":"T0","partition":2,"replicas":[broker3,broker1]},
{"topic":"T0","partition":3,"replicas":[broker0,broker3]},
{"topic":"T0","partition":4,"replicas":[broker3,broker1]},
{"topic":"T1","partition":0,"replicas":[broker2,broker3]},
{"topic":"T1","partition":2,"replicas":[broker2,broker0]}
]}
# 2. 執行遷移命令
bin/kafka-reassign-partitions.sh --throttle 73400320 --zookeeper zkurl --execute --reassignment-json-file topic-reassignment.json
# 3. 查看遷移狀態/清除限速配置
bin/kafka-reassign-partitions.sh --zookeeper zkurl --verify --reassignment-json-file topic-reassignment.json
3.2 使用負載均衡工具-cruise control
經過對Kafka存儲結構、人工干預topic分區分布等的了解后,我們可以看到Kafka運維起來是非常繁瑣的,那有沒有一些工具可以幫助我們解決這些問題呢?
答案是肯定的。
cruise control是LinkedIn針對Kafka集群運維困難問題而開發的一個項目,cruise control能夠對Kafka集群各種資源進行動態負載均衡,這些資源包括:CPU、磁盤使用率、入流量、出流量、副本分布等,同時cruise control也具有首選leader切換和topic配置變更等功能。
3.2.1 cruise cotnrol 架構
我們先簡單介紹下cruise control的架構。
如下圖所示,其主要由Monitor、Analyzer、Executor和Anomaly Detector 四部分組成:
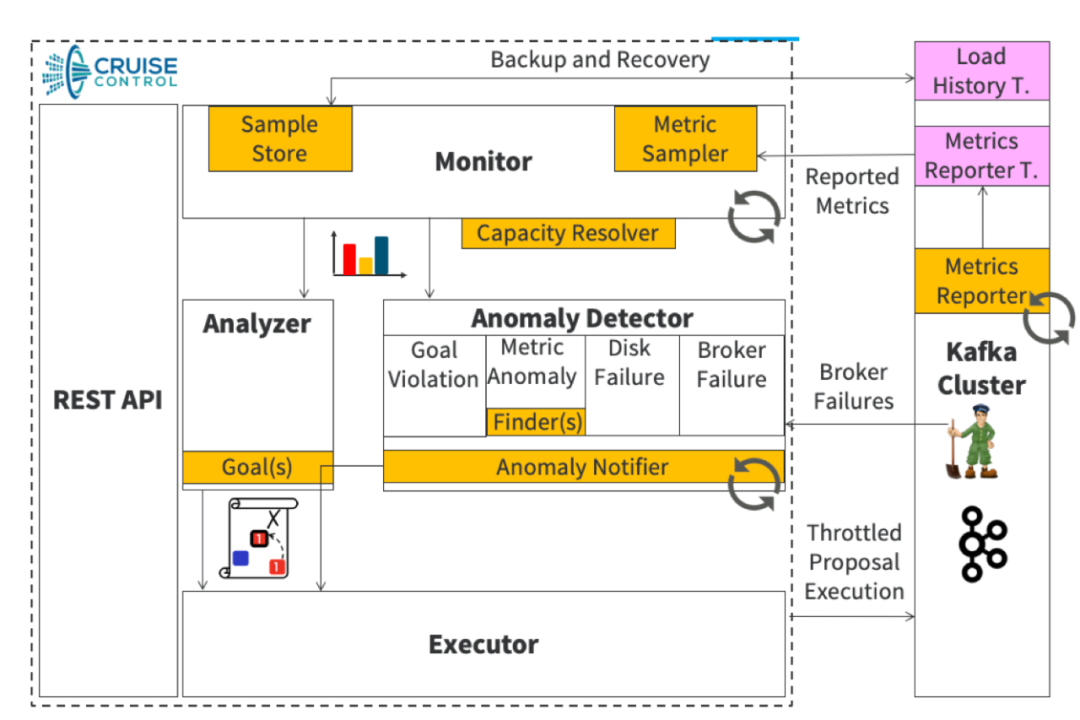
(來源:cruise control 官網)
(1)Monitor
Monitor分為客戶端Metrics Reporter和服務端Metrics Sampler:
- Metrics Reporter實現了Kafka的指標上報接口MetricsReporter,以特定的格式將原生的Kafka指標上報到topic __CruiseControlMetrics中。
- Metrics Sampler從__CruiseControlMetrics中獲取原生指標后按照broker和分區級指標分別進行聚合,聚合后的指標包含了broker、分區負載的均值、最大值等統計值,這些中間結果將被發送topic __KafkaCruiseControlModelTrainingSamples和__KafkaCruiseControlPartitionMetricSamples中;
(2)Analyzer
Analyzer作為cruise control的核心部分,它根據用戶提供的優化目標和基于Monitor生成的集群負載模型生成遷移計劃。
在cruise control中,“用戶提供的優化目標”包括硬性目標和軟性目標兩大類,硬性目標是Analyzer在做預遷移的時候必須滿足的一類目標(例如:副本在遷移后必須滿足機架分散性原則),軟性目標則是盡可能要達到的目標,如果某一副本在遷移后只能同時滿足硬性目標和軟性目標中的一類,則以硬性目標為主,如果存在硬性目標無法滿足的情況則本次分析失敗。
Analyzer可能需要改進的地方:
- 由于Monitor生成的是整個集群的負載模型,我們的Kafka平臺將Kafka集群劃分為多個資源組,不同資源組的資源利用率存在很大差別,所以原生的集群負載模型不再適用于我們的應用場景。
- 大多數業務沒有指定key進行生產,所以各分區的負載偏差不大。如果topic分區副本均勻分布在資源組內,則資源組也隨之變得均衡。
- 原生的cruise control會從集群維度來展開均衡工作,指定資源組后可以從資源組維度展開均衡工作,但無法滿足跨資源組遷移的場景。
(3)Executor
Executor作為一個執行者,它執行Analyzer分析得到的遷移計劃。它會將遷移計劃以接口的形式分批提交到Kafka集群上,后續Kafka會按照提交上來的遷移腳本執行副本遷移。
Executor可能需要改進的地方:
cruise control 在執行副本遷移類的功能時,不能觸發集群首選leader切換:有時在集群均衡過程中出現了宕機重啟,以問題機器作為首選leader的分區,其leader不能自動切換回來,造成集群內其他節點壓力陡增,此時往往會產生連鎖反應。
(4)Anomaly Detector
Anomaly Detector是一個定時任務,它會定期檢測Kafka集群是否不均衡或者是否有副本缺失這些異常情況,當Kafka集群出現這些情況后,Anomaly Detector會自動觸發一次集群內的負載均衡。
在后面的主要功能描述中,我會主要介紹Monitor和Analyzer的處理邏輯。
3.2.2 均衡 broker 出入流量 / 機器上下線均衡
對于Kafka集群內各broker之間流量負載不均的原因、示意圖以及解決方案,我們在上面已經介紹過了,那么cruise control是如何解決這個問題的。
其實cruise control均衡集群的思路和我們手動去均衡集群的思路大體一致,只不過它需要Kafka集群詳細的指標數據,以這些指標為基礎,去計算各broker之間的負載差距,并根據我們關注的資源去做分析,從而得出最終的遷移計劃。
服務端在接收到均衡請求后,Monitor會先根據緩存的集群指標數據構建一個能夠描述整個集群負載分布的模型。
下圖簡單描述了整個集群負載信息的生成過程,smaple fetcher線程會將獲取到的原生指標加載成可讀性更好的Metric Sample,并對其進行進一步的加工,得到帶有brokerid、partition分區等信息的統計指標,這些指標保存在對應broker、replica的load屬性中,所以broker和repilca會包含流量負載、存儲大小、當前副本是否是leader等信息。
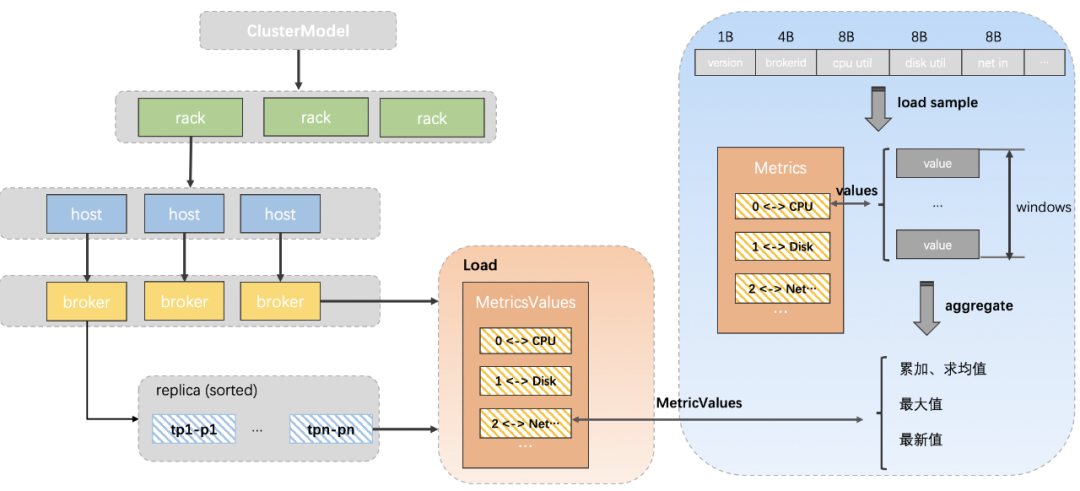
Analyzer 會遍歷我們指定的broker(默認是集群所有的broker),由于每臺broker及其下面的topic分區副本都有詳細的指標信息,分析算法直接根據這些指標和指定資源對broker進行排序。
本例子的資源就是topic分區leader副本數量,接著Analyzer會根據我們提前設置的最大/最小閾值、離散因子等來判斷當前broker上某topic的leader副本數量是否需要增加或縮減,如果是增加,則變更clustermodel將負載比較高的broker上對應的topic leader副本遷移到當前broker上,反之亦然,在后面的改造點中,我們會對Analyzer的工作過程做簡單的描述。
遍歷過所有broker,并且針對我們指定的所有資源都進行分析之后,就得出了最終版的clustermodel,再與我們最初生成的clustermodel對比,就生成了topic遷移計劃。
cruise control會根據我們指定的遷移策略分批次的將topic遷移計劃提交給kafka集群執行。
遷移計劃示意圖如下:
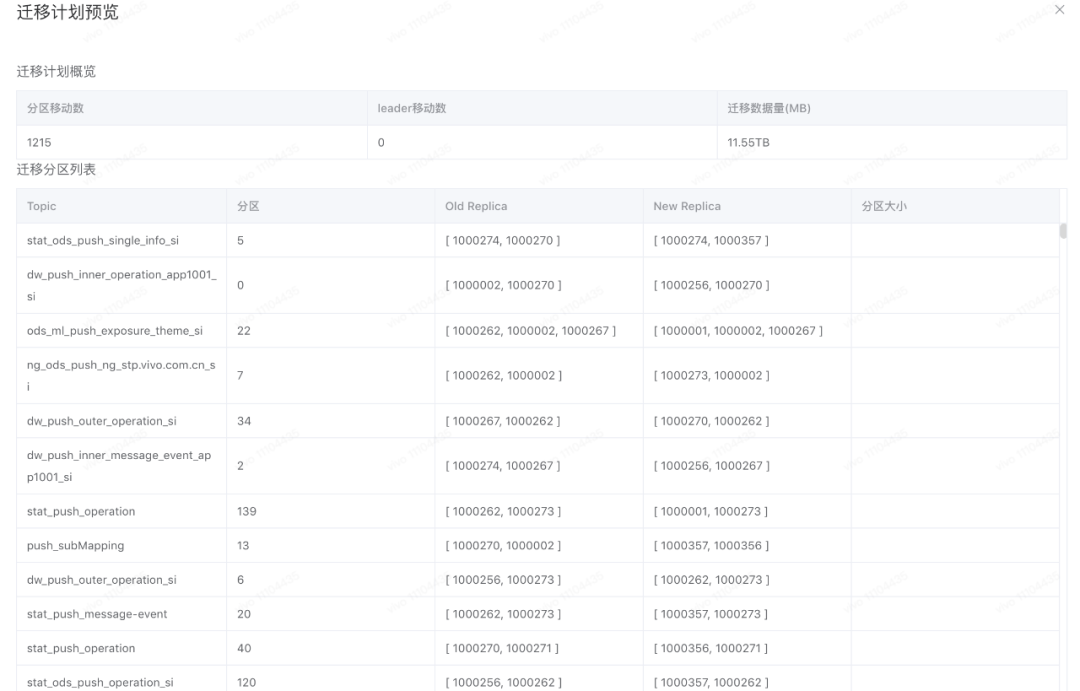
3.2.3 首選 leader 切換
切換非首選leader副本,遷移計劃示意圖如下:
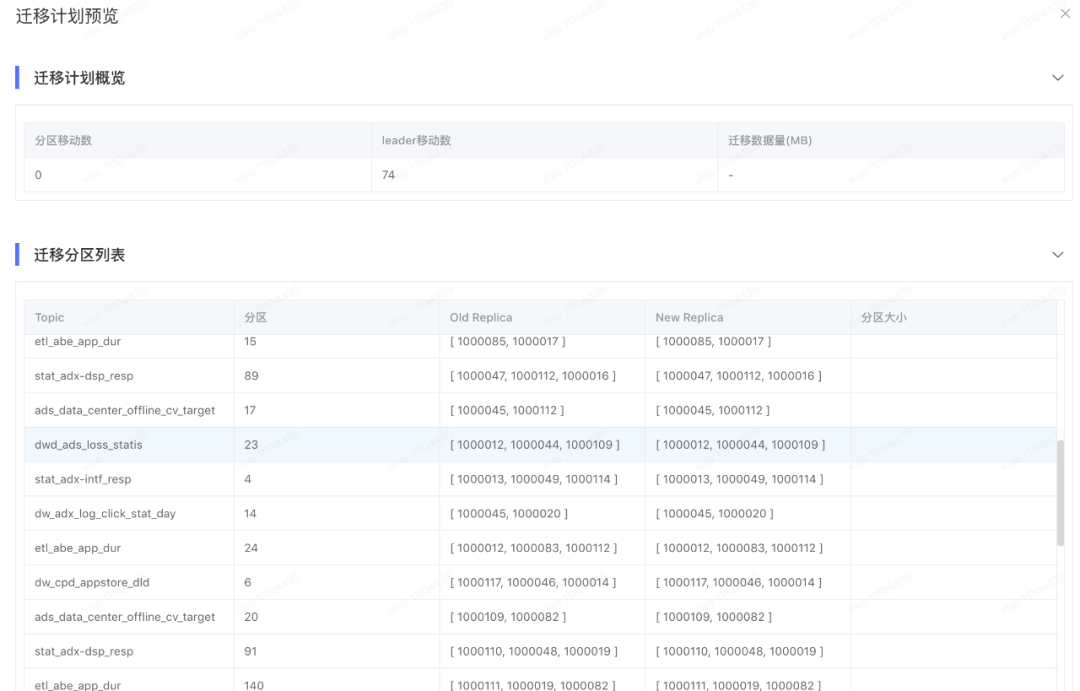
3.2.4 topic配置變更
改變topic副本個數,遷移計劃示意圖如下:
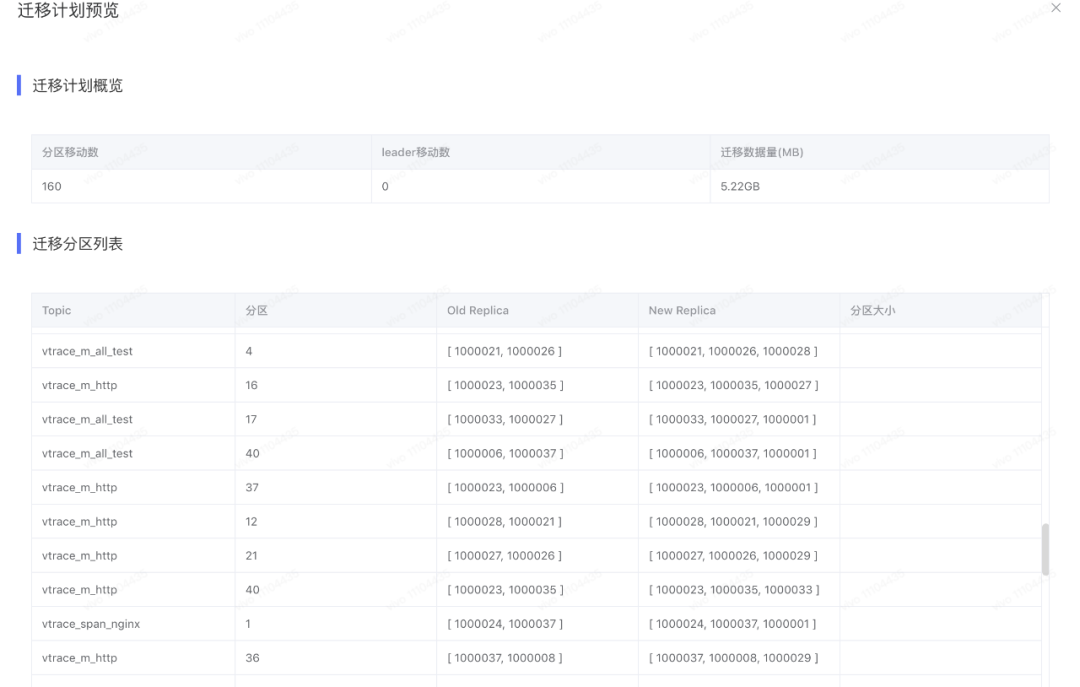
3.3 改造 cruise control
3.3.1 指定資源組進行均衡
當集群規模非常龐大的時候,我們想要均衡整個集群就變得非常困難,往往均衡一次就需要半個月甚至更長時間,這在無形之中也加大了我們運維同學的壓力。
針對這個場景,我們對cruise control也進行了改造,我們從邏輯上將Kafka集群劃分成多個資源組,使得業務擁有自己的資源組,當某個業務出現流量波動的時候,不會影響到其他的業務。
通過指定資源組,我們每次只需要對集群的一小部分或多個部分進行均衡即可,大大縮短了均衡的時間,使得均衡的過程更加可控。
改造后的cruise control可以做到如下幾點:
- 通過均衡參數,我們可以只均衡某個或多個資源組的broker。
- 更改topic配置,比如增加topic副本時,新擴的副本需要和topic原先的副本在同一個資源組內。
- 在資源組內分析broker上的資源是遷入還是遷出。對于每一類資源目標,cruise control是計算資源組范圍內的統計指標,然后結合閾值和離散因子來分析broker是遷出資源還是遷入資源。
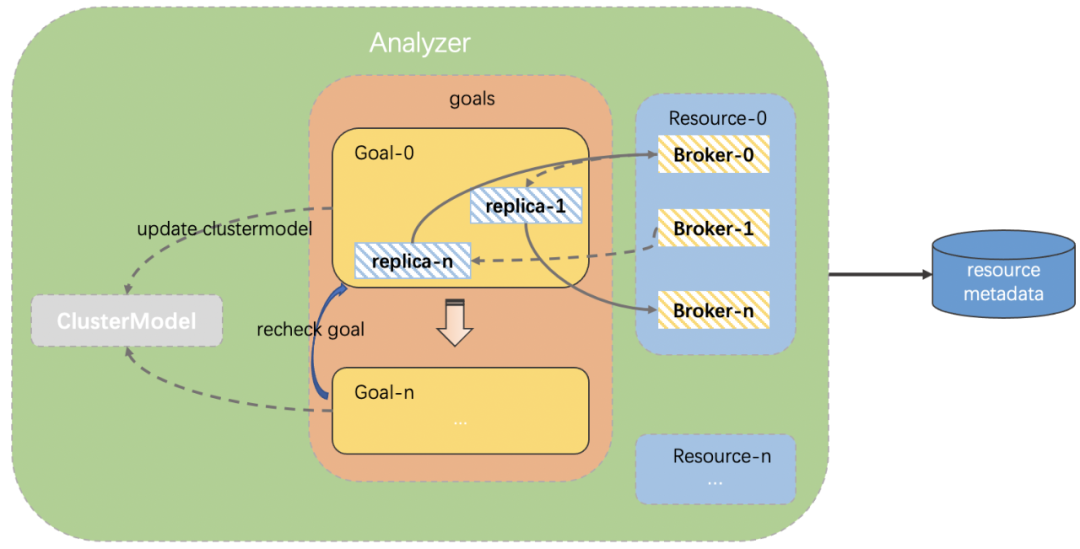
如下圖所示,我們將集群、資源組、以及資源組下的topic這些元數據保存在數據庫中,Analyzer得以在指定的資源組范圍內,對每個broker按照資源分布目標做均衡分析。
例如:當對broker-0做均衡分析的時候,Analyzer會遍歷goals列表,每個goals負責一類資源負載目標(cpu、入流量等),當均衡分析到達goal-0的時候,goal-0會判斷broker-0的負載是否超出上限閾值,如果超出,則需要將broker-0的一些topic副本遷移到負載較低的broker上;反之,則需要將其他broker上的副本遷移到broker-0上。
其中,下面的recheck goals是排在后面的goal在做均衡分析的時候,在更新cluster model之前會判斷本次遷移會不會與之前的goal沖突,如果沖突,那就不更新cluster model,當前的goal會繼續嘗試往其他broker上遷移,直到找到適合的遷移目標,然后更新cluster model。
3.3.2 topic/topic分區往指定broker上遷移
考慮這些場景:
- 一個項目下會有幾個資源組,由于業務變更,業務想要把A資源組下的topic遷移到B資源組。
- 業務想要把公共資源組的topic遷移到C資源組。
- 均衡完成之后,發現總有幾個topic/分區分布不是很均勻。
面對這些場景,我們上面指定資源組進行均衡的功能就滿足不了我們的需求了。所以,我們針對上述場景改造后的cruise control可以做到如下幾點:
- 只均衡指定的topic或topic分區;
- 均衡的topic或topic分區只往指定的broker上遷移。
3.3.3 新增目標分析——topic分區leader副本分散性
業務方大多都是沒有指定key進行發送數據的,所以同一topic每個分區的流量、存儲都是接近的,即每一個topic的各個分區的leader副本盡可能均勻的分布在集群的broker上時,那集群的負載就會很均勻。
有同學會問了,topic分區數并不總是能夠整除broker數量,那最后各broker的負載不還是不一致嘛?
答案是肯定的,只通過分區的leader副本還不能做到最終的均衡。
針對上述場景改造后的cruise control可以做到如下幾點:
- 新增一類資源分析:topic分區leader副本分散性。
- 首先保證每個topic的leader副本和follower副本盡可能的均勻分布在資源組的broker上。
- 在2的基礎上,副本會盡可能的往負載較低的broker上分布。
如下圖所示,針對每一個topic的副本,Analyzer會依次計算當前broker的topic leader數是否超過閾值上限,如果超過,則Analyzer會按照topic的leader副本數量、topic的follower副本數量、broker的出流量負載等來選出AR中的follower副本作為新的leader進行切換,如果AR副本中也沒有符合要求的broker,則會選擇AR列表以外的broker。
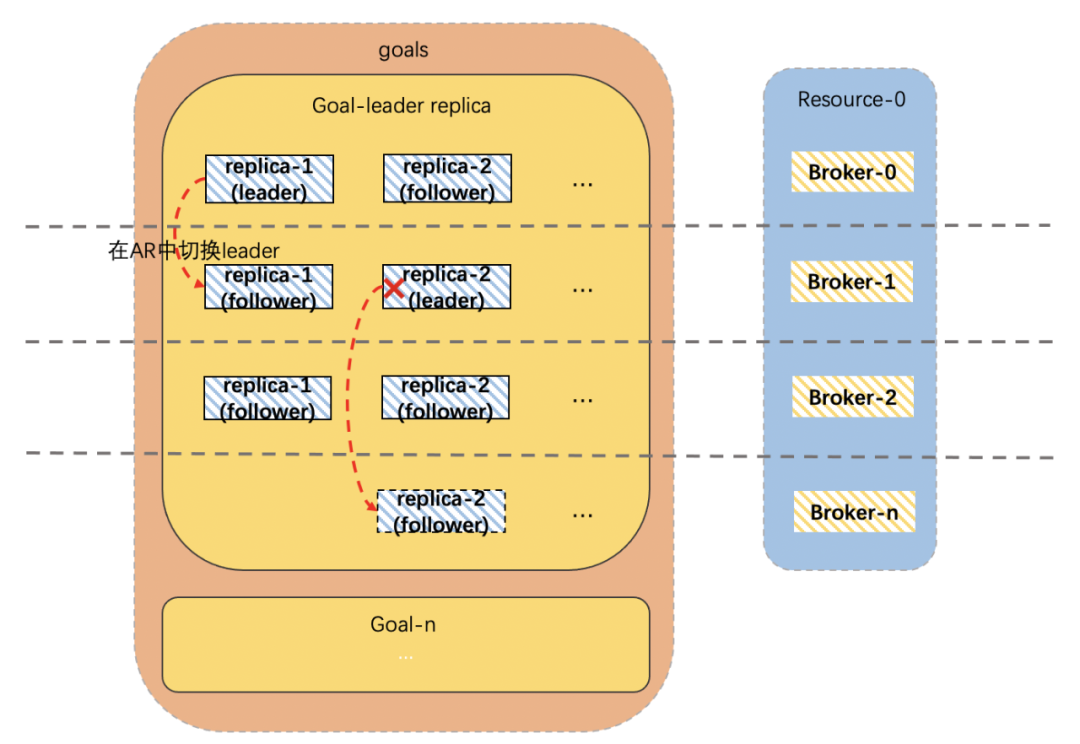
3.3.4 最終均衡效果
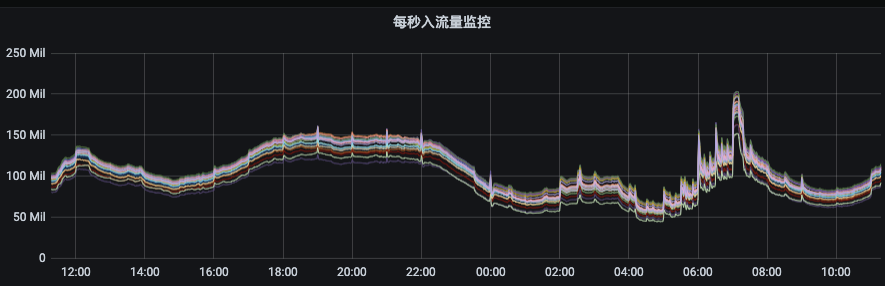
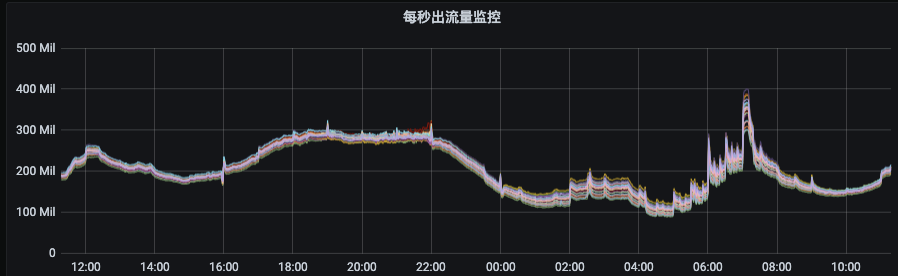
下圖是某個資源組均衡后的流量分布,各節點間流量偏差非常小,這種情況下,既可以增強集群扛住流量異常突增的能力又可以提升集群整體資源利用率和服務穩定性,降低成本。
3.4 安裝/部署cruise control
3.4.1 客戶端部署:指標采集
【步驟1】:創建Kafka賬號,用于后面生產和消費指標數據
【步驟2】:創建3個Kafka內部topic:a是用來存儲Kafka服務原生jmx指標;b和c分別是用來存儲cruise control處理過后的分區和模型指標;
【步驟3】:給步驟1創建的賬號授予讀/寫以及集群的操作權限,用于讀/寫步驟2創建的topic;
【步驟4】:修改kafka的server.properties,增加如下配置:
在Kafka服務上配置采集程序
# 修改kafka的server.properties
metric.reporters=com.linkedin.kafka.cruisecontrol.metricsreporter.CruiseControlMetricsReporter
cruise.control.metrics.reporter.bootstrap.servers=域名:9092
cruise.control.metrics.reporter.security.protocol=SASL_PLAINTEXT
cruise.control.metrics.reporter.sasl.mechanism=SCRAM-SHA-256
cruise.control.metrics.reporter.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=\"ys\" password=\"ys\";
【步驟5】:添加cruise-control-metrics-reporter的jar包到Kafka的lib目錄下:mv cruise-control-metrics-reporter-2.0.104-SNAPSHOT.jar kafka_dir/lib/;
【步驟6】:重啟Kafka服務。
3.4.2 服務端部署:指標聚合/均衡分析
(1)到https://github.com/linkedin/cruise-control 下載zip文件并解壓;
(2)將自己本地cruise control子模塊下生成的jar包替換cruise control的:
mv cruise-control-2.0.xxx-SNAPSHOT.jar
cruise-control/build/libs;
(3)修改cruise control配置文件,主要關注如下配置:
# 修改cruise control配置文件
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=\"ys\" password=\"ys\";
bootstrap.servers=域名:9092
zookeeper.connect=zkURL
(4)修改數據庫連接配置:
# 集群id
cluster_id=xxx
db_url=jdbc:mysql://hostxxxx:3306/databasexxx
db_user=xxx
db_pwd=xxx
四、總結
通過以上的介紹,我們可以看出Kafka存在比較明顯的兩個缺陷:
- Kafka每個partition replica與機器的磁盤綁定,partition replica由一系列的Segment組成,所以往往單分區存儲會占用比較大的磁盤空間,對于磁盤會有很大壓力。
- 在集群擴容broker時必須做Rebalance,需要broker有良好的執行流程,保證沒有任何故障的情況下使得各broker負載均衡。
cruise control就是針對Kafka集群運維困難問題而誕生的,它能夠很好的解決kafka運維困難的問題。
參考文章:
1. linkedIn/cruise-control?2. Introduction to Kafka Cruise Control?3. Cloudera Cruise Control REST API Reference
4. http://dockone.io/article/2434664
5. https://www.zhenchao.org/2019/06/22/kafka/kafka-log-manage/