Hudi 在 vivo 湖倉一體的落地實踐

一、Hudi 基礎能力及相關概念介紹
1.1 流批同源能力
與Hive不同,Hudi數據在Spark/Flink寫入后,下游可以繼續使用Spark/Flink引擎以流讀的形式實時讀取數據。同一份Hudi數據源既可以批讀也支持流讀。
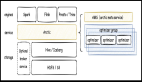
Flink、Hive、Spark的流轉批架構:

Hudi流批同源架構:

1.2 COW和MOR的概念
Hudi支持COW(Copy On Write)和MOR(Merge On Read)兩種類型:
(1)COW寫時拷貝:
每次更新的數據都會拷貝一份新的數據版本出來,用戶通過最新或者指定version的可以進行數據查詢。缺點是寫入的時候往往會有寫內存放大的情況,優點是查詢不需要合并,直接讀取效率相對比較高。JDK中的CopyOnWriteArrayList/
CopyOnWriteArraySet 容器正是采用了 COW 思想。
COW表的數據組織格式如下:

(2)MOR讀時合并:
每次更新或者插入新的數據時,并寫入parquet文件,而是寫入Avro格式的log文件中,數據按照FileGroup進行分組,每個FileGroup由base文件(parquet文件)和若干log文件組成,每個FileGroup有單獨的FileGroupID;在讀取的時候會在內存中將base文件和log文件進行合并,進而返回查詢的數據。缺點是合并需要花費額外的合并時間,查詢的效率受到影響;優點是寫入的時候效率相較于COW快很多,一般用于要求數據快速寫入的場景。
MOR數據組織格式如下:

1.3 Hudi的小文件治理方案
Hudi表會針對COW和MOR表制定不同的文件合并方案,分別對應Clustering和Compaction。
Clustering顧名思義,就是將COW表中多個FileGroup下的parquet根據指定的數據大小重新編排合并為新的且文件體積更大的文件塊。如下圖所示:

Compaction即base parquet文件與相同FileGroup下的其余log文件進行合并,生成最新版本的base文件。如下圖所示:

1.4 周邊引擎查詢Hudi的原理
當前主流的OLAP引擎等都是從HMS中獲取Hudi的分區元數據信息,從InputFormat屬性中判斷需要啟動HiveCatalog還是HudiCatalog,然后生成查詢計劃最終執行。當前StarRocks、Presto等引擎都支持以外表的形式對Hudi表進行查詢。
 圖片
圖片
1.5 Procedure介紹
Hudi 支持多種Procedure,即過程處理程序,用戶可以通過這些Procedure方便快速的處理Hudi表的相關邏輯,比如Compaction、Clustering、Clean等相關處理邏輯,不需要進行編碼,直接通過sparksql的語句來執行。
1.6 項目架構
1). 按時效性要求進行分類
秒級延遲:
 圖片
圖片
分鐘級延遲:

當前Hudi主要還是應用在準實時場景:
上游從Kafka以append模式接入ods的cow表,下游部分dw層業務根據流量大小選擇不同類型的索引表,比如bucket index的mor表,在數據去重后進行dw構建,從而提供統一數據服務層給下游的實時和離線的業務,同時ods層和dw層統一以insert overwrite的方式進行分區級別的容災保障,Timeline上寫入一個replacecommit的instant,不會引發下游流量驟增,如下圖所示:
 圖片
圖片
1.7 線上達成能力
實時場景:
支持1億條/min量級準實時寫入;流讀延遲穩定在分鐘級
離線場景:
支持千億級別數據單批次離線寫入;查詢性能與查詢Hive持平(部分線上任務較查詢Hive提高20%以上)
小文件治理:
95%以上的合并任務單次執行控制在10min內完成
二、組件能力優化
2.1 組件版本
當前線上所有Hudi的版本已從0.12 升級到 0.14,主要考慮到0.14版本的組件能力更加完備,且與社區前沿動態保持一致。
2.2 流計算場景
1). 限流
數據積壓嚴重的情況下,默認情況會消費所有未消費的commits,往往因消費的commits數目過大,導致任務頻繁OOM,影響任務穩定性;優化后每次用戶可以攝取指定數目的commits,很大程度上避免任務OOM,提高了任務穩定性。

2). 外置clean算子
避免單并行度的clean算子最終階段影響數據實時寫入的性能;將clean單獨剝離到
compaction/clustering執行。這樣的好處是單個clean算子,不會因為其生成clean計劃和執行導致局部某些Taskmanager出現熱點的問題,極大程度提升了實時任務穩定性。

3). JM內存優化
部分大流量場景中,盡管已經對Hudi進行了最大程度的調優,但是JM的內存仍然在較高水位波動,還是會間隔性出現內存溢出影響穩定性。這種情況下我們嘗試對 state.backend.fs.memory-threshold 參數進行調整;從默認的20KB調整到1KB,JM內存顯著下降;同時運行至今state相關數據未產生小文件影響。

2.3 批計算場景
1). Bucket index下的BulkInsert優化
0.14版本后支持了bucket表的bulkinsert,實際使用過程中發現分區數很大的情況下,寫入延遲耗時與計算資源消耗較高;分析后主要是打開的句柄數較多,不斷CPU IO 頻繁切換影響寫入性能。
因此在hudi內核進行了優化,主要是基于partition path和bucket id組合進行預排序,并提前關閉空閑寫入句柄,進而優化cpu資源使用率。
這樣原先50分鐘的任務能降低到30分鐘以內,數據寫入性能提高約30% ~ 40%。
優化前:

優化后:

2). 查詢優化
0.14版本中,部分情況下分區裁剪會失效,從而導致條件查詢往往會掃描不相關的分區,在分區數龐大的情況下,會導致driver OOM,對此問題進行了修復,提高了查詢任務的速度和穩定性。
eg:select * from `hudi_test`.`tmp_hudi_test` where day='2023-11-20' and hour=23;
(其中tmp_hudi_test是一張按日期和小時二級分區的表)
修復前:

修復后:

優化后不僅包括減少分區的掃描數目,也減少了一些無效文件RPC的stage。
3). 多種OLAP引擎支持
此外,為了提高MOR表管理的效率,我們禁止了RO/RT表的生成;同時修復了原表的元數據不能正常同步到HMS的缺陷(這種情況下,OLAP引擎例如Presto、StarRocks查詢原表數據默認僅支持對RO/RT表的查詢,原表查詢為空結果)。
 圖片
圖片
2.4 小文件合并
1). 序列化問題修復
0.14版本Hudi在文件合并場景中,Compaction的性能相較0.12版本有30%左右的資源優化,比如:原先0.12需要6G資源才能正常啟動單個executor的場景下,0.14版本 4G就可以啟動并穩定執行任務;但是clustering存在因TypedProperties重復序列化導致的性能缺陷。完善后,clustering的性能得到30%以上的提升。
可以從executor的修復前后的火焰圖進行比對。
修復前:

修復后:

2). 分批compaction/clustering
compaction/clustering默認不支持按commits數分批次執行,為了更好的兼容平臺調度能力,對compaction/clustering相關procedure進行了改進,支持按批次執行。
同時對其他部分procedure也進行了優化,比如copy_to_table支持了列裁剪拷貝、
delete_procedures支持了批量執行等,降低sparksql的執行時間。
3). clean優化
Hudi0.14 在多分區表的場景下clean的時候很容易OOM,主要是因為構建
HoodieTableFileSystemView的時候需要頻繁訪問TimelineServer,因產生大量分區信息請求對象導致內存溢出。具體情況如下:

對此我們對partition request Job做了相關優化,將多個task分為多個batch來執行,降低對TimelineSever的內存壓力,同時增加了請求前的緩存判斷,如果已經緩存的將不會發起請求。
改造后如下:

此外實際情況下還可以在FileSystemViewManager構建過程中將 remoteview 和 secondview 的順序互調,絕大部分場景下也能避免clean oom的問題,直接優先從secondview中獲取分區信息即可。
2.5 生命周期管理
當前計算平臺支持用戶表級別生命周期設置,為了提高刪除的效率,我們設計實現了直接從目錄對數據進行刪除的方案,這樣的收益有:
- 降低了元數據交互時間,執行時間快;
- 無須加鎖、無須停止任務;
- 不會影響后續compaction/clustering 相關任務執行(比如執行合并的時候不會報文件不存在等異常)。
刪除前會對compaction/clustering等instants的元數據信息進行掃描,經過合法性判斷后區分用戶需要刪除的目錄是否存在其中,如果有就保存;否則直接刪除。流程如下:

三、總結
我們分別在流批場景、小文件治理、生命周期管理等方向做了相關優化,上線后的收益主要體現這四個方向:
- 部分實時鏈路可以進行合并,降低了計算和存儲資源成本;
- 基于watermark有效識別分區寫入的完成度,接入湖倉的后續離線任務平均SLA提前時間不低于60分鐘;
- 部分流轉批后的任務上線后執行時間減少約40%(比如原先執行需要150秒的任務可以縮短到100秒左右完成 ;
- 離線增量更新場景,部分任務相較于原先Hive任務可以下降30%以上的計算資源。
同時跟進用戶實際使用情況,發現了一些有待優化的問題:
- Hudi生成文件的體積相較于原先Hive,體積偏大(平均有1.3 ~ 1.4的比例);
- 流讀的指標不夠準確;
- Hive—>Hudi遷移需要有一定的學習成本;
針對上述問題,我們也做了如下后續計劃:
- 對hoodie parquet索引文件進行精簡優化,此外業務上對主鍵的重新設計也會直接影響到文件體積大小;
- 部分流讀的指標不準,我們已經完成初步的指標修復,后續需要補充更多實時的任務指標來提高用戶體驗;
- 完善Hudi遷移流程,提供更快更簡潔的遷移工具,此外也會向更多的業務推廣Hudi組件,進一步挖掘Hudi組件的潛在使用價值。