搞定這個日志智能分析設計,大小故障都無處可逃
?一、背景
隨著系統的日益復雜,生成的日志是海量的。當發生故障時,人工從海量錯誤日志中定位異常的成本非常高,主要原因:
- 日志格式繁多,難以依靠人工劃分,而傳統的日志規則分類需要配置復雜的規則和正則,難以通用化;
- 日志量級大,報警多,難以定位需要關注的異常,一些無關的錯誤日志容易掩蓋真正的問題。
日志智能分類算法可以自動根據日志的相似性對日志進行流式聚類,并提取其中的關鍵信息——日志模版,有效避免相似日志的無效查看,大幅節省排查時間。并且日志異常檢測可以從海量日志中發現潛在的異常日志模式,幫助程序快速定位異常。
二、日志智能分類
1、設計方案
最初的日志分類服務在具體的算法選用上選擇了 Drain 算法來對日志模板進行提取。隨著業務經驗的累積,為了提高日志分類的準確性,用兩級模型對日志進行流式分類并生成日志模版。其中一次分類相當于是預分類,然后把預分類結果再進行二次分類,將預分類沒有分好的日志進行融合,形成最終滿足預期的分類結果。
2、一次分類
一次分類使用的是一種改進的前綴樹。
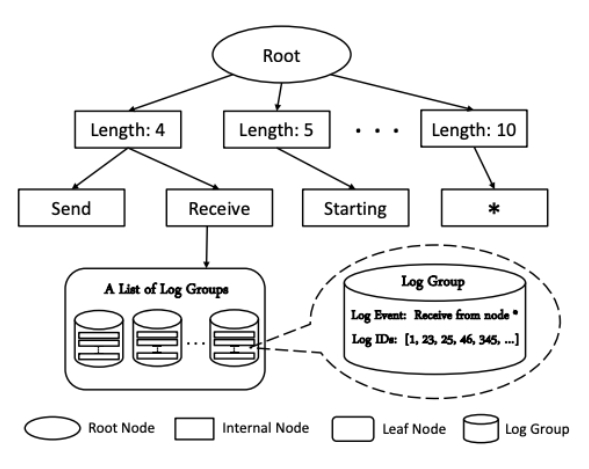
從根節點開始,第一層為長度層,同樣長度的日志進到同一個結點,接下來的節點就是根據token進行判別,只有匹配了同樣的token的日志,才往對應的路徑分。此外,還會設置一個閾值,當葉子結點到達閾值后,會增加一個<*>結點,用于匹配所有未成功匹配的日志。由于樹深是提前設定的,一般會設得比較小,因此匹配的速度會非常快。整個樹生成和匹配的過程實際上就是一個加入長度層的前綴樹。
算法流程如下:
- 預處理,以分隔符/空格為單位將日志切分為一個個的token;
- 根據日志token長度去第二層(每個節點對應一個長度)尋找對應節點,比如Receive from node 4匹配的節點對應日志token長度為4;
- 根據日志token按順序去進行分裂,這里受到depth限制,分裂樹深為depth-2(去除root和length層);
- 分裂到葉子節點后,計算日志與各個模板的相似度simSeq,返回simSeq大于閾值st并且相似度最高的模板;
- 更新Parsetree,當日志在葉子節點匹配到了模板,并且部分token有差異,則用<*>替換;當沒有匹配到模板時,則將新的日志加入到該葉子節點的模板列表,作為新的模版。
3、二次分類
二次分類使用的是基于最長公共子序列匹配的算法。

一次分類第一層會有一個長度匹配,那不同長度的日志必然不會被分到一類;而且一次分類是根據token的順序一個個匹配的,計算相似度也是順序計算的,兩條很像的日志,如果僅中間某些token劃分不能對齊,就會導致無法分到同一類。為了克服上述問題,引入了基于最長公共子序列的匹配算法,將一次分類獲得的模版進行二次合并,獲得聚類效果更佳的模版。同時,由于最長公共子序列的時間復雜度較高,因此設計了前綴樹、簡單循環等兩種前置預匹配方法,減少部分LCS的匹配,提升算法整體的效率。
算法流程如下:
1)預處理,以分隔符/空格為單位將日志切分為一個個的token。
2)前綴樹預匹配,可以匹配到則返回匹配的分類和模版;匹配不到轉到(3)。
3)簡單循環匹配,可以匹配到則返回匹配的分類和模版;匹配不到轉到(4)。
4)計算最長公共子序列,進行LCS匹配,可以匹配到則返回匹配的分類和模版,計算更新后的模版,差異部分用<*>替換;匹配不到則新增分類和模版。
4、traceback日志的處理
traceback日志與普通日志不一樣,普通錯誤日志以分隔符/空格來劃分token比較合適,但是traceback錯誤日志是一個trace的結構,按行看比較合適,因此把每一行traceback日志作為一個token,這樣可以把trace類似的錯誤聚到一起,方便查找問題。
5、解決冷啟動問題
日志智能分類算法會比較日志和模版,保留相同部分(常量),填充差異部分(變量)為<*>,更新模版,因此天然具有提取日志公共部分的能力。但是如果直接把原始日志輸入到算法中,需要較長時間才可以完成模版的收斂;且收斂后的模版與輸入的順序有很大的關系,無法獲得一個魯棒的結果。這樣會導致新接入的項目無法很好地應用日志智能分類。但如果能提前識別出變量,提前將其填充為<*>,則可極大地提升日志模版的收斂速度,也可以獲得更加魯棒的日志模版。通過正則將數字、base64編碼和地址編碼提前填充為<*>極大地提升了模版的收斂速度,原來要一周才能穩定并可用的模版,現在接入后馬上可用。
三、日志異常檢測
1、設計方案
目前業界對日志異常檢測的研究有很多,總結來說主要為以下幾類:

我們日志異常檢測算法主要是是基于統計+無監督的日志模版異常檢測算法,完全沒有人工標注成本,計算簡單并具有較好的可解釋性。目前日志異常檢測算法需要依賴日志智能分類算法,需要在獲得日志實時分類模版后,根據各模版的日志量的歷史數據進行異常判定,從而發現其中的異常模式,并將對應常通過告警發送給用戶。
2、具體算法
日志異常檢測算法設計為1min粒度的:
1)按機器維度獲取該機器的日志模版以及對應日志量的歷史數據。
2)將不同模版的日志量歷史數據使用卡方分布進行聚合。
3)對聚合后的數據進行異常檢測,當發現異常時,觸發(4),如果未發現異常,則返回結果為正常。
4)對每個日志模版對應的日志量的歷史數據進行異常檢測,根據異常程度,返回Top5的異常模版。
5)如果沒有返回異常模版,則本次檢測返回結果為正常;如果返回了異常模版,則本次檢測返回結果為異常,并將異常結果、異常模版告警。
這里的異常檢測設計為兩步主要是因為:
- 每臺機器的日志生成的模版數量都很多,對應日志量歷史數據中噪聲也較多,直接進行模版的異常檢測容易產生較多無效的報警;
- 模版數量較多,全量進行1min粒度的異常檢測計算壓力較大,可能不能在1min內完成檢測。因此考慮先從全局的角度設計一個噪聲較少的指標,先對該指標進行異常檢測,當異常檢測結果為異常后,再下鉆到具體的模版進行異常檢測,找到異常模版,既能減少誤報,也可以降低CPU壓力。
設計平方和作為全局具有代表性的指標,采用卡方分布進行數據聚合,假設n個模版的頻率特征符合標準正態分布,基于此構建模版的平方和特征,該特征滿足卡方分布,在n較大時,卡方分布可近似為正態分布,可以使用3sigma的方式進行異常檢測。

日志異常檢測使用的異常檢測算法除了使用3sigma方法外,還使用了箱線圖的方法,將兩者的結果轉換為異常分數后再進行融合。
3、減少周期性誤報
周期性異常是指昨天或者上周出現過的同樣的異常,此類報警屬于周期性誤報。此時,昨天或者上周對應時間點的異常分數也會較高,可以利用這個歷史分數對當前分數進行抑制,達到消除周期性誤報的效果。但是,出現異常的時間點可能會有一定的偏移,因此需要對昨天和上周一定時間窗口內的分數進行中心rolling_max操作,再使用當前異常分數減去昨天或者上周較大的那個分數,得到抑制后的分數。
4、新日志類別報警
某些情況下希望當出現新的日志模版類的時候,對新日志類別進行告警。但是當日志智能分類結果尚未穩定的時候,會經常出現新的日志類別,有可能產生很多誤報。我們設計了自適應的新日志類別報警,當一天內出現新的日志類別超過一定閾值時,對新日志類別報警進行抑制;當低于一定閾值時,進行新日志類別的告警。
四、應用效果

當日志異常檢測檢測到日志異常時,會告知用戶異常的模版。

進入日志計數頁面可以看到,當前時刻確實出現了異常的日志暴增。?