RTO縮短60%以上!平安銀行容災切換平臺建設實踐
一、背景與方案
1、業務連續性挑戰
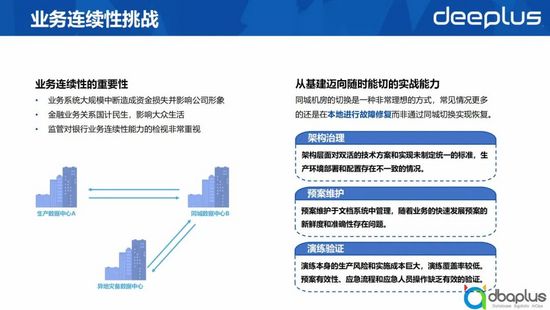
在銀行業,業務連續性是一個非常重要的領域。
- 業務系統發生大規模中斷會產生資金損失甚至影響公司形象。
- 金融業務關系國計民生,影響大眾生活。
- 監管對銀行業務連續性能力的檢視非常重視,會定期開展巡檢。
因此,很多銀行都建立了兩地三中心的容災能力。當基礎架構層面具有容災能力后,出現單機房故障時,通過同城機房的切換實現故障恢復是一種非常理想的故障處理方式。
但通過與同行交流發現,在出現單機房故障時,大家還是傾向于在本地進行故障恢復,通過同城切換來實現故障恢復的案例少之又少。主要原因如下:
- 架構治理: 架構層面對雙活的技術方案和實現未制定統一的標準,生產環境部署和配置存在不一致的情況。
- 預案維護: 預案維護于文檔系統中管理,隨著業務的快速發展預案的新鮮度和準確性存在問題。
- 演練驗證: 演練本身的生產風險和實施成本巨大,演練覆蓋率較低。預案有效性、應急流程和應急人員操作缺乏有效的驗證。
所以當有了容災的基礎能力后,距離隨時能切,想切就切的實戰能力還有一定距離。
2、業務場景切換能力
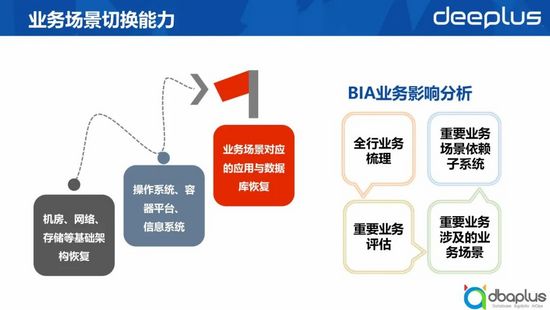
當業務系統或業務場景出現故障后,快速通過切換實現我們的恢復目標,是我們容災切換非常重要的能力。
我們往往將業務場景切換過程分為以下三個階段:
- 機房、網絡、存儲等基礎架構恢復;
- 操作系統、容器平臺、信息系統恢復;
- 業務場景對應的應用與數據庫恢復。
應用場景恢復過程往往在整個階段中耗時最久,因為它的切換對象數量極多。另外,業務場景與應用數據庫之間的關系非常復雜,維護預案的成本很高,所以當出現預案不準確的情況時,往往會導致故障恢復不能達到預期效果,增加故障恢復時長。
為了解決以上問題,我們會定期對全行業務進行梳理,找出產生故障后會導致巨大資金損失的關鍵業務,之后根據這些關鍵業務梳理出業務相關的業務場景,最后定位到這些業務場景所依賴的子系統。
3、面向子系統的容災能力
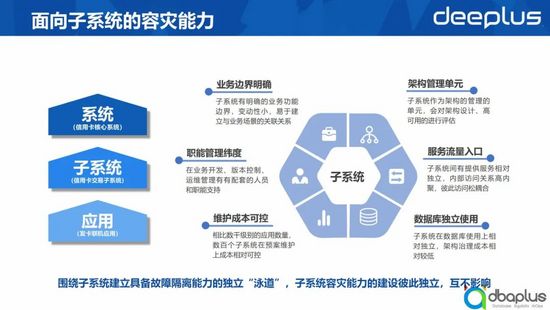
當每一個子系統都建成同城容災的能力后,我們就可以認為我們的業務具備了同城級別的容災能力。換言之,當我們的業務場景出現故障時,我們可以通過切換對應的系統快速恢復故障。
IT架構往往分成系統、子系統以及應用三個層次,系統由多個實現特定業務功能的子系統組成,每一個子系統又由多個實現特定業務邏輯的應用組成。
我們在建設容災能力時,目前選擇子系統作為容災建設的最小單位,原因有以下幾點:
- 業務邊界明確: 子系統有明確的業務功能邊界,變動性小,易于建立與業務場景的關聯關系;
- 職能管理維度: 在業務開發、版本控制、運維管理有配套的人員和職能支持;
- 維護成本可控 : 相比數千級別的應用數量,數百個子系統在預案維護上成本相對可控;
- 架構管理單元: 子系統作為架構的管理單元,會對架構設計、高可用等進行評估;
- 服務流量入口: 子系統間有提供服務相對獨立,內部訪問關系高內聚,彼此訪問松耦合等特點;
- 數據庫獨立使用: 子系統在數據庫使用上相對獨立,架構治理成本相對較低。
二、預案一鍵切換
1、雙活架構模型
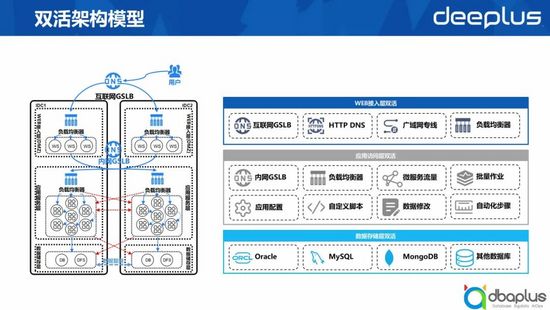
上文中我們講到通過子系統建設容災能力,子系統在切換時,其實是將故障機房的一些服務全部拉出,然后把流量和服務切換到服務正常的同城機房。
那么對于一個完成改造的子系統而言,它的服務分成三層,切換時需要對這三層的一些組件做解綁動作。最上面的一層是互聯網的流量,例如我們公網的GLSB和 HTTP DNS等流量,也有一些廣域網的專線,還有一些負載均衡的服務。 當流量進入內網后,我們通過內網的GSLB與負載均衡的切換實現HTTP層的流量調度。 對于一些微服務的流量,我們通過注冊中心的 一些流量 拉入拉出實現流量的切換。
除了以上三種,銀行中還有一個比較特殊的服務模式——跑批,即晚上對當天的交易進行復核,跑批的結果會直接影響第二天銀行能否順利開門,也會間接影響我們服務的可能性。 在這個過程中,我們會對作業在哪個地方去跑等做一些切換控制。
理論上,當子系統完成了一些架構改造后,通過這些流量的調度切換,就可以完成我們的工程切換。但實際上,也有一些長尾問題,比如有些子系統做一些雙活的改造成本很高,或它是一些比較老的外購系統,這樣的系統比例不高,但很重要。所以我們支持這些子系統切換的時候,提供了一些更加靈活的切換能力,比如我們支持做一些應用配置的修改,或者執行自定義的腳本,甚至會提供一些數據庫層面的數據修改能力,讓那些非標的子系統具備自動化、快速切換的能力,提高應急切換效率。 在數據庫層面,更多的是像 Oracle、Mysql或MongoDB等數據庫組件的切換。
2、原子預案編排
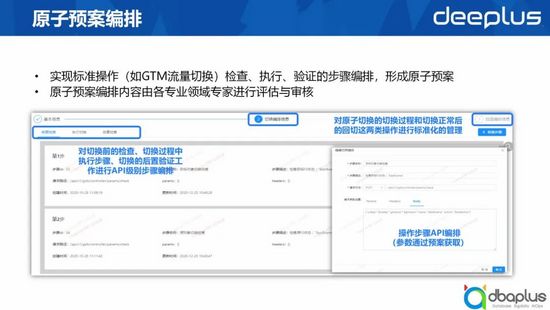
在切換過程中,每一個類型的切換,我們內部都稱之為一個原子的預案,切換工具會對這些原子預案進行預案編排。在執行前,我們有一個檢查階段,來確保目前處于適合切換的狀態,才能執行。
當完成執行動作后,我們還需要通過驗證來確保執行目標的達成,但具體步驟不是由我們的工具提供,這些能力是由數據庫團隊或平臺架構團隊的變更能力提供。而我們的平臺是通過HTTP的方式,讓他們對執行、檢查的步驟進行快速編排。這種檢查、執行、驗證的編排模式,讓大家的切換能力變得更加標準化,也更加安全。
當我們完成切換后,往往還需要對服務進行恢復,切換是從雙活變到單活的過渡,當故障恢復后或演練要回切時,我們也會把單活的能力回退到雙活的模式,這時候會有一個回退的編排。在回退編排中要做一些檢查、執行和驗證動作的編排。
由于每一個原子預案都是很基礎的預案,風險非常大。所以當我們的預案要發布時,會請每個領域的專家對預案的內容進行評估,甚至做一些測試來保證預案能達到相應效果,保證預案本身的安全性。
3、子系統應急預案
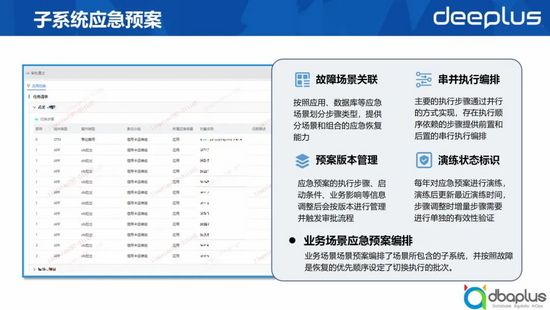
1)故障場景關聯
當我們有了原子預案能力以及明確的系統切換清單后,我們就可以在子系統層面編排子系統的預案,這個預案內容可能會包含一些應用、網絡以及數據庫的操作。當做子系統切換時,這些動作需要同步切換。但是我們可以將對應的故障場景進行區分,盡可能降低切換范圍。
2)串并執行編排
我們完成雙活改造后,切換對象之間的切換都是獨立的,所以我們默認通過一些并行切換的方式提升整體切換效率。
但是因為有一些長尾問題,例如有些子系統在切換之前需要先關閉一些流量才能執行后面的切換動作,所以我們最終提供的是串并行結合的編排能力。
3)預案版本管理
因為架構一直在發生變化,當架構發生變化之后,工具能夠捕獲到這種變化,我們會將這些變化信息同步給對應的預案維護人,他們可以通過這些提示信息對預案進行實時更新,以免發生價格變化后預案更新不及時的情況。
4)演練狀態標識
預案維護后是未驗證的狀態,只有當子系統完成一次演練后,我們才會認為這個預案處于安全有效的狀態,所以我們會在預案沒有演練前,提示其切換過程中可能存在的風險。
以上4個能力是子系統預案編排過程中比較關鍵的能力。當我們的子系統具備了預案管理能力后,我們再去做業務場景的編排會更容易。我們只需要明確業務場景中包含了哪些子系統,并按照故障恢復的優先順序設定切換執行的批次即可。
4、執行過程可視化
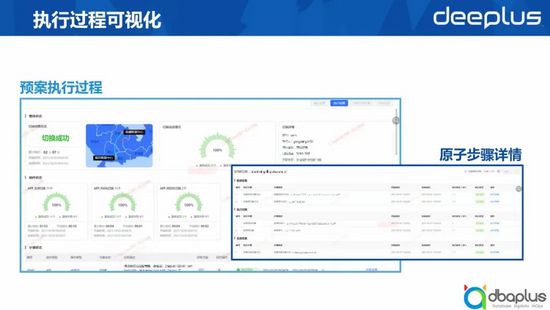
在執行過程中我們會提供預案執行過程的看板,展示目前切換的耗時與執行成功與否,以及每一類組件切換的進度和狀態。在執行過程中,如果說有一些步驟或一些預案執行失敗,我們也可以通過一些下鉆查看具體的報錯原因。
5、工具可用性
每年的演練非常多,我們希望通過自助的方式,讓運維、DBA以及一些演練執行人能夠自助解決一些問題。
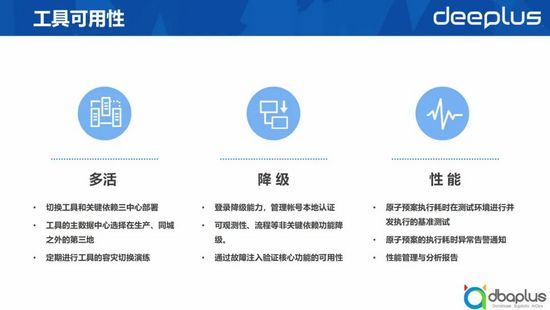
上文講的是如何通過工具體系提高業務系統的可能性,其實工具的可用性相比業務系統的可能性要求更高,因為發生故障時,你期望通過工具對業務系統進行恢復。我們在工具建設過程中,提出了更高的可能性要求。
1)多活
切換工具及其關鍵依賴,我們會在三個數據中心進行部署。這三個數據中心包含我們的同城機房,生產機房,還有第三地機房。我們會默認把主服務部署在第三地機房。這樣當同城和生產機房出現問題時,工具可以快速接管服務,實施切換動作。
切換工具,其關鍵依賴,以及變更能力是工具的核心能力,發生故障時這些能力不能出現任何問題,所以我們會定期對這些強依賴或關鍵依賴做一些容災切換演練。
2)降級
登錄等能力是切換工具的弱依賴,切換工具的核心能力是切換。當這些能力出現故障時,我們要盡量避免它對我們核心切換能力產生影響,所以我們會定期通過故障注入或者主動降級來做一些弱依賴的降級演練,確保弱依賴發生故障時,核心功能不受影響。
3)性能
我們也會對切換原子預案的執行性能做一些測試。我們在每一個原子預案上線前,會要求預案提供方提供性能測試的基準,明確指出每一個原子預案執行的并行度是多少,以及在對應并行度下切換的SLA是多少。這種情況下,工具可以對原子預案的執行做流控,保證切換過程的穩定性。
三、運行可觀測性
在執行切換過程中,切換的實施人要實時關注切換服務的運行狀態是否出現異常,以及是否達到相應效果。
1、運行監控
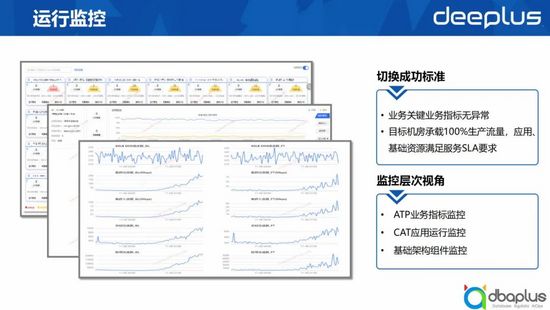
在應急或演練時,我們會有一個切換成功的標準:切換完成后,業務的關鍵指標沒有明顯波動,目標機房要承載100%的生產流量,應用層和基礎層對應服務的一些能力滿足對應的SLA要求。這需要我們給演練的實施人提供信息匯聚的能力,包括業務層、應用層以及基礎架構層面的監控能力。
2、架構可觀測性
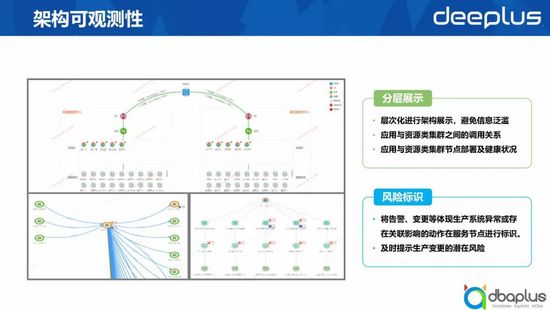
除監控能力外,我們也會以清單形式展示對應組件的情況。異常展示是分層的,只有出現異常時,我們才會下鉆查看實際部署的異常展示。另外,我們也會將告警、變更等體現生產系統異常或存在關聯影響的動作在服務節點進行標識,及時提示生產變更的潛在風險。
3、運維數據中臺
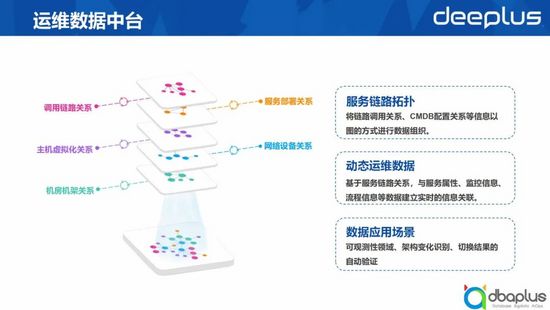
以上提到的展示能力都依賴于運維數據中臺實現。
在運維數據中臺中,我們會將服務之間的調用關系以及CMDB的一些部署信息組合成一張拓撲關系網,并在每一個拓撲節點上附加一些配置屬性、監控的 url 地址以及變更等信息,豐富每一個拓撲節點的數據。當有了拓補和信息之后,我們就可以快速提供可觀測性能力,包括預案維護過程中識別架構變化的能力,以及一些自動化驗證的能力。
四、演練線上化
當我們有了一鍵切換能力以及可觀測性能力后,我們還需要通過演練驗證人員的有效性、預案本身的有效性以及流程的有效性。中間過程中還要解決一些問題。
我們的同城子系統切換演練,其實是一個子系統層面的中高風險生產變更。在變更方案制定過程中,我們要盡可能避免因為方案層面問題產生的影響。
1、方案風險控制
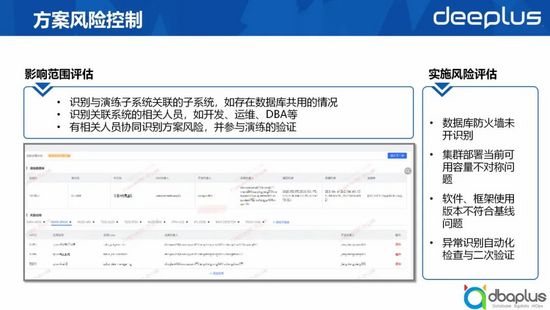
1)影響范圍評估
我們的演練是為了提高生產的穩定性,所以我們在演練過程中,會對演練的影響范圍做評估,主要包括以下幾方面:
- 識別與演練子系統關聯的子系統,如是否存在數據庫共用的情況;
- 識別關聯系統的相關人員,如開發、運維、DBA等;
- 有相關人員協同識別方案風險,并參與演練的驗證。
2)實施風險評估
我們也通過工具對實施風險進行評估,主要包括以下幾方面:
- 數據庫防火墻未開識別;
- 集群部署當前可用容量不對稱問題;
- 軟件、框架使用版本不符合基線問題;
- 異常識別自動化檢查與二次驗證。
有了上述能力后,我們就可以大幅度規避方案層面的一些風險。
2、演練流程管控
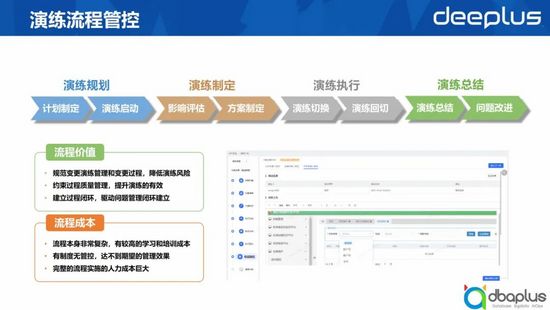
第二個風險是流程控制層面的風險。一個完整的流程,對降低演練過程的風險非常有幫助。流程的存在,也能夠提升演練的有效程度。對于演練過程中發現的一些問題,我們可以通過問題管理的一些流程跟進,關注它的持續解決。
但是流程的存在也會產生一些成本。因為流程本身非常復雜,有較高的學習和培訓成本,并且在有制度無管控的情況下,達不到期望的管理效果,同時,完整的流程實施還會產生巨大的人力成本。
所以我們將線下流程變到線上時,對這些信息做了一些梳理,通過一些強流程的控制,對那些存在變更風險或流程風險的地方做了設置的關卡,來規避一些流程中的風險。對于一些本身很復雜的流程,我們通過提示及引導的方式大大降低用戶演練門檻。
3、演練效能提升
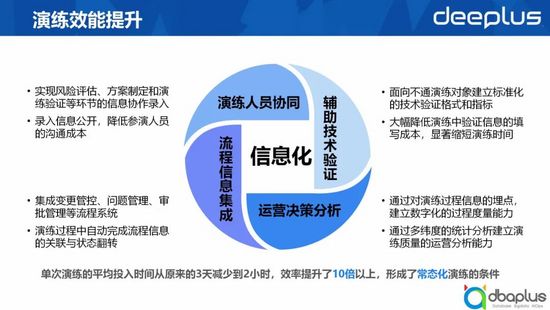
我們在工具層面做了一些信息優化,來提升流程的效率。沒有工具之前,單次演練的累計時長加起來可能長達三天時間,如果考慮它的起始時間,甚至可能長達一個月。當我們將演練線上化后,我們工具從四個方面提升了演練效能,縮短了演練時長。
1)演練人員協同
線上化演練可以通過識別,實現風險評估、方案制定和演練驗證等環節的信息協作錄入,這樣的話我們演練的負責人只需要對結果做review和確認就可以完成演練的制定,大大降低了溝通協同成本。
2)流程信息集成
線上化演練可以集成變更管控、問題管理、審批管理等流程系統,并且在演練過程中自動完成流程信息的關聯與狀態翻轉。
3)輔助技術驗證
線上化演練可以通過面向不同演練對象建立標準化的技術驗證格式和指標減少驗證成本,還能夠自動生成驗證信息,大幅降低演練中驗證信息的填寫成本,顯著縮短演練時間。
4)運營決策分析
線上化演練可以通過對演練過程信息的埋點,建立數字化的過程度量能力,并且通過多緯度的統計分析建立演練質量的運營分析能力,提高演練流程的質量和效率。
有了上述能力后,單次演練的平均投入時間從原來的3天減少到2小時,效率提升了10倍以上,同時形成了常態化演練的條件,可以大幅提高我們演練的覆蓋率。
4、演練模擬執行

上文講述的內容是通過演練的方式驗證切換預案內容本身的有效性,除此之外還應該驗證人員的有效性以及流程的有效性。這些有效性往往通過培訓或桌面沙盤模擬,以及應急響應演練來實現,因此我們開發了一套模擬執行的機制。通過模擬執行的方式,可以提升我們一線團隊、一線同事對于切換流程的熟悉程度,也可以驗證我們流程的有效性。
5、演練過程指揮
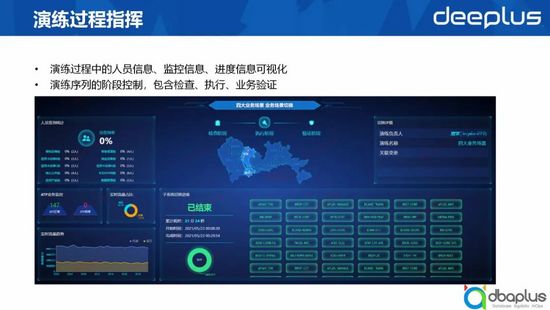
我們在做大規模演練的時候,會產生一些指揮層面的需求。
比如我們的演練負責人需要關注參加當次演練的人員信息以及所設計業務監控的正常程度,并且需要關注切換過程中數據中心的流量變化。那么通過我們的指揮大屏,指揮官可以清晰看到數據中心運行信息。在演練過程中,我們也會將每個子系統的切換進度在大屏上進行展示。
五、上線后的收益
1、業務連續性能力提升
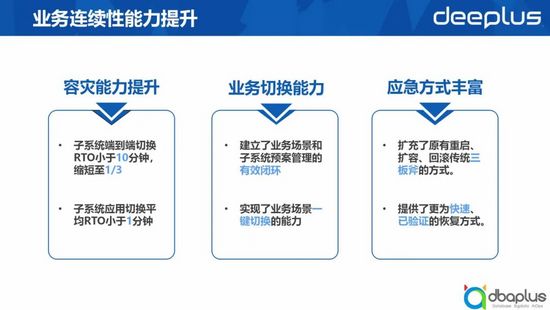
1)容災能力提升
我們實現了容災切換平臺后,整個切換時長得到了大幅提升。目前我們一個子系統端到端的切換RTO小于10分鐘,縮短至了原來的三分之一。
對于應用類的切換,RTO的值更小,因為應用類切換的成本主要是不同系統之間的操作成本,當我們去按照一個預案批量執行時,基本上幾秒鐘就可以完成。
2)業務切換能力
那么因為我們建立了業務場景與子系統之間的關系,子系統又完成了預案管理的閉環,所以我們具備了業務場景切換的預案維護的閉環能力。當業務場景出現故障時,我們可以快速通過子系統的切換實現業務場景的一鍵恢復。
3)應急方式豐富
原來我們發現一些故障的時候,往往是通過重啟、擴容、回穩這傳統的三把斧方式恢復故障。有了切換能力后,我們有了更快速的方式,可以通過切換來快速恢復服務,同時切換的方式也是經過驗證的,所以它也是一種較為安全的故障恢復手段。
2、變更安全能力提升
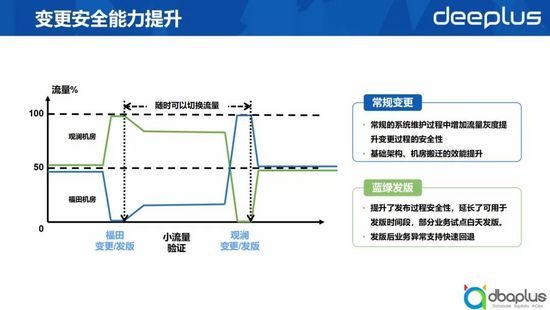
除了業務連續性能力提升之外,我們還發現了額外的驚喜。
1)常規變更
我們原來去做一些技術架構層面的變更,無論是應用運維還是技術架構的同事都非常擔心,變更可能產生一些較大規模的故障。
當我們具備切換能力后,再進行機房維護時,我們就會提前將這些應用的流量及相關一些子系統的流量切換到我們的通訊機房,保障變更過程中的安全性。當我們完成技術架構變更時,再分批將流量切回來,大大提升了安全系數。
2)藍綠發版
原來我們行業的發版主要集中在周二和周四,對于一些關鍵系統,這個時間點往往在周二周四的凌晨兩三點鐘,對于運維人員很不友好。當我們有了切換能力后,發布過程的安全性提升了,可用于發版的時間段延長,同時發版后業務異常支持快速回退。
Q&A
Q1:是否有必要進行以存儲為中心的容災演練,相比應用為中心的容災演練有什么區別?
A1: 我們在做容災切換時,不僅做應用層的,也會做數據層的。所以我理解這個切換應該是應用與數據庫整體的切換,至于存儲部分是由技術架構團隊單獨實施。
Q2:在演練之前如何確保兩邊的數據是一致的?
A2: 我們目前在應用層有一些巡檢機制,所以我們會定期做一些檢查,在切換之前也會做檢查工作,我們切換前后不能說一致,但至少生產的機房跟同城機房之間,處于可切換狀態,數據庫層面通過數據來實現切換。
Q3:切換后增量的數據可以恢復到原生產數據中心嗎?
A3: 這個問題在演練跟應急過程中有一些區別,演練過程中我們會盡可能避免數據丟失的行為,因為演練過程中有一個Switch over的切換方式,但是真正發生生產應急的時候,Switch over的方式時間會比較久。真正發生生產應急的時候,我們會用vivo的 方式做切換,這個時候其實會有一些數據丟失,丟失的數據由DBA同學修復。
Q4:一年進行幾次容災切換的應急演練?
A4: 我們有一個要求,兩年之內要對我們的核心系統做到演練覆蓋,所以每年的演練數量基本多達幾百次。
Q5:切換是僅限同城嗎?
A5: 我們在建設容災能力時,有同城能力也有災備能力,但因為大數據是實時復制的,同城機房與生產機房都有流量,所以切換的安全性更高一些。兩個同城機房都不可用的情況之下,我們才會做一些災備切換,二者的使用頻率跟場景是不一樣的,所以我們的演練災備機房也會有,但同城演練的頻率可能更高一些。
Q6:平時業務在兩個中心同時跑,是按照1:1的比例分配流量,如果是應用層面的問題,一般兩中心同時都有問題,那么切換是否就沒有意義了?
A6: 我們平時的流量是在生產跟同城機房以1:1的形式部署的,如果一個節點出現一個問題,物理設備出現一些問題,或單機房的PaaS服務出現一些問題,故障往往是單機房的。如果應用層面出現問題,例如容量問題,這種情況通過切換是解決不了的。所以容災切換只適用于部分場景,并不能解決所有問題。