作者 | 汪陽
背景
自動化測試從最早期的錄制回放技術開始,逐步發展成DOM對象識別與分層自動化,以及基于POM(Page Object
Model)來提高用例復用,到當前火熱的基于AI技術的自動化,體現了自動化測試的發展趨勢是更加智能,更加精準,更加高效。
在這里我們給大家介紹兩種在業界已經有廣泛使用的智能自動化測試技術:
- 自愈(Self-Healing)技術?
- 機器學習(Machine Learning)技術?

自愈技術
1. 什么是自愈技術
自愈(Self-Healing)技術在計算機術語中是指:一種自我修復的管理機制。
類比生命體,當生命體遭受到一些小的傷害時,它們的身體往往能夠通過自身的修復機制來實現自愈,而不需要外界加以干預。如壁虎的斷尾再生,或者蟹類的軀體再生能力那樣。
回到計算機領域,自愈技術也在廣泛地使用,比如芯片的信息通道自愈,軟件系統的故障自愈等。那么我們這里要介紹的是在自動化測試方向上的一種自愈技術:
可以發現其測試腳本執行中的非預期錯誤,并在無需人工干預的情況下自行更改,從而將自身恢復到更好的運行狀態。
2. 原理介紹
問題域:在自動化測試中使用自愈技術主要解決的是對象識別(object identification)問題。
傳統的自動化測試框架和工具,使用應用程序模型來定義應用程序的組件和對象及其屬性。然后使用這些定義來識別和操作應用程序組件。但是應用程序在更新時會經常更改。可能是有意的開發人員變更或者是即時(由應用程序系統或構建過程)發生的。這些變化破壞了我們基于靜態定義的傳統自動化方式。
自然語言處理(NLP)和機器學習 (ML) 等智能技術已經發展到測試腳本現在可以“學習”和“適應”的地步;自愈式自動化測試工具使用 AI 和機器學習技術,根據用戶界面 (UI) 或應用程序環境的變化,可以自動更新和調整測試過程。
在運行測試時,它們會掃描應用程序的用戶界面以查看是否存在任何對象。然后它們將這些對象與之前為自動化測試生成的應用程序模型進行比較。如果應用程序有任何更改,則有一種技術可以讓測試適應并自動更新。這種能力被稱為“自我修復”。屬性更改是自動感知的,內部腳本在運行時通過自我修復進行自我修復。
自愈功能具有以下兩個顯著特點:
- 在執行過程中,如果某個測試步驟定位器無法被其默認定位器值檢測到,則列表中的其他定位器策略將自動應用,無需測試人員的任何手動干預。執行將繼續,就好像沒有發生任何故障一樣。?
- 在執行過程中,如果測試步驟定位器失敗,并且無法使用任何其他定位器策略自動檢測到,測試將暫停執行,允許用戶選擇相關元素并繼續執行。新的定位器策略將在下次執行時自動更新。?
下圖介紹了自愈技術的主要步驟:

(圖片來源:https://www.impactqa.com/blog/5-great-ways-to-achieve-complete-automation-with-ai-and-ml/)
自動化測試自愈技術的優勢主要有:
(1) 減少測試失敗率
測試執行失敗很正常,但是有時候失敗的根本原因僅僅是由于用戶界 面發生了變化而測試腳本沒有同步變化。使用自愈技術后,由于無法正確識別的對象位置而影響腳本執行失敗的情況就不太可能發生。而傳統的自動化方式無法識別這些變化并自動更新。
(2) 提升測試穩定性
如果我們測試過程中有flaky tests存在的話,我們很難確定我們的測試是否是穩定的。”NoSuchElementException“ 錯誤是導致測試設計不穩定的幾個錯誤之一,測試團隊很難完全控制這樣的現象發生。而當我們的測試設計和應用程序保持一致時,測試在執行期間失敗的可能性較小,并且執行過程也更加順暢。
(3) 提高腳本維護性
測試代碼中的更改與開發人員在應用程序中所做的更改成正相關。由于測試失敗的原因可能會發生變化,并且不能反映 AUT 的真實狀態;因此失敗的測試結果會限制測試人員獲得有關其測試的有意義的見解。通過識別和更新用戶界面中的任何更改的測試用例,自愈技術節省了敏捷測試和開發團隊的時間和精力。除了時間和精力之外,測試自動化中的自我修復也顯著降低了測試腳本維護成本。
3. 業內實踐
我們可以看到,業內已經有一些比較好的實踐了,比如Healenium項目。
以Healenium項目為例,看看自動化測試自愈技術是怎么工作的:
假設我們通過id 的方式來定位應用程序界面上的一個按鈕,定位器應該是:#button
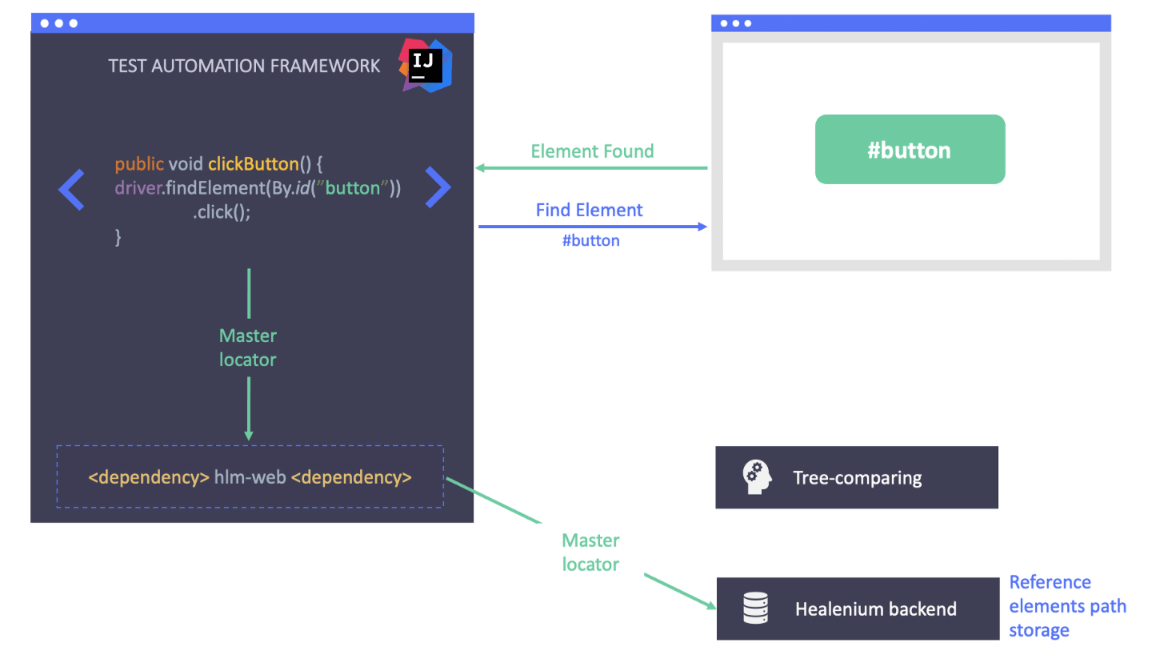

從上圖可以看到,元素可以被正確定位到。Healnium會將正確的定位器保存下來,作為下一次測試執行的基準值。現在,我們假設開發人員變更了應用程序的UI界面,改變了這個按鈕的id屬性,從#button變更為#green_button。但是由于某種原因,測試團隊沒有被通知到有這個變更,所以測試腳本也沒有更新。那么當我們再次執行腳本的時候,在嘗試使用#button的舊定位器去定位按鈕的時候,腳本就會報錯,提示 “NoSuchElement”的錯誤異常。

在這種情況下,使用標準的 Selenium 實現測試將失敗,但使用 Healenium 則不會。Healenium 捕獲 NoSuchElement 異常,觸發機器學習算法,傳遞當前頁面狀態,獲取之前成功的定位器路徑,比較它們,并生成修復的定位器列表。它采用得分最高的定位器并使用該定位器執行操作。正如我們看到的元素被成功找到并通過了測試。

測試運行后,Healenium 生成報告,其中包含有關修復定位器、屏幕截圖和修復成功反饋按鈕的所有詳細信息。

如果修復成功,我們可以使用 Healenium Idea 插件更新我們的自動化測試代碼:插件使用修復定位器尋找修復和更新測試代碼。

Healenium 使用一種機器學習算法來分析當前網頁的變化:基于權重的最長公共子序列算法.
更多關于這個項目的詳情,可以訪問這個項目官網:https://healenium.io/
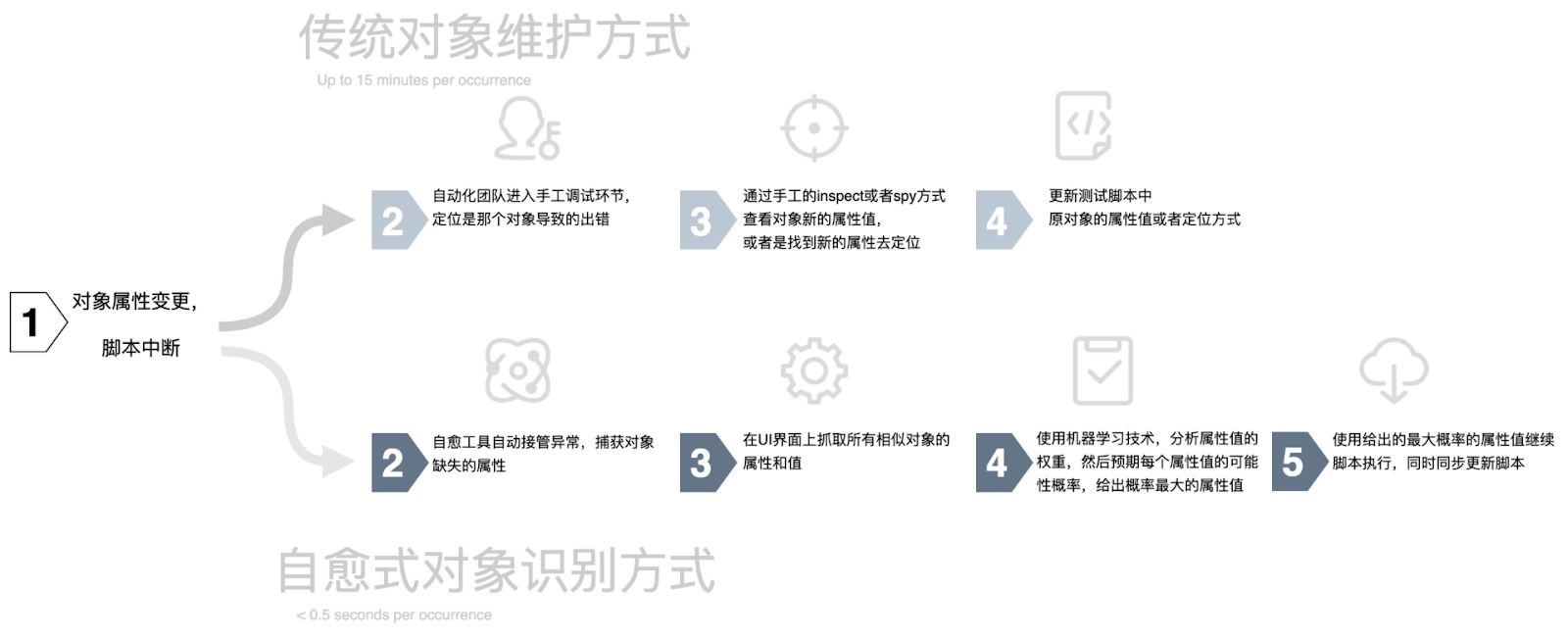
通過這個案例,我們來對比一下傳統自動化測試方式和基于自愈技術的自動化測試方式中對象維護的差異(如下圖所示):
二、機器學習
在上一部分,我們介紹了通過自愈技術解決自動化測試過程中對象識別問題。但是在自動化測試過程中,我們仍然還會面臨其他問題:
- 仍然需要人工獲取定位方式;?
- 如果是通過Canvas繪制出來的對象,如何識別元素 (如Flutter Web)。?
等等。
雖然自愈技術在傳統的自動化測試中增加了一些容錯能力。但是本質上還是基于元素定位的對象識別技術,用到的還是傳統的DOM定位技術,如XPath或者是CSS定位器。
而我們知道,移動端和Web端的運行環境復雜,外部干擾因素很容易破壞自動化腳本運行的穩定性,這是元素定位器脆性本質導致的。
所以業界也一直在持續探索更穩定的對象識別技術。在早期我們使用到了CV(Computer Vision)計算機視覺 +OCR(Optical Character Recognition)光學字符設別技術。
而CV和OCR是基于圖像處理和統計機器學習方法。
比如業內比較流行的自動化測試框架airtest,就是基于CV技術來進行智能控件識別的。
通過OCR及圖像識別能力,實現相同流程下,一套自動化腳本可以在多平臺上執行的能力,大大降低了腳本編寫及后期維護成本。
目前業界也在實踐與探索基于機器學習技術的CV和OCR來解決自動化測試學習成本高、維護成本高、Hybird識別差、跨應用能力差,以及不支持跨平臺等方面的問題。
1. 智能識別
在UI頁面中,我們的信息主要由圖像和文字構成。如何高效地識別基于圖像和文字的控件對象,是當前自動化測試不得不面臨的問題。為了解決之前基于DOM技術的元素定位不穩定,以及后期的維護成本。目前在UI控件識別上有兩種方式:一個是基于CV技術的圖像識別,一個是基于OCR技術的文字識別。
(1) 基于CV的圖像識別
a. 傳統的CV
在傳統方式下,我們主要是基于圖像特征識別技術:
提到圖像識別算法一定繞不開OpenCV,常用的是SIFT算法,核心就是提取出圖片當中的一些關鍵特征,這些特征在不同的機型,在不同的分辨率下面有很好的適應性。基于傳統特征識別技術的處理過程如下圖所示:

b. 基于深度學習的CV
這種方法比現行的定位策略( image )更靈活,因為我們可以用CNN,或者其他深度學習框架來訓練 AI 模型去識別控件圖標,并不需要知道上下文,也不需要精確匹配控件圖標。也就是說我們可以能跨應用和平臺去找一個如 “購物車” 的圖標這樣的控件,不需要在意一些細微的差別。基于深度學習的處理流程如下圖所示:

盡管基于深度學習的CV具有更強的能力,但是傳統的方式依然有不可替代的優勢,值得我們繼續學習。如從目前來看深度學習仍然需要大量的數據,而傳統的方式在這方面就會節省很大的成本。對于一些比較簡單的識別任務,我們更推薦傳統的CV方式。
(2) 基于OCR文字識別
OCR可識別屏幕上的預定義字符。使用OCR的軟件將采用“最佳猜測”的方式來確定圖像是否與字符匹配,以便將該圖像轉換為計算機可以處理的文本。傳統的OCR基于圖像處理(二值化、連通域分析、投影分析等)和統計機器學習(Adaboost、SVM)。
傳統的OCR只能處理相對簡單的場景,如:簡單的頁面布局、前景和背景信息便于區分及每個文本字符容易分割。隨著我們的測試對象月來越復雜,頁面布局,樣式等多樣化的場景下,傳統OCR的精準度也受到了挑戰。
隨著深度學習的發展,我們可以通過新的算法技術來解決傳統OCR的局限性。
2. 案例實踐
在業內,大部分基于AI的自動化測試平臺均采用了CV+OCR結合的智能識別技術,來降低自動化測試腳本編寫成本以及后期的維護成本。我們分別以基于OpenCV的airtest 平臺為例:基于OpenCV的UI自動化 - AirtestAirtest主要用到了兩種傳統的OpenCV匹配算法:模版匹配和特征匹配。
模板匹配:
- 無法跨分辨率識別
- 一定有相對最佳的匹配結果
- 方法名:"tpl", "mstpl"
特征點匹配:
- 跨分辨率識別
- 不一定有匹配結果
- 方法名列表:["kaze", "brisk", "akaze", "orb", "sift", "surf", "brief"]
在Airtest中可以自己配置選擇使用的匹配算法。由于兩種匹配算法各有利弊,因此一般默認是選擇這幾種匹配算法組合,算法依次進行圖像識別,找到結果將停止識別,未找到結果將會一直按照這個算法的識別順序一直循環識別直到超時。
如何判斷圖像識別成功或者失敗呢?Airtest里面有兩個重要的名詞:閥值和可信度,閥值是可以配置的,一般默認為0.7,可信度是算法執行結束后計算出來的可能性概率,當 可信度>闕值 的時候,程序會認為 找到了最佳的匹配結果 ;而當 可信度<闕值 的時候,程序則會認為 沒有找到最佳的匹配結果 。
如下這個例子:在Airtest中操作網易云音樂APP :

Touch(“圖片”) 的原理如下:

Airtest本身并沒有直接提供OCR方式識別,不過我們可以通過集成開源的Tesseract-OCR庫來支持OCR識別能力。
面臨的挑戰:
基于傳統的OpenCV的圖像識別,主要的問題是圖像的特征識別不夠準確,特別是在圖像本身的特征比較少,如有一大片白色背景等,或者是動態元素等。同時傳統的識別成功率平均也就80%左右,還達不到人工的95%的準確率,因此在傳統方式下,我們只能通過添加更多特征信息來優化識別率,但是想要匹配人工的準確率,傳統的統計機器學習方式很難達到。
解決這個問題就需要更強的泛化能力,目前更多的是基于CNN等深度學習技術來解決此類問題。我們這里就不過多展開,大家可以參考Appium with AI項目。
詳情:https://appiumpro.com/editions/39-early-stage-ai-for-appium-test-automation
3. 未來展望
隨著DL,RL和NLP等技術的不斷發展,未來是不是完全可以將我們的用戶故事自動轉化為自動化測試用例,做到了真正的零代碼呢,目前業內也有這樣的探索了,我們也在持續跟進。
CV和AI算法的加持讓UI自動化測試在對象識別上有了新的突破,但依然無法擺脫軟件層API操作的局限,受所在操作系統限制,依舊存在部分特定場景下元素無法識別的問題(如系統內Push消息操作)。
我們可以看到業內領先的公司在嘗試自動機械臂方式,來解決這個問題。
如下圖阿里的Robot-XT:

(圖片出處:https://mp.weixin.qq.com/s/5ZngQyJiRZy6714-CC498g)
那么這些技術是否是大廠的“專利”呢? 我想答案是否定的,未來AI技術一定也會像水電煤一樣,變成最基礎的底層設施,我們只需要會用即可。
三、總結
在本文中,我們介紹了兩種應用比較廣泛的自動化測試新技術,目的是幫助大家了解自動化測試未來的發展趨勢,從而更好地利用新技術來提高我們的測試效率。
自動化測試未來趨勢不僅僅是這兩種,還有如智能化探索性測試,智能遍歷測試以及智能驗證等。