總結出這套數據庫遷移經驗,我花了20年……
?數據庫遷移是DBA經常會面臨的工作,這二十多年來,我們也做過很多數據庫遷移的工作。早期的時候,作為一個DBA,考慮遷移方案的時候總是從數據庫的角度去考慮。隨著項目做多了,知識范圍不斷地擴大,加入了很多系統級的遷移方案,使遷移工作變得更加簡單了。遷移工作做多了,也難免會遇到鬼,在這二十多年,上百個遷移項目中,也確實遇到過不少坑,有時候甚至面對命懸一線的絕境。
?到了后來,面對遷移方案的選擇,如果是十分重要的核心系統,一定要選擇最為穩妥的方案,以備不測。昨天微信群里有人在問一個數據庫想遷移存儲,有沒有什么好方案,從我腦子里冒出來的都是系統層面的遷移方案,而群里的DBA朋友往往都說的是數據庫層面的遷移技術。實際上沒有最好的技術和方案,只有最合適的。具體選擇哪種數據庫遷移方案,最終還是要看具體的系統環境以及遷移實施隊伍的技術能力。

一、存儲復制
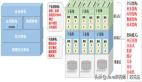
存儲復制是最近我比較喜歡的一種數據庫跨存儲遷移的方法,可以用于很多遷移需求。特別是一個環境中存在多種數據庫/多個數據庫的場景,用存儲復制的方式一下子可以搞定所有的數據庫,十分便捷。存儲復制的主要實施工作都由存儲廠商完成,對于DBA來說也是最為輕松的,如果出問題,都不需要DBA去甩鍋,肯定是存儲廠商的問題。DBA要做的就是打開數據庫,用rman validate校驗一下數據文件是否存在物理/邏輯壞塊就可以了。十年前一個金融客戶的核心數據庫數據庫從9i HA升級為10g RAC,存儲從IBM 8000系列遷移到HDS高端存儲,采用的就是這個方案。使用HDS自帶的異構存儲虛擬化能力,首先將數據從IBM 8000系列存儲復制到HDS上,最后切換的那一晚上停掉生產數據庫,作最后一次增量復制后,用10g RAC的環境掛在新的卷,然后UPGRADE數據庫,整個數據庫遷移升級工作一個多小時就完成了。
很多DBA會把卷復制和存儲復制看作一碼事,對于DBA來說,存儲和卷并無不同,反正看到的是一堆裸設備。實際上二者還是不同的,卷復制采用的是卷管理軟件的數據同步功能,比如VERITAS的LVM,卷管理軟件天生就是支持異構平臺的,因此使用卷復制技術同步數據有更廣泛的適用性,而存儲復制技術需要存儲本身的支持(不過現在大多數高端存儲都支持異構存儲的存儲虛擬化,因此大多數情況下都能支持,如果實在你的環境中的存儲不支持異構復制,也可以考慮租借一臺支持你所需要復制的存儲的虛擬化機頭來做實施,費用在幾千塊錢到幾萬塊錢不等,看你租借的設備和租借的時間)。
大概十年前吧,一個運營商從HP小機上遷移一個數據庫到IBM小機,存儲也從HP存儲更換為EMC存儲,當時他們原來的系統使用了VCS,因此使用VERITAS的卷復制做的數據遷移。在IBM端CONVERT數據庫的時候(因為HP-UX和AIX都是大端的,所以可以做DATABASE CONVERT,而不需要使用XTTS)遇到了ORACLE 10G的一個BUG, UNDO表空間CONVERT失敗,數據庫無法打開,當時也是驚出一身冷汗,最后通過強制OFFLINE相關UNDO SEGMENT,重新創建UNDO表空間切換等方式解決了這個問題,不過完成遷移的時候已經接近早上8點,超出了申請的停機窗口,差點影響了第二天營業廳開門。所以說,再簡單的遷移方案,都不能保證不出意外。
二、邏輯復制
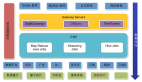
邏輯復制是一種停機窗口較為緊張時候常用的數據庫遷移的方案。兩千零幾年的時候幫助一個運營商把計費/賬務兩大核心系統從Oracle 8i遷移到Oracle 10g的時候,為了縮短停機窗口,使用ogg進行邏輯復制。那時候的OGG也是比較垃圾的,功能、性能都存在一定的問題,BUG也比較多。切換當晚發現有幾張表總是追不上,最后決定直接通過dblink CTAS重建的方式遷移了。最后還好,在規定的時間窗口內完成了數據庫的遷移和數據校驗工作。使用OGG做遷移,數據校驗的工作量十分大,如果是十分核心的系統,對數據一致性和完整性要求較高,一定要留足時間做數據校驗。
邏輯導出導入一直是被認為最為安全的遷移方式,不過天底下沒有絕對安全的遷移方案。大概6/7年前,一個銀行把核心系統從HDS存儲遷移到華為18K上的時候,想把數據庫也順便從10g升級到11g,因為核心應用也要做升級,因此申請了36小時的業務停機窗口,其中核心系統完全停止業務18小時,這18小時中,給了數據庫遷移8個小時的時間。通過綜合考慮,他們決定采用最為穩妥的數據庫邏輯導出導入的方式。
首先在老存儲上導出數據,然后把整個卷掛載到新的服務器上,再做導入。按理說夠安全了吧,沒想到主機工程師掛載這塊盤的時候沒注意給掛載成只讀的了。DBA也沒檢查就開始導入了,幾個小時后報無法寫入磁盤數據,impdp異常退出了。這時候8小時的時間窗口已經使用了5個多小時了,如果重新導入一次,時間上肯定是不夠的。當時我正好在現場,通過檢查發現是impdp輸出日志的時候無法寫盤導致了錯誤,而剛開始的時候寫入日志的時候是寫在緩沖里并沒有刷盤,所以沒有報錯,等刷盤的時候就報錯了。通過校驗數據表和索引發現所有的索引都已經完成創建了。因此報錯時可能已經完成了主要的數據導入過程。最后經過會商決定暫時不回退整個工作,繼續進行后續工作。
不過因為這個插曲,原本計劃的對所有表和索引做一次重新統計(通過SPA分析后發現11g對統計數據的依賴性更強,因此建議最后做一次表分析)就沒有進行了。核心系統啟動順利完成,主要功能測試也順利完成,大家揪著的心才放了下來。不過前臺很快傳來更壞的消息,應用開發商在測試性能的時候,認為主要核心交易的延時都慢了幾十毫秒,平均核心交易延時從升級前的80毫秒提高到120毫秒以上,因此拒絕新系統上線。大家折騰了這么長時間還要回退,這對IT部門的打擊十分嚴重的。因此CIO希望我們能夠盡快找到問題,解決問題。
通過分析存儲的性能,數據庫的總體性能沒有發現什么問題。時間已經接近8小時的窗口了,按道理現在必須做回退了。我當時和CIO說,能不能再給我20分鐘我再分析一下,如果找不到原因再回退。當時CIO說,我給你40分鐘,如果不行只能我去向行長請罪了。最后在差不多半小時后,我終于定位了引起一部分核心交易延時增加的主要原因是幾張表的統計數據過舊,更新了統計數據后,核心交易延時恢復到90毫秒左右,低于開發商要求的不高于120毫秒的要求。從這個案例上看,最簡單靠譜的遷移方案,也不是萬全的。
三、ASM磁盤組加盤/刪盤
ASM磁盤組上加入新存儲的磁盤,然后逐步刪除老存儲的磁盤,利用ASM的REBALANCE功能實現存儲遷移也是一種挺不錯的方案,只是REBALANCE時間比較長(如果數據量較大,業務負載較大),需要DBA隨時關注整個進程,如果系統負載較高,IO吞吐量較大,那么在此期間可能會引起一些IO方面的性能問題。嚴重時可能導致應用系統總體性能嚴重下降,而一旦這些問題發生,我們只能暫時降低REBALANCE的優先級,緩解問題,無法徹底解決問題。因此對于特別核心的系統使用這種方式還是要十分注意。我把這個方法教給一家銀行后,他們就喜歡上了這種遷移方式,并用這種方式遷移了大量的系統,總體上來說還是比較平穩的。不過在核心交易系統上,他們還是沒敢使用。
數據庫遷移的方法有很多,今天時間的關系我就不一一舉例了。不過無論采用何種方式,都需要實施者不要掉以輕心,對每個環節都做最精心的準備。不過有一定可以提醒大家的是,跳出DBA的思維方式,可能會找到更好的方法。?