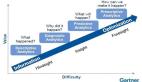
數據質量成熟度模型:分析數據準備的五個級別
生成可供分析的數據的一個關鍵要求是數據必須是“好”的。各組織對良好數據質量的定義存在差異,這些定義符合其在分析和數據科學方面的成熟度。
由于兩個原因,成熟度模型類比似乎適合這里。首先,模型中的關卡是相互依存的,在掌握較低的關卡之前不可能達到更高的關卡。其次,向更高層次移動不僅僅是工具或算法的問題,因為它還需要不同的流程和組織思維。

第1級:數據來源
了解數據來自哪里、如何收集、如何轉換、為什么以及由誰轉換,是任何可用數據集的最基本要求。例如,在臨床環境中——如果我們不知道哪個實驗室進行了測試,誰資助了這項研究,血壓是站立還是坐下,或者在我們得到試驗結果之前是否將某些患者從試驗結果中剔除——數據實際上是無用的。
擁有關于每個數據集的明確出處、沿襲、所有者和其他元數據——甚至在查看數據本身之前——是任何數據分析之前的基本要求。在醫療保健領域,披露利益沖突、資金來源、隱私和其他道德考慮也是關鍵。
俗話說——“如果你足夠折磨數據,它會告訴你任何事情”。
第2級:基本衛生
在這個級別,團隊關注的是基本數據元素的統一表示:
- 數字(格式為“3,500”或“3500”)
- 空值(將“null”、“N/A”、“na”、“?”、“-1”和“未指定”格式化為單個值)
- 標準單位和標準單位的轉換(格式為“30lbs”至“13.6”,單位為 kg)
- 地理空間點、圓、弧和多邊形
- 日期和時間、貨幣、姓名、地址、電子郵件、布爾值和其他常見類型
大多數這些價值觀都有國際標準,盡管通常有不止一個“標準”在起作用。對于數據消費者而言,正確的選擇始終是“工具本身可以理解的格式”——因此,如果該工具是 Tableau、R、pandas 或 Excel,答案可能會有所不同。
大多數提供數據質量指標、數據完整性或豐富性指標、自動數據規范化或主數據管理的工具都在這個級別上運行。
第 3 級:異常值、混亂和不太可能的組合
下一個級別超越單個數據元素,進入描述性統計數據和可能的錯誤。例如,一名患者服用 12,345 種不同類型的藥物很可能是數據輸入錯誤,或者至少是在計算對異常值敏感的描述性統計數據(如均值和標準差)時應排除的異常值。
有時問題不是個別異常值,而是一連串幾乎是例外的情況。例如,在一個網站每秒網絡流量的數據集中,10 分鐘內從歷史標準增加 100 倍的可能性要大得多,這很可能是機器人的結果,而不是真實用戶活動的結果。Flurries 經常出現在時間序列數據中,必須根據具體情況決定保留或刪除。
領域專家還應該深入挖掘以發現由于不太可能的組合而導致的錯誤。特別是在醫療保健領域,通常可以識別出臨床上不太可能的組合。例如,在一個案例中,一個 25 歲的女性體重 535 磅本身是合理的,但查看同一患者的其他測量和實驗室結果,很明顯這是一個打字錯誤53.5磅的女人。這種“臨床上不太可能的組合”通常是數據輸入錯誤,應該在下游數據分析之前消除。
第 3 級需要更深入的統計知識以及 DataOps 團隊更深入的領域專業知識。如示例所示,在此級別“固定”數據質量不再能夠完全自動化。

第 4 級:覆蓋缺口
下一個層次超越了將數據集的質量描述為一種通用度量——討論是否適合給定的分析項目。這尤其涉及識別所提供數據中的差距,并找到補充它們的方法。
例如,考慮一個跟蹤英國兒童疫苗接種率的項目。收集的數據可能存在空間覆蓋缺口(即沒有在威爾士收集數據)、時間覆蓋缺口(有 15 年的數據,由于當年的預算限制,2010 年除外)或人口覆蓋缺口(即不在學校沒有被調查)。
這種差距的重要性在很大程度上取決于項目。例如,如果目標是識別有風險的孩子,那么找到不在學校的孩子可能很關鍵;然而,如果目標是比較男孩和女孩,這種差距可能不會破壞整個分析。做出正確的決定和更正需要您的分析團隊和 DataOps 團隊之間的協作。
第 5 級:偏見
在更高的層次上,運行完全集成的項目團隊,團隊結合了數據科學、DataOps 和軟件工程師。人們每天都在同一個項目上工作,這樣可以發現和解決已經“通過”所有先前級別的質量門的數據中細微但關鍵的偏差。
這最常適用于機器學習和數據挖掘項目。例如,假設我們正在尋找一種算法,該算法可以根據患者的醫院臨床記錄自動分配 ICD-10 診斷和程序代碼。為了訓練它,我們只能從鎮上的兩家醫院之一獲得數據。兩家醫院都設有內科病房,但其中一家專攻心臟病學和腫瘤學(并且處理了大多數病例),而另一家專攻免疫學、內分泌學和老年醫學。
請注意,無論我們選擇哪家醫院——我們的訓練數據中診斷和程序代碼的分布都將與我們將在“現實世界”中觀察到的情況有所偏差,這將扭曲機器學習算法,因為先驗分布訓練數據中的數據將不同于在線觀察到的數據。

數據集的選擇也會導致其他不太明顯的偏差。每家醫院本質上都會經歷不同的年齡、性別和合并癥分布——因為在醫療保健領域,所有這些都是相關的。這意味著,由于這些關系和相關性,有監督和無監督學習算法都會以微妙但重要的方式出現偏差。
這在實踐中具有重要意義,因為我們越來越依賴機器來做出影響人們健康和福祉的日常決策。您對訓練數據的選擇隱含地忽略了其中沒有代表的人,并且可能會根據他們過去的行為過度懲罰或獎勵那些被代表的人。這基本上是一個數據質量問題。
了解此類問題的存在并有效解決這些問題需要數據科學家和 DataOps 專家之間持續進行深入合作,這是生成機器學習模型或預測分析的必要條件,這些模型或預測分析不受未公開偏見的影響并經受住現實世界的考驗采用。