對云原生環境下數據庫服務治理的思考

從服務治理到數據庫服務治理
微服務治理
對于從服務治理到數據庫服務治理,我們還是要先從微服務治理來切入。從單體到微服務,伴隨業務越來越復雜、越來越多元,以及基礎設施規模越來越大,服務之間的調用關系變得非常復雜。對于微服務的治理行為,還停留在流量控制、可觀測性、安全訪問、配置管理和高可用等幾個方面。要想讓微服務架構更快地上線和部署,一定要有一個自動化的框架。對于運維,我們也希望能夠盡可能的標準化。
這時候就出現了像 Kubernetes 這樣的容器編排框架。Kubernetes 源自于 Google 內部的 Borg,它帶了很多 Google 的大廠屬性。大廠不是說技術多么厲害,而是說它的規模非常大。只有在一個特別大的規模里,運維的復雜度才會體現出來,也就更加依賴于平臺或者工具去提高自動化能力。
這種自動化的能力,我們把它叫做基礎設施即代碼,只要是 SRE 的同學去寫一個這樣的配置文件,然后把文件提交給 Kubernetes ,Kubernetes 就會根據里面描述的行為去做相應指令,只不過這個指令是聲明式的 API,在這個過程中就完成了對應用的自動化上線。
講到 Kubernetes,如果成千上萬個節點,上面可能有十萬個pod,我們怎么去做它的服務治理?如果還沿用之前的服務發現框架,在兼容 Kubernetes 時多少會有一些水土不服。有沒有一種原生的方式去做 Kubernetes 之上的服務治理呢?這就是 Service Mesh。
Service Mesh
Service Mesh 是在2016年由 Linkerd 項目率先提出的。Service Mesh 把對服務治理的行為或者能力下沉到基礎設施。Service Mesh 可以認為它是一個對于服務治理行為的編排框架,我們通過一些聲明式的配置,讓 Service Mesh 去交付給基礎框架、基礎設施,去代理我們執行相關任務。
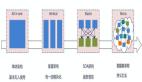
服務網格有個特別典型的圖,就是下邊這個圖。我們可以假設藍色的就是我們的業務應用,而黃色的部分就是我們的服務網格代理。服務網格就是通過這樣一個透明代理,去把應用的所有流量接管,再去對它治理。它通過這種接管的方式,實現各種服務治理的能力,比如服務發現等等。

Istio 簡介
說到 Service Mesh,就必須提到 Istio 這個項目。2016年 Linkerd 對于 Service Mesh 的理解可能還不是特別成熟,我們把那個時候叫做第一代 Service Mesh。到 Istio 出現,才真正成為了現在我們所看到的 Service Mesh 架構, Istio 我們把它叫做第二代 Service Mesh。
Istio 的主要架構就是下邊的這張圖,它底下有一個 Control panel。Control panel 叫做控制面,這個控制面里面有 Istiod,在早期1.0的時候,Istiod 是由多個獨立組件構成的,比如說 Pilot、Galley、Citadel,它們分別去負責一些證書,比如可觀測性的聚合。它原來還有個 Mixer,還有各個 Pilot 相關的配置等等。

微服務治理和數據庫服務治理的異同
或許有人要問:既然 Istio 可以代理應用的流量,那么為什么我們還要去談一個數據庫的服務治理?我們完全可以讓 Istio 劫持我們數據庫的協議或者讓它去代理所有的數據庫流量,來實現治理的效果。
如果我們把數據庫看成微服務中的一個特殊微服務,它可能是服務鏈路的最后一環,我們確實是可以通過 Service Mesh 對數據庫進行訪問治理,包括服務發現這些能力。但是數據庫也有一些特殊的治理屬性或者要求,比如說數據庫的協議,它的 MySQL 協議或者說 PG 的協議或者 Redis 協議有特殊性。比如 MySQL 協議我們在建連的時候,是服務端會先給我們發一個包,還有就是資源管理,可能對于微服務之間業務的應用之間,我們不用太關心它在運行時所消耗的資源,它應該是整個服務的一個性能指標。
但對于數據庫來說,可能就會有些區別。它體現在可觀測性上的時候,比如數據庫的指標,它可能會涉及到慢 SQL 或者 SQL 延遲。
對于流量治理這部分,數據庫也有它的特殊性,不管是 Redis、MongoDB 還是 MySQL,我們去做分片的時候,很難單純只依靠于流量本身去做分發。如果我們隨意地去轉發相應請求,可能就會得到一個錯誤答案。
另外,對于像分庫分表這樣的場景來說,所謂的負載均衡是基于對數據屬性的判斷,不能粗暴的只是讓它隨機發到后面的不同數據源。
最后還有訪問控制,一般來說對于業務應用來說,我們是一個微服務級別的訪問控制,可能關聯到一個全局的認證或者身份授權,很多情況下我們需要一個表級別甚至是列級別的訪問控制,只有通過特殊的治理手段,才能夠實現這樣一些特殊的治理效果。
如何設計一個Mesh模型
從 Service Mesh 中學到的
我們還回到剛才所說的 Service Mesh,我們從 Service Mesh 中能學到什么呢?
第一,Service Mesh 是一個控制面和數據面分離的部署結構。
第二,如果我們把控制面和數據面的協議做了標準化,我們可以讓數據面有更多的選擇。
第三,我們可以通過 Kubernetes 機制去實現基礎設施即代碼的配置能力。
第四,可以通過插件去支持各種不同的協議擴展。
這個時候我們就會去想,數據庫的 Database Mesh 和我們 Service Mesh 之間是一個包含關系嗎?還是兩個完全不同的場景呢?
Database Mesh 概念的提出
在2018年的時候,ShardingSphere 的創始人張亮在他的《未來架構》這本書里面,其實設想過,如果將 Service Mesh 治理的思路應用到數據庫治理上,會是一個什么樣的效果?
ShardingSphere 這個項目主要是去做了數據庫流量的治理,比如說做分庫分表、做數據的加密、做數據的Scaling 等等。是不是可以存在一個 ShardingSphere 的 Sidecar,跟業務的應用部署在一起,就像下邊這張圖一樣,正常的業務請求通過 Service Mesh 去做微服務、業務之間的服務發現和相關的調用。對于數據庫的流量,通過 Sharding Sidecar 把它代理到數據庫,而整個 Sharding Sidecar 也是依賴于一個控制面去做相關的注冊和發現。

Sharding Sidecar 和 ShardingSphere 已有的 Proxy 和 JDBC 能力應該是一樣的,通過這種方式可以完美地屏蔽掉 JDBC 和 Proxy 的缺點。Sharding Sidecar 以 Sidecar 的方式部署在業務應用的旁邊,業務應用如果是分布式的或多副本的,那么它就會有多個副本。業務的應用和它之間的通信也可以實現這種語言上的解耦,而不用受限于具體的語言棧。這種架構是不是就是一個彈性伸縮+零侵入+去中心的云上基礎設施呢?
這是2018年的時候,關于 Database Mesh 的一個想法。
Database Mesh 的現狀
從2018年到現在這短短四年的時間里,Database Mesh 這個概念其實已經在很多公司得到了充分的探索和實踐。概括起來有三種典型的方案。
第一種,是 ShardingSphere Sidecar 的形式。把對數據庫治理的特性,以 Sidecar 的形式提供給業務的 Pod。
第二種,可能在一些大廠里會見得比較多,就是統一的 Mesh 管控。
第三種,叫做分布式數據庫。

這三種方式有一個共同點,就是它都關注于數據庫服務治理中流量治理的那一部分。我們如果把這個階段稱之為1.0階段,那么假設我們要去對它做一個升級,要做2.0,應該又有什么樣的特性呢?
Database Mesh 1.0 vs 2.0
我們在經過了充分思考之后,覺得應該有更多的擴展性和面向更好的用戶體驗,所以我們提出了 Database Mesh 2.0的概念。我們現在專門做了一個網站,它的口號就是“通過可編程,實現高性能的擴展,來應對云上數據庫的治理挑戰”。
我們希望通過這種可配置、可插拔或者可編程的方式,能夠實現一個覆蓋數據庫流量、運行時資源和穩定性保障等方面的治理框架。不管是什么類型的數據庫,我們希望能夠有一個標準界面,然后去把它治理起來。這就是 Database Mesh 2.0所希望的能力。
對于 Database Mesh 2.0來說,其實特別要強調的一點就是,我們在做設計的時候,一直在想 Mesh 到底代表的是什么含義。其實最開始的時候,我們就會覺得 Sidecar 就是 Mesh,我們通過 Sidecar 和別的東西交互了,就構成一個網格,這個網格就是 Mesh。但是后來我們發現其實不是這個樣子,Mesh 的核心不是 Sidecar,Mesh 只是它的一種表現形式。
我們接下來就看 Database Mesh 2.0的全景圖。這個全景圖左半部分上面其實是按照用戶來分的,上面是 Developers,就是開發人員對于 Database Mesh 的感受是什么。而右側對于 SRE 或者 DBA 的同學來說,他們想看到的東西就比較多了,不管是訪問控制、審計、風控、可觀測性、事件。而右側對于 SRE 或者 DBA 的同學來說,他們想看到的東西就比較多了,不管是訪問控制、審計、風控、可觀測性、事件。

總結一下:
第一,Database Mesh 2.0里邊,我們認為數據庫是一等公民,所有的這些抽象都是圍繞數據庫進行的,也就是剛才我們所說的 VirtualDatabase。
第二,我們希望它是能夠面向工程師的體驗,不管是開發人員還是 SRE 還是 DBA,用關心數據庫實際的位置。
第三,云原生,它應該是一個天生面向云的環境,用戶不用擔心這個東西是廠商鎖定的。
如何利用 Kubernetes 實現數據庫 Mesh
最后這部分,我們就介紹一下我們如何利用 Kubernetes 去實現這樣一個模型。
Kubernetes 的擴展模式
Kubernetes 被稱為是平臺的平臺。我們在 Kubernetes 之上,之前也涌現出來好多創業公司和一些 PaaS 服務商,在它上面去構建各種各樣的能力。
Kubernetes 的擴展能力是它生命力的關鍵,它的第一種擴展模式叫做 Sidecar;第二個擴展模式是 AdmissionWebhook;第三個擴展模式,也是它特別厲害的一個能力,就是用戶自定義資源定義。
Pisanix 設計與實現
介紹完 Kubernetes 之后,我們就來看一下 ??Pisanix?? 這個項目。Pisanix 是 SphereEx 團隊對 Database Mesh 提供的一個解決方案。Pisanix 是由 Go 和 Rust 兩種語言編寫的,我們去適配了 Kubernetes 環境,目前支持 MySQL 的協議。
它有三個比較主要的組件:
- Pisa-Controller:Pisanix 這個項目的核心組件,Pisa-Controller 承擔的就是控制面,它是 Golang 實現的,是一個必選的組件。
- Pisa-Proxy:Pisa-Proxy 是負責代理流量的數據面,Pisa-Proxy 就是以 Sidecar 的形式部署在 Pod 里面,它是 Rust 實現的,它也是一個必選的組件。
- Pisa-Daemon(即將發布):它是負責資源優化的數據面,是一個 DaemonSet,是每一個 Kubernetes 集群的節點都會有一份 Daemon,它是一個可選的組件。
三個組件共同達到的效果:
第一,實現了SQL感知的流量治理。
第二,面向運行時的資源可編程。
第三,數據庫可靠性工程,也叫DRE。
我們會重點講一下 Pisa-Proxy。Pisa-Proxy 是我們最主要的一個核心組件,所有的能力其實都依賴于它,我們選擇了 Rust 而去實現它的一個主要原因,是因為 Rust 的生命力是非常頑強的。
Pisa-Proxy 可以看作是面向數據庫流量的負載均衡器,主要工作流程如下:
目前 Pisa-Proxy 支持 MySQL 協議,將自己偽裝為數據庫服務端,應用連接配置只需修改訪問地址即可建連:
- Pisa-Proxy 通過讀取應用發來的握手請求和數據包,得到應用希望執行的 SQL。
- 對該 SQL 進行詞法和語法解析后得到對應 AST。
- 基于 AST 實現高級訪問控制和 SQL 防火墻能力。
- 訪問控制和防火墻通過后 SQL 提交執行。
- SQL 執行階段的指標將采集為 Prometheus Metrics。
- 根據負載均衡策略獲取執行該語句的后端數據庫連接。
- 如果連接池為空將根據配置建立和后端數據庫的連接。
- SQL 將從該連接發往后端數據庫,并讀取相應返回結果。
- SQL 執行結果進行組裝后返回給業務應用。

最后講到Pisa-Daemon。Pisa-Daemon 離不開 eBPF 技術。eBPF 現在比較火,eBPF 這個技術本身就像容器一樣,也不是特別新鮮的東西。
eBPF 是 Extended BPF 的簡稱,可以在 Linux 內核中構建沙箱并運行各種程序。eBPF 是一種安全和高效的內核擴展機制,常被用于:
- 可觀測性:eBPF 在內核態可以進行各種可觀測指標的采集,生成多樣化的圖表。
- 系統安全:通過 eBPF 可以觀測到所有的系統調用,配合對網絡包或套接字的管理以及進程上下文追蹤能力,實現更細粒度的安全控制。
- 網絡:eBPF 的編程擴展能力,天然適合對網絡流量包的處理過程,無需離開內核的網絡處理上下文。
- 追蹤和調優:通過對用戶態進程以及系統調用的探測,實現零侵入的關聯追蹤和性能分析體驗。
對于 Pisa-Daemon 來說,號稱是做資源可編程,Pisa-Daemon 利用內核機制去提供資源方面的管理能力,這個資源就是運行時資源。通過 Pisa-Daemon 和 Pisa-Proxy 去做配合,我們可以標識不同優先級業務出來的數據庫流量。
未來我們希望做成一種擴展機制,以可插拔或者可編程方式,支持更多種類型的運行時資源管理。
如何在 Kubernetes 中使用 Pisanix
最后我們可以看一下在 Kubernetes 里面如何去使用 Pisanix 這個項目。
Pisanix 既然是對于 Database Mesh 的一個實現,那么我們也沿用它的規范,首先我們使用了三種 CRD,這三種叫做 VirtualDatabase、TrafficStrategy 和 DatabaseEndpoint。
VirtualDatabase 就是我們前面介紹 Database Mesh 的時候,它的聚合根,它的所有對于 Database Mesh 治理的能力,都是體現在 VirtualDatabase 上面。
在 VirtualDatabase 里面有一個字段叫做 TrafficStrategy,標識對于這個數據庫的訪問來說,我們希望它以什么樣的策略去治理它。
那它 Random 到誰呢?就是在 TrafficStrategy 里面它有 Selector。Selector 通過 Label 去選擇后端的 DatabaseEndpoint。
這三個 CRD 就可以覆蓋這個業務應用對于后端數據源和對于 MySQL 代理的相關配置信息。接下來就是 Pisa-Controller 拿到 CRD,然后根據里面的配置內容轉化成 Pisa-Proxy 的配置,然后推給相應的 Sidecar。Pisa-Proxy 拿到這個配置,然后根據里面的內容將向后端實際的數據庫去建連,然后同時前端去監聽端口,接收請求。最后對應用來說,它只要訪問里面配置的這個端口就可以實現了。
其實 Pisa-Proxy 我們也在思考它其實也是可以被單獨使用的,有的 Kubernetes 不是適用于每一個公司或者每一個業務,如果說也需要這種對于數據庫的治理,尤其對于流量這種統一接入的治理,其實是可以把 Pisa-Proxy 單獨拿出來去部署。這個時候的用法,就跟我們用一個 Nginx 組成一個集群是一樣的,不管后面你是什么樣的數據庫,比如你是 RDS 或者 TiDB、ShardingSphere,都可以由 Pisa-Proxy 做成數據庫的統一接入層,來對它做代理,實現這種比如無感的高可用切換,實現面向 SQL 的可觀測性等等。