Linux 網(wǎng)絡(luò)性能的 15 個優(yōu)化建議
建議1:盡量減少不必要的網(wǎng)絡(luò) IO

我要給出的第一個建議就是不必要用網(wǎng)絡(luò) IO 的盡量不用。
是的,網(wǎng)絡(luò)在現(xiàn)代的互聯(lián)網(wǎng)世界里承載了很重要的角色。用戶通過網(wǎng)絡(luò)請求線上服務(wù)、服務(wù)器通過網(wǎng)絡(luò)讀取數(shù)據(jù)庫中數(shù)據(jù),通過網(wǎng)絡(luò)構(gòu)建能力無比強大分布式系統(tǒng)。網(wǎng)絡(luò)很好,能降低模塊的開發(fā)難度,也能用它搭建出更強大的系統(tǒng)。但是這不是你濫用它的理由!
原因是即使是本機網(wǎng)絡(luò) IO 開銷仍然是很大的。先說發(fā)送一個網(wǎng)絡(luò)包,首先得從用戶態(tài)切換到內(nèi)核態(tài),花費一次系統(tǒng)調(diào)用的開銷。進入到內(nèi)核以后,又得經(jīng)過冗長的協(xié)議棧,這會花費不少的 CPU 周期,最后進入環(huán)回設(shè)備的“驅(qū)動程序”。接收端呢,軟中斷花費不少的 CPU 周期又得經(jīng)過接收協(xié)議棧的處理,最后喚醒或者通知用戶進程來處理。當(dāng)服務(wù)端處理完以后,還得把結(jié)果再發(fā)過來。又得來這么一遍,最后你的進程才能收到結(jié)果。你說麻煩不麻煩。另外還有個問題就是多個進程協(xié)作來完成一項工作就必然會引入更多的進程上下文切換開銷,這些開銷從開發(fā)視角來看,做的其實都是無用功。
上面我們還分析的只是本機網(wǎng)絡(luò) IO,如果是跨機器的還得會有雙方網(wǎng)卡的 DMA 拷貝過程,以及兩端之間的網(wǎng)絡(luò) RTT 耗時延遲。所以,網(wǎng)絡(luò)雖好,但也不能隨意濫用!
建議2:盡量合并網(wǎng)絡(luò)請求
在可能的情況下,盡可能地把多次的網(wǎng)絡(luò)請求合并到一次,這樣既節(jié)約了雙端的 CPU 開銷,也能降低多次 RTT 導(dǎo)致的耗時。
我們舉個實踐中的例子可能更好理解。假如有一個 redis,里面存了每一個 App 的信息(應(yīng)用名、包名、版本、截圖等等)。你現(xiàn)在需要根據(jù)用戶安裝應(yīng)用列表來查詢數(shù)據(jù)庫中有哪些應(yīng)用比用戶的版本更新,如果有則提醒用戶更新。
那么最好不要寫出如下的代碼:
<?php
for(安裝列表 as 包名){
redis->get(包名)
...
}
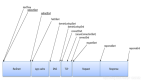
上面這段代碼功能上實現(xiàn)上沒問題,問題在于性能。據(jù)我們統(tǒng)計現(xiàn)代用戶平均安裝 App 的數(shù)量在 60 個左右。那這段代碼在運行的時候,每當(dāng)用戶來請求一次,你的服務(wù)器就需要和 redis 進行 60 次網(wǎng)絡(luò)請求。總耗時最少是 60 個 RTT 起。更好的方法是應(yīng)該使用 redis 中提供的批量獲取命令,如 hmget、pipeline等,經(jīng)過一次網(wǎng)絡(luò) IO 就獲取到所有想要的數(shù)據(jù),如圖。
絡(luò)性能的 15 個優(yōu)化建議")
建議3:調(diào)用者與被調(diào)用機器盡可能部署的近一些
在前面的章節(jié)中我們看到在握手一切正常的情況下, TCP 握手的時間基本取決于兩臺機器之間的 RTT 耗時。雖然我們沒辦法徹底去掉這個耗時,但是我們卻有辦法把 RTT 降低,那就是把客戶端和服務(wù)器放得足夠的近一些。盡量把每個機房內(nèi)部的數(shù)據(jù)請求都在本地機房解決,減少跨地網(wǎng)絡(luò)傳輸。
舉例,假如你的服務(wù)是部署在北京機房的,你調(diào)用的 mysql、redis最好都位于北京機房內(nèi)部。盡量不要跨過千里萬里跑到廣東機房去請求數(shù)據(jù),即使你有專線,耗時也會大大增加!在機房內(nèi)部的服務(wù)器之間的 RTT 延遲大概只有零點幾毫秒,同地區(qū)的不同機房之間大約是 1 ms 多一些。但如果從北京跨到廣東的話,延遲將是 30 - 40 ms 左右,幾十倍的上漲!
建議4:內(nèi)網(wǎng)調(diào)用不要用外網(wǎng)域名
假如說你所在負(fù)責(zé)的服務(wù)需要調(diào)用兄弟部門的一個搜索接口,假設(shè)接口是:"http://www.sogou.com/wq?key=開發(fā)內(nèi)功修煉"。
那既然是兄弟部門,那很可能這個接口和你的服務(wù)是部署在一個機房的。即使沒有部署在一個機房,一般也是有專線可達的。所以不要直接請求 www.sogou.com, 而是應(yīng)該使用該服務(wù)在公司對應(yīng)的內(nèi)網(wǎng)域名。在我們公司內(nèi)部,每一個外網(wǎng)服務(wù)都會配置一個對應(yīng)的內(nèi)網(wǎng)域名,我相信你們公司也有。
為什么要這么做,原因有以下幾點
1)外網(wǎng)接口慢。本來內(nèi)網(wǎng)可能過個交換機就能達到兄弟部門的機器,非得上外網(wǎng)兜一圈再回來,時間上肯定會慢。
2)帶寬成本高。在互聯(lián)網(wǎng)服務(wù)里,除了機器以外,另外一塊很大的成本就是 IDC 機房的出入口帶寬成本。兩臺機器在內(nèi)網(wǎng)不管如何通信都不涉及到帶寬的計算。但是一旦你去外網(wǎng)兜了一圈回來,行了,一進一出全部要繳帶寬費,你說虧不虧!!
3)NAT 單點瓶頸。一般的服務(wù)器都沒有外網(wǎng) IP,所以要想請求外網(wǎng)的資源,必須要經(jīng)過 NAT 服務(wù)器。但是一個公司的機房里幾千臺服務(wù)器中,承擔(dān) NAT 角色的可能就那么幾臺。它很容易成為瓶頸。我們的業(yè)務(wù)就遇到過好幾次 NAT 故障導(dǎo)致外網(wǎng)請求失敗的情形。NAT 機器掛了,你的服務(wù)可能也就掛了,故障率大大增加。
建議5:調(diào)整網(wǎng)卡 RingBuffer 大小
在 Linux 的整個網(wǎng)絡(luò)棧中,RingBuffer 起到一個任務(wù)的收發(fā)中轉(zhuǎn)站的角色。對于接收過程來講,網(wǎng)卡負(fù)責(zé)往 RingBuffer 中寫入收到的數(shù)據(jù)幀,ksoftirqd 內(nèi)核線程負(fù)責(zé)從中取走處理。只要 ksoftirqd 線程工作的足夠快,RingBuffer 這個中轉(zhuǎn)站就不會出現(xiàn)問題。
但是我們設(shè)想一下,假如某一時刻,瞬間來了特別多的包,而 ksoftirqd 處理不過來了,會發(fā)生什么?這時 RingBuffer 可能瞬間就被填滿了,后面再來的包網(wǎng)卡直接就會丟棄,不做任何處理!
絡(luò)性能的 15 個優(yōu)化建議")
通過 ethtool 就可以加大 RingBuffer 這個“中轉(zhuǎn)倉庫”的大小。。
# ethtool -G eth1 rx 4096 tx 4096
絡(luò)性能的 15 個優(yōu)化建議")
這樣網(wǎng)卡會被分配更大一點的”中轉(zhuǎn)站“,可以解決偶發(fā)的瞬時的丟包。不過這種方法有個小副作用,那就是排隊的包過多會增加處理網(wǎng)絡(luò)包的延時。所以應(yīng)該讓內(nèi)核處理網(wǎng)絡(luò)包的速度更快一些更好,而不是讓網(wǎng)絡(luò)包傻傻地在 RingBuffer 中排隊。我們后面會再介紹到 RSS ,它可以讓更多的核來參與網(wǎng)絡(luò)包接收。
建議6:減少內(nèi)存拷貝
假如你要發(fā)送一個文件給另外一臺機器上,那么比較基礎(chǔ)的做法是先調(diào)用 read 把文件讀出來,再調(diào)用 send 把數(shù)據(jù)把數(shù)據(jù)發(fā)出去。這樣數(shù)據(jù)需要頻繁地在內(nèi)核態(tài)內(nèi)存和用戶態(tài)內(nèi)存之間拷貝,如圖 9.6。
絡(luò)性能的 15 個優(yōu)化建議")
目前減少內(nèi)存拷貝主要有兩種方法,分別是使用 mmap 和 sendfile 兩個系統(tǒng)調(diào)用。使用 mmap 系統(tǒng)調(diào)用的話,映射進來的這段地址空間的內(nèi)存在用戶態(tài)和內(nèi)核態(tài)都是可以使用的。如果你發(fā)送數(shù)據(jù)是發(fā)的是 mmap 映射進來的數(shù)據(jù),則內(nèi)核直接就可以從地址空間中讀取,這樣就節(jié)約了一次從內(nèi)核態(tài)到用戶態(tài)的拷貝過程。
絡(luò)性能的 15 個優(yōu)化建議")
不過在 mmap 發(fā)送文件的方式里,系統(tǒng)調(diào)用的開銷并沒有減少,還是發(fā)生兩次內(nèi)核態(tài)和用戶態(tài)的上下文切換。如果你只是想把一個文件發(fā)送出去,而不關(guān)心它的內(nèi)容,則可以調(diào)用另外一個做的更極致的系統(tǒng)調(diào)用 - sendfile。在這個系統(tǒng)調(diào)用里,徹底把讀文件和發(fā)送文件給合并起來了,系統(tǒng)調(diào)用的開銷又省了一次。再配合絕大多數(shù)網(wǎng)卡都支持的"分散-收集"(Scatter-gather)DMA 功能。可以直接從 PageCache 緩存區(qū)中 DMA 拷貝到網(wǎng)卡中。這樣絕大部分的 CPU 拷貝操作就都省去了。
絡(luò)性能的 15 個優(yōu)化建議")
建議7:使用 eBPF 繞開協(xié)議棧的本機 IO
如果你的業(yè)務(wù)中涉及到大量的本機網(wǎng)絡(luò) IO 可以考慮這個優(yōu)化方案。本機網(wǎng)絡(luò) IO 和跨機 IO 比較起來,確實是節(jié)約了驅(qū)動上的一些開銷。發(fā)送數(shù)據(jù)不需要進 RingBuffer 的驅(qū)動隊列,直接把 skb 傳給接收協(xié)議棧(經(jīng)過軟中斷)。但是在內(nèi)核其它組件上,可是一點都沒少,系統(tǒng)調(diào)用、協(xié)議棧(傳輸層、網(wǎng)絡(luò)層等)、設(shè)備子系統(tǒng)整個走 了一個遍。連“驅(qū)動”程序都走了(雖然對于回環(huán)設(shè)備來說這個驅(qū)動只是一個純軟件的虛擬出來的東東)。
如果想用本機網(wǎng)絡(luò) IO,但是又不想頻繁地在協(xié)議棧中繞來繞去。那么你可以試試 eBPF。使用 eBPF 的 sockmap 和 sk redirect 可以繞過 TCP/IP 協(xié)議棧,而被直接發(fā)送給接收端的 socket,業(yè)界已經(jīng)有公司在這么做了。
絡(luò)性能的 15 個優(yōu)化建議")
建議8:盡量少用 recvfrom 等進程阻塞的方式
在使用了 recvfrom 阻塞方式來接收 socket 上數(shù)據(jù)的時候。每次一個進程專?為了等一個 socket 上的數(shù)據(jù)就得被從 CPU 上拿下來。然后再換上另一個 進程。等到數(shù)據(jù) ready 了,睡眠的進程又會被喚醒。總共兩次進程上下文切換開銷。如果我們服務(wù)器上需要有大量的用戶請求需要處理,那就需要有很多的進程存在,而且不停地切換來切換去。這樣的缺點有如下這么幾個:
- 因為每個進程只能同時等待一條連接,所以需要大量的進程。
- 進程之間互相切換的時候需要消耗很多 CPU 周期,一次切換大約是 3 - 5 us 左右。
- 頻繁的切換導(dǎo)致 L1、L2、L3 等高速緩存的效果大打折扣
大家可能以為這種網(wǎng)絡(luò) IO 模型很少見了。但其實在很多傳統(tǒng)的客戶端 SDK 中,比如 mysql、redis 和 kafka 仍然是沿用了這種方式。
建議9:使用成熟的網(wǎng)絡(luò)庫
使用 epoll 可以高效地管理海量的 socket。在服務(wù)器端。我們有各種成熟的網(wǎng)絡(luò)庫進行使用。這些網(wǎng)絡(luò)庫都對 epoll 使用了不同程度的封裝。
首先第一個要給大家參考的是 Redis。老版本的 Redis 里單進程高效地使用 epoll 就能支持每秒數(shù)萬 QPS 的高性能。如果你的服務(wù)是單進程的,可以參考 Redis 在網(wǎng)絡(luò) IO 這塊的源碼。
如果是多線程的,線程之間的分工有很多種模式。那么哪個線程負(fù)責(zé)等待讀 IO 事件,哪個線程負(fù)責(zé)處理用戶請求,哪個線程又負(fù)責(zé)給用戶寫返回。根據(jù)分工的不同,又衍生出單 Reactor、多 Reactor、以及 Proactor 等多種模式。大家也不必頭疼,只要理解了這些原理之后選擇一個性能不錯的網(wǎng)絡(luò)庫就可以了。比如 PHP 中的 Swoole、Golang 的 net 包、Java 中的 netty 、C++ 中的 Sogou Workflow 都封裝的非常的不錯。
建議10:使用 Kernel-ByPass 新技術(shù)
如果你的服務(wù)對網(wǎng)絡(luò)要求確實特別特特別的高,而且各種優(yōu)化措施也都用過了,那么現(xiàn)在還有終極優(yōu)化大招 -- Kernel-ByPass 技術(shù)。
內(nèi)核在接收網(wǎng)絡(luò)包的時候要經(jīng)過很?的收發(fā)路徑。在這期間牽涉到很多內(nèi)核組件之間的協(xié)同、協(xié)議棧的處理、以及內(nèi)核態(tài)和用戶態(tài)的拷貝和切換。Kernel-ByPass 這類的技術(shù)方案就是繞開內(nèi)核協(xié)議棧,自己在用戶態(tài)來實現(xiàn)網(wǎng)絡(luò)包的收發(fā)。這樣不但避開了繁雜的內(nèi)核協(xié)議棧處理,也減少了頻繁了內(nèi)核態(tài)用戶態(tài)之間的拷貝和切換,性能將發(fā)揮到極致!
目前我所知道的方案有 SOLARFLARE 的軟硬件方案、DPDK 等等。如果大家感興趣,可以多去了解一下!
絡(luò)性能的 15 個優(yōu)化建議")
建議11:配置充足的端口范圍
客戶端在調(diào)用 connect 系統(tǒng)調(diào)用發(fā)起連接的時候,需要先選擇一個可用的端口。內(nèi)核在選用端口的時候,是采用從可用端口范圍中某一個隨機位置開始遍歷的方式。如果端口不充足的話,內(nèi)核可能需要循環(huán)撞很多次才能選上一個可用的。這也會導(dǎo)致花費更多的 CPU 周期在內(nèi)部的哈希表查找以及可能的自旋鎖等待上。因此不要等到端口用盡報錯了才開始加大端口范圍,而且應(yīng)該一開始的時候就保持一個比較充足的值。
# vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 5000 65000
# sysctl -p //使配置生效
如果端口加大了仍然不夠用,那么可以考慮開啟端口 reuse 和 recycle。這樣端口在連接斷開的時候就不需要等待 2MSL 的時間了,可以快速回收。開啟這個參數(shù)之前需要保證 tcp_timestamps 是開啟的。
# vi /etc/sysctl.conf
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tw_recycle = 1
# sysctl -p
建議12:小心連接隊列溢出
服務(wù)器端使用了兩個連接隊列來響應(yīng)來自客戶端的握手請求。這兩個隊列的長度是在服務(wù)器 listen 的時候就確定好了的。如果發(fā)生溢出,很可能會丟包。所以如果你的業(yè)務(wù)使用的是短連接且流量比較大,那么一定得學(xué)會觀察這兩個隊列是否存在溢出的情況。因為一旦出現(xiàn)因為連接隊列導(dǎo)致的握手問題,那么 TCP 連接耗時都是秒級以上了。
對于半連接隊列, 有個簡單的辦法。那就是只要保證 tcp_syncookies 這個內(nèi)核參數(shù)是 1 就能保證不會有因為半連接隊列滿而發(fā)生的丟包。
對于全連接隊列來說,可以通過 netstat -s 來觀察。netstat -s 可查看到當(dāng)前系統(tǒng)全連接隊列滿導(dǎo)致的丟包統(tǒng)計。但該數(shù)字記錄的是總丟包數(shù),所以你需要再借助 watch 命令動態(tài)監(jiān)控。
# watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed //全連接隊列滿導(dǎo)致的丟包
如果輸出的數(shù)字在你監(jiān)控的過程中變了,那說明當(dāng)前服務(wù)器有因為全連接隊列滿而產(chǎn)生的丟包。你就需要加大你的全連接隊列的?度了。全連接隊列是應(yīng)用程序調(diào)用 listen時傳入的 backlog 以及內(nèi)核參數(shù) net.core.somaxconn 二者之中較小的那個。如果需要加大,可能兩個參數(shù)都需要改。
如果你手頭并沒有服務(wù)器的權(quán)限,只是發(fā)現(xiàn)自己的客戶端機連接某個 server 出現(xiàn)耗時長,想定位一下是否是因為握手隊列的問題。那也有間接的辦法,可以 tcpdump 抓包查看是否有 SYN 的 TCP Retransmission。如果有偶發(fā)的 TCP Retransmission, 那就說明對應(yīng)的服務(wù)端連接隊列可能有問題了。
建議13:減少握手重試
在 6.5 節(jié)我們看到如果握手發(fā)生異常,客戶端或者服務(wù)端就會啟動超時重傳機制。這個超時重試的時間間隔是翻倍地增長的,1 秒、3 秒、7 秒、15 秒、31 秒、63 秒 ......。對于我們提供給用戶直接訪問的接口來說,重試第一次耗時 1 秒多已經(jīng)是嚴(yán)重影響用戶體驗了。如果重試到第三次以后,很有可能某一個環(huán)節(jié)已經(jīng)報錯返回 504 了。所以在這種應(yīng)用場景下,維護這么多的超時次數(shù)其實沒有任何意義。倒不如把他們設(shè)置的小一些,盡早放棄。其中客戶端的 syn 重傳次數(shù)由 tcp_syn_retries 控制,服務(wù)器半連接隊列中的超時次數(shù)是由 tcp_synack_retries 來控制。把它們兩個調(diào)成你想要的值。
建議14:如果請求頻繁,請棄用短連接改用長連接
如果你的服務(wù)器頻繁請求某個 server,比如 redis 緩存。和建議 1 比起來,一個更好一點的方法是使用長連接。這樣的好處有
1)節(jié)約了握手開銷。短連接中每次請求都需要服務(wù)和緩存之間進行握手,這樣每次都得讓用戶多等一個握手的時間開銷。
2)規(guī)避了隊列滿的問題。前面我們看到當(dāng)全連接或者半連接隊列溢出的時候,服務(wù)器直接丟包。而客戶端呢并不知情,所以傻傻地等 3 秒才會重試。要知道 tcp 本身并不是專門為互聯(lián)網(wǎng)服務(wù)設(shè)計的。這個 3 秒的超時對于互聯(lián)網(wǎng)用戶的體驗影響是致命的。
3)端口數(shù)不容易出問題。端連接中,在釋放連接的時候,客戶端使用的端口需要進入 TIME_WAIT 狀態(tài),等待 2 MSL的時間才能釋放。所以如果連接頻繁,端口數(shù)量很容易不夠用。而長連接就固定使用那么幾十上百個端口就夠用了。
建議15:TIME_WAIT 的優(yōu)化
很多線上服務(wù)如果使用了短連接的情況下,就會出現(xiàn)大量的 TIME_WAIT。
首先,我想說的是沒有必要見到兩三萬個 TIME_WAIT 就恐慌的不行。從內(nèi)存的?度來考慮,一條 TIME_WAIT 狀態(tài)的連接僅僅是 0.5 KB 的內(nèi)存而已。從端口占用的角度來說,確實是消耗掉了一個端口。但假如你下次再連接的是不同的 Server 的話,該端口仍然可以使用。只有在所有 TIME_WAIT 都聚集在和一個 Server 的連接上的時候才會有問題。
那怎么解決呢? 其實辦法有很多。第一個辦法是按上面建議開啟端口 reuse 和 recycle。 第二個辦法是限制 TIME_WAIT 狀態(tài)的連接的最大數(shù)量。
# vi /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 32768
# sysctl -p
如果再徹底一些,也可以干脆直接用?連接代替頻繁的短連接。連接頻率大大降低以后,自然也就沒有 TIME_WAIT 的問題了。?