接口性能優化的 15 個技巧

大家好,我是Tom哥。
作為后端研發同學為了幾兩碎銀,沒日沒夜周旋于各種人、各種事上。
如果你要想成長的更快,就要學會歸納總結,找到規律,并且善用這些規律。
就比如工作,雖然事情很多、也很繁瑣,但如果按照性質歸下類,我覺得可以分為兩大類:
- 業務類,如:產品要做一個紅包活動,下周一就要上線,于是研發同學就吭哧吭哧,周末加班不睡覺也要趕出來
- 技術類,如:架構升級、系統優化等,這類事情對技術能力有一定要求,通常要求有一定的項目經驗的同學來 owner
關于業務類的內容很大程度依賴于產品同學的節奏,研發更多是被動角色,我們能做的是就是多跟產品聊天,「實時」了解產品的最新動向,培養自己的業務 sense,給自己多預留一定的buffer時間可以去做技術調研、技術儲備。
工作過一段時間同學一般都經歷過,產品變化節奏很快,經常都是倒排時間,讓研發苦不堪言。
至于技術類,相對就比較溫和的多了,不過也非常考驗研發的技術實力。
今天,我們就來聊下關于接口性能優化有哪些技巧?
1、本地緩存
本地緩存,最大的優點是應用和cache是在同一個進程內部,請求緩存非常快速,沒有過多的網絡開銷等,在單應用不需要集群支持或者集群情況下各節點無需互相通知的場景下使用本地緩存較合適。缺點也是因為緩存跟應用程序耦合,多個應用程序無法直接的共享緩存,各應用或集群的各節點都需要維護自己的單獨緩存,對內存是一種浪費。
常用的本地緩存框架有 Guava、Caffeine 等,都是些單獨的jar包 ,直接導入到工程里即可使用。
我們可以根據自己的需要靈活選擇想要哪個框架

使用門檻比較低, 大家可以自行網上搜索相應的教程,這里就不展開了。
本地緩存適用兩種場景:
- 對緩存內容時效性要求不高,能接受一定的延遲,可以設置較短過期時間,被動失效更新保持數據的新鮮度
- 緩存的內容不會改變。比如:訂單號與uid的映射關系,一旦創建就不會發生改變
注意問題:
- 內存 Cache 數據條目上限控制,避免內存占用過多導致應用癱瘓。
- 內存中的數據移出策略
- 雖然實現簡單,但潛在的坑比較多,最好選擇一些成熟的開源框架
2、分布式緩存
本地緩存的使用很容易讓你的應用服務器帶上“狀態”,而且容易受內存大小的限制。
分布式緩存借助分布式的概念,集群化部署,獨立運維,容量無上限,雖然會有網絡傳輸的損耗,但這1~2ms的延遲相比其更多優勢完成可以忽略。
優秀的分布式緩存系統有大家所熟知的 Memcached 、Redis。對比關系型數據庫和緩存存儲,其在讀和寫性能上的差距可謂天壤之別,redis單節點已經可以做到 8W+ QPS。設計方案時盡量把讀寫壓力從數據庫轉移到緩存上,有效保護脆弱的關系型數據庫。
注意問題:
- 緩存的命中率,如果太低無法起到抗壓的作用,壓力還是壓到了下游的存儲層
- 緩存的空間大小,這個要根據具體業務場景來評估,防止空間不足,導致一些熱點數據被置換出去
- 緩存數據的一致性
- 緩存的快速擴容問題
- 緩存的接口平均RT,最大RT,最小RT
- 緩存的QPS
- 網絡出口流量
- 客戶端連接數
3、并行化
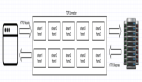
梳理業務流程,畫出時序圖,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化處理能力
如下圖所示,存在上下文依賴的采用串行處理,否則采用并行處理。
JDK 的 CompletableFuture 提供了非常豐富的API,大約有50種 處理串行、并行、組合以及處理錯誤的方法,可以滿足我們的場景需求。
4、異步化
一個接口的 RT 響應時間是由內部業務邏輯的復雜度決定的,執行的流程約簡單,那接口的耗費時間就越少。
所以,普遍做法就是將接口內部的非核心邏輯剝離出來,異步化來執行。
下圖是一個電商的創建訂單接口,創建訂單記錄并插入數據庫是我們的核心訴求,至于后續的用戶通知,如:給用戶發個短信等,如果失敗,并不影響主流程的完成。
我們會將這些操作從主流程中剝離出來。
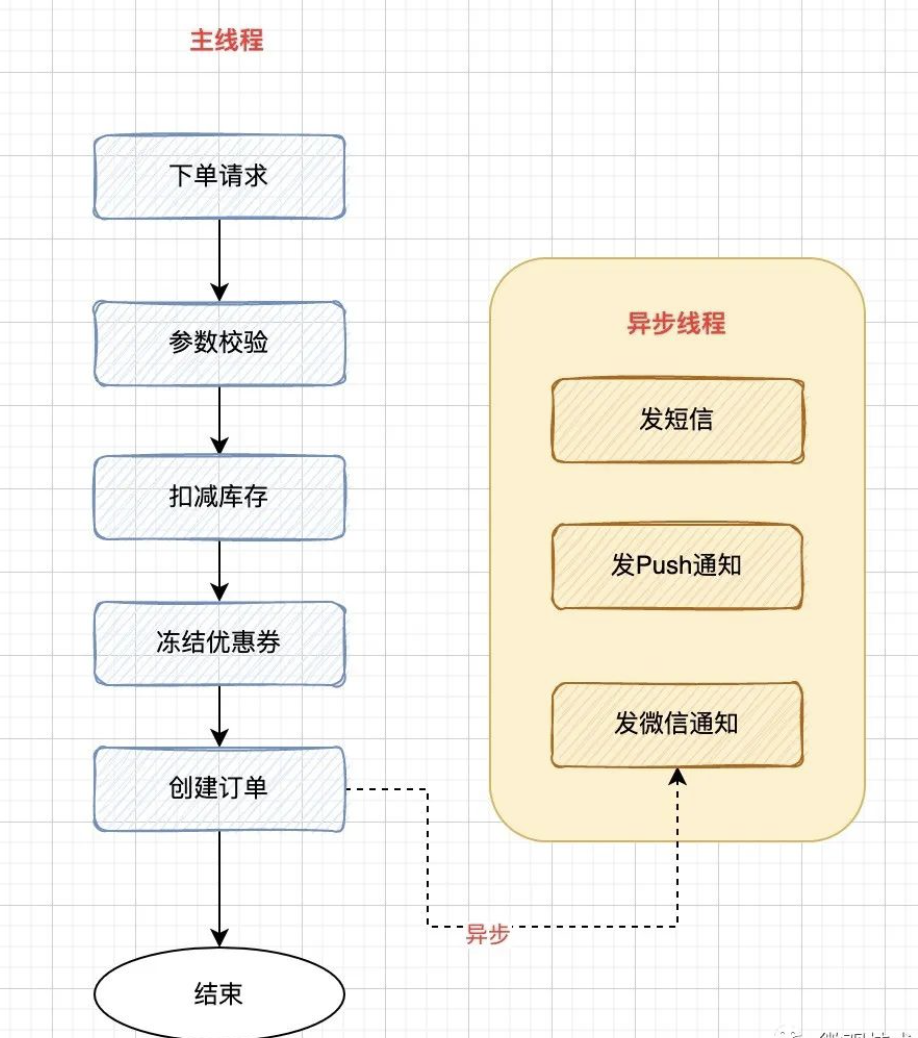
業務的普遍做法就是,下單成功后,發送一條異步消息到MQ 服務器,由消費端監聽 topic,異步消費執行,通過發布/訂閱 模式也能支持一些新的消費任務的快速接入。
5、池化技術
TCP 三次握手非常耗費性能,所以我們引入了 Keep-Alive 長連接,避免頻繁的創建、銷毀連接。
池化技術也是類似道理,將很多能重復使用的對象緩存起來,放到一個池子里,用的時候去申請一個實例對象 ,用完后再放回池子里。
池化技術的核心是資源的“預分配”和“循環使用”,常見的池化技術的使用有:線程池、內存池、數據庫連接池、HttpClient 連接池等
連接池的幾個重要參數:最小連接數、空閑連接數、最大連接數
比如創建一個線程池:
new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("data-thread-%d").build(),
(r, executor) -> {
if (r instanceof BaseRunnable) {
((BaseRunnable) r).rejectedExecute();
}
});6、分庫分表
MySQL的底層 innodb 存儲引擎采用 B+ 樹結構,三層結構支持千萬級的數據存儲。
當然,現在互聯網的用戶基數非常大,這么大的用戶量,單表通常很難支撐業務需求,將一個大表水平拆分成多張結構一樣的物理表,可以極大緩解存儲、訪問壓力。
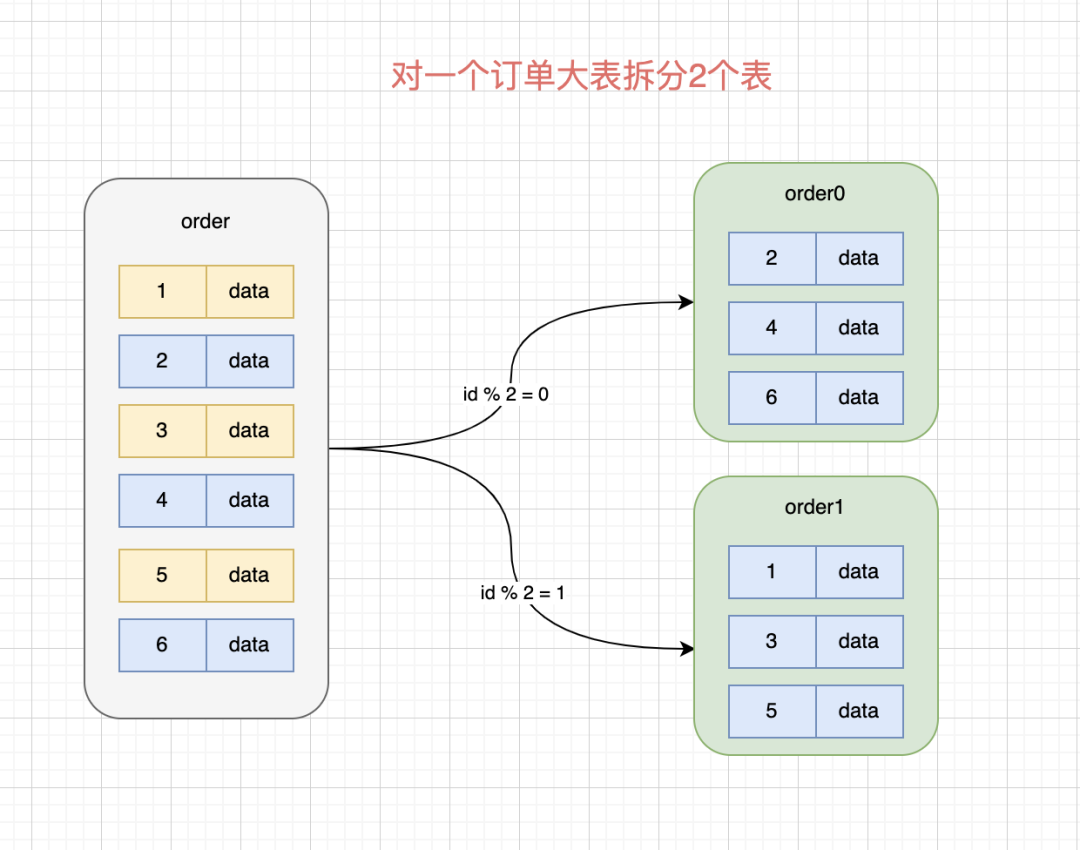
分庫分表也可能會帶入很多問題:
- 分庫分表后,數據在分表內產生數據傾斜
- 如何創建全局性的唯一主鍵id
- 數據如何路由到哪一個分片
每一個問題展開都要花費很長篇幅來講解,這里主要講接口性能優化的方案匯總,就不展開細講了。
關于分庫分表,市場受歡迎的開源框架是 sharding-jdbc,目前已經捐贈給Apache并啟動孵化
7、SQL 優化
雖然有了分庫分表,從存儲維度可以減少很大壓力,但「富不過三代」,我們還是要學會精打細算,就比如所有的數據庫操作都是通過 SQL 來執行。
一個不好的SQL會對接口性能產生很大影響。
比如:
- 搞了個深度翻頁,每次數據庫引擎都要預查非常多的數據
- 索引缺失,走了全表掃描
- 一條 SQL 一次查詢 幾萬條數據
SQL 優化的經驗非常多,比如:
- SQL 查詢時,盡量不要使用 select * ,而是 select 具體字段
- 如果只有一條查詢結果(或者最大值、最小值),建議使用 limit 1
- 索引不宜太多,一般控制在 5個以內
- where 語句中盡量避免使用 or來連接條件。or 可能會導致索引失效,從而全表掃描
- 索引盡量避免建在有大量重復數據的字段上,如:性別
- where 、 order by 涉及的列上建索引,避免全表掃描
- 更多.....
SQL 優化的內容非常多,這里就不展開了
8、預先計算
有很多業務的計算邏輯比較復雜,比如頁面要展示一個網站的 PV、微信的拼手氣紅包等
如果在用戶訪問接口的瞬間觸發計算邏輯,而這些邏輯計算的耗時通常比較長,很難滿足用戶的實時性要求。
一般我們都是提前計算,然后將算好的數據預熱到緩存中,接口訪問時,只需要讀緩存即可
是不是一下子就快了很多。
9、事務相關
很多業務邏輯有事務要求,針對多個表的寫操作要保證事務特性。
但事務本身又特別耗費性能,為了能盡快結束,不長時間占用數據庫連接資源,我們一般要減少事務的范圍。
將很多查詢邏輯放到事務外部處理。
另外在事務內部,一般不要進行遠程的 RPC 接口訪問,一般占用的時間比較長。
10、海量數據處理
如果數據量過大,除了采用關系型數據庫的分庫分表外,我們還可以采用 NoSQL
如:MongoDB、Hbase、Elasticsearch、TiDB
NoSQL 采用分區架構,對數據海量存儲能較好的支持,但是事務方面可能沒那么友好。
每一個 NoSQL 框架都有自己的特色,有支持 搜索的、有列式存儲、有文檔存儲,大家可以根據自己的業務場景選擇合適的框架。
11、批量讀寫
當下的計算機CPU處理速度還是很多的,而 IO 一般是個瓶頸,如:磁盤IO、網絡IO。
有這么一個場景,查詢 100 個人的賬戶余額?
有兩個設計方案:
方案一:開單次查詢接口,調用方內部循環調用 100 次
方案二:服務提供方開一個批量查詢接口,調用方只需查詢 1 次
你覺得那種方案更好?
答案不言而喻,肯定是方案二
數據庫的寫操作也是一樣道理,為了提高性能,我們一般都是采用批量更新。
12、鎖的粒度
并發業務,為了防止數據的并發更新對數據的正確性產生干擾,我們通常是采用 加鎖 ,涉及獨享資源每次只能是一個線程來處理。
問題點在于,鎖是成對出現的,有加鎖就是釋放鎖。
對于非競爭資源,我們沒有必要圈在鎖內部,會嚴重影響系統的并發能力。
控制鎖的范圍是我們要考慮的重點。
13、上下文傳遞
Tom哥帶團隊對小伙伴有要求,代碼必須要有 code review 環節,review 同學代碼經常發現一個問題。
當需要一個數據時,如果沒有調 RPC 接口去查,比如想用戶信息這種通用型接口
因為前面要用,肯定已經查過。但是我們知道方法的調用都是以棧幀的形式來傳遞,隨著一個方法執行完畢而出棧,方法內部的局部變量也就被回收了。
后面如果又要用到這個信息,只能重新去查。
如果能定義一個Context 上下文對象,將一些中間信息存儲并傳遞下來,會大大減輕后面流程的再次查詢壓力。
14、空間大小
如何創建一個集合,這還不簡單,很快我們就寫出下面代碼
List lists = Lists.newArrayList();
如果說,要往里面插入 1000000 個元素,有沒有更好的方式?
我們做個試驗:
場景一:

結果:1000000 次插入 List,花費時間:154
場景二:

結果:1000000 次插入 List,花費時間:134
如果我們預先知道集合要存儲多少元素,初始化集合時盡量指定大小,尤其是容量較大的集合。
ArrayList 初始大小是 10,超過閾值會按 1.5 倍大小擴容,涉及老集合到新集合的數據拷貝,浪費性能。
15、查詢優化
避免一次從 DB 中查詢大量的數據到內存中,可能會導致內存不足,建議采用分批、分頁查詢