流批一體在京東的探索與實(shí)踐
?摘要:本文整理自京東高級技術(shù)專家韓飛在 Flink Forward Asia 2021 流批一體專場的分享。主要內(nèi)容包括:
- 整體思考
- 技術(shù)方案及優(yōu)化
- 落地案例
- 未來展望??
01整體思考

提到流批一體,不得不提傳統(tǒng)的大數(shù)據(jù)平臺 —— Lambda 架構(gòu)。它能夠有效地支撐離線和實(shí)時(shí)的數(shù)據(jù)開發(fā)需求,但它流和批兩條數(shù)據(jù)鏈路割裂所導(dǎo)致的高開發(fā)維護(hù)成本以及數(shù)據(jù)口徑不一致是無法忽視的缺陷。
通過一套數(shù)據(jù)鏈路來同時(shí)滿足流和批的數(shù)據(jù)處理需求是最理想的情況,即流批一體。此外我們認(rèn)為流批一體還存在一些中間階段,比如只實(shí)現(xiàn)計(jì)算的統(tǒng)一或者只實(shí)現(xiàn)存儲的統(tǒng)一也是有重大意義的。
以只實(shí)現(xiàn)計(jì)算統(tǒng)一為例,有一些數(shù)據(jù)應(yīng)用的實(shí)時(shí)性要求比較高,比如希望端到端的數(shù)據(jù)處理延時(shí)不超過一秒鐘,這對目前開源的、適合作為流批統(tǒng)一的存儲來說是一個(gè)很大的挑戰(zhàn)。以數(shù)據(jù)湖為例,它的數(shù)據(jù)可見性與 commit 的間隔相關(guān),進(jìn)而與 Flink 做 checkpoint 的時(shí)間間隔相關(guān),此特性結(jié)合數(shù)據(jù)處理鏈路的長度,可見做到端到端一秒鐘的處理并不容易。因此對于這類需求,只實(shí)現(xiàn)計(jì)算統(tǒng)一也是可行的。通過計(jì)算統(tǒng)一去降低用戶的開發(fā)及維護(hù)成本,解決數(shù)據(jù)口徑不一致的問題。

在流批一體技術(shù)落地的過程中,面臨的挑戰(zhàn)可以總結(jié)為以下 4 個(gè)方面:
- 首先是數(shù)據(jù)實(shí)時(shí)性。如何把端到端的數(shù)據(jù)時(shí)延降低到秒級別是一個(gè)很大的挑戰(zhàn),因?yàn)樗瑫r(shí)涉及到計(jì)算引擎及存儲技術(shù)。它本質(zhì)上屬于性能問題,也是一個(gè)長期目標(biāo)。
- 第二個(gè)挑戰(zhàn)是如何兼容好在數(shù)據(jù)處理領(lǐng)域已經(jīng)廣泛應(yīng)用的離線批處理能力。此處涉及開發(fā)和調(diào)度兩個(gè)層面的問題,開發(fā)層面主要是復(fù)用的問題,比如如何復(fù)用已經(jīng)存在的離線表的數(shù)據(jù)模型,如何復(fù)用用戶已經(jīng)在使用的自定義開發(fā)的 Hive UDF 等。調(diào)度層面的問題主要是如何合理地與調(diào)度系統(tǒng)進(jìn)行集成。
- 第三個(gè)挑戰(zhàn)是資源及部署問題。比如通過不同類型的流、批應(yīng)用的混合部署來提高資源利用率,以及如何基于 metrics 來構(gòu)建彈性伸縮能力,進(jìn)一步提高資源利用率。
- 最后一個(gè)挑戰(zhàn)也是最困難的一個(gè):用戶觀念。大多數(shù)用戶對于比較新的技術(shù)理念通常僅限于技術(shù)交流或者驗(yàn)證,即使驗(yàn)證之后覺得可以解決實(shí)際問題,也需要等待合適的業(yè)務(wù)來試水。這個(gè)問題也催生了一些思考,平臺側(cè)一定要多站在用戶的視角看待問題,合理地評估對用戶的現(xiàn)有技術(shù)架構(gòu)的改動成本以及用戶收益、業(yè)務(wù)遷移的潛在風(fēng)險(xiǎn)等。

上圖是京東實(shí)時(shí)計(jì)算平臺的全景圖,也是我們實(shí)現(xiàn)流批一體能力的載體。中間的 Flink 基于開源社區(qū)版本深度定制。基于該版本構(gòu)建的集群,外部依賴包含三個(gè)部分,JDOS、HDFS/CFS 和 Zookeeper。
- JDOS 是京東的 Kubernetes 平臺,目前我們所有 Flink 計(jì)算任務(wù)容器化的,都運(yùn)行在這套平臺之上;
- Flink 的狀態(tài)后端有 HDFS 和 CFS 兩種選擇,其中 CFS 是京東自研的對象存儲;
- Flink 集群的高可用是基于 Zookeeper 構(gòu)建的。
在應(yīng)用開發(fā)方式方面,平臺提供 SQL 和 Jar 包兩種方式,其中 Jar 的方式支持用戶直接上傳 Flink 應(yīng)用 Jar 包或者提供 Git 地址由平臺來負(fù)責(zé)打包。除此之外我們平臺化的功能也相對比較完善,比如基礎(chǔ)的元數(shù)據(jù)服務(wù)、SQL 調(diào)試功能,產(chǎn)品端支持所有的參數(shù)配置,以及基于 metrics 的監(jiān)控、任務(wù)日志查詢等。
連接數(shù)據(jù)源方面,平臺通過 connector 支持了豐富的數(shù)據(jù)源類型,其中 JDQ 基于開源 Kafka 定制,主要應(yīng)用于大數(shù)據(jù)場景的消息隊(duì)列;JMQ 是京東自研,主要應(yīng)用于在線系統(tǒng)的消息隊(duì)列;JimDB 是京東自研的分布式 KV 存儲。

在當(dāng)前 Lambda 架構(gòu)中,假設(shè)實(shí)時(shí)鏈路的數(shù)據(jù)存儲在 JDQ,離線鏈路的數(shù)據(jù)存在 Hive 表中,即便計(jì)算的是同一業(yè)務(wù)模型,元數(shù)據(jù)的定義也常常是存在差異的,因此我們引入統(tǒng)一的邏輯模型來兼容實(shí)時(shí)離線兩邊的元數(shù)據(jù)。
在計(jì)算環(huán)節(jié),通過 FlinkSQL 結(jié)合 UDF 的方式來實(shí)現(xiàn)業(yè)務(wù)邏輯的流批統(tǒng)一計(jì)算,此外平臺會提供大量的公用 UDF,同時(shí)也支持用戶上傳自定義 UDF。針對計(jì)算結(jié)果的輸出,我們同樣引入統(tǒng)一的邏輯模型來屏蔽流批兩端的差異。對于只實(shí)現(xiàn)計(jì)算統(tǒng)一的場景,可以將計(jì)算結(jié)果分別寫入流批各自對應(yīng)的存儲,以保證數(shù)據(jù)的實(shí)時(shí)性與先前保持一致。
對于同時(shí)實(shí)現(xiàn)計(jì)算統(tǒng)一和存儲統(tǒng)一的場景,我們可以將計(jì)算的結(jié)果直接寫入到流批統(tǒng)一的存儲。我們選擇了 Iceberg 作為流批統(tǒng)一的存儲,因?yàn)樗鼡碛辛己玫募軜?gòu)設(shè)計(jì),比如不會綁定到某一個(gè)特定的引擎等。

在兼容批處理能力方面,我們主要進(jìn)行了以下三個(gè)方面的工作:
第一,復(fù)用離線數(shù)倉中的 Hive 表。
以數(shù)據(jù)源端為例,為了屏蔽上圖左側(cè)圖中流、批兩端元數(shù)據(jù)的差異,我們定義了邏輯模型 gdm_order_m 表,并且需要用戶顯示地指定 Hive 表和 Topic 中的字段與這張邏輯表中字段的映射關(guān)系。這里映射關(guān)系的定義非常重要,因?yàn)榛?FlinkSQL 的計(jì)算只需面向這張邏輯表,而無需關(guān)心實(shí)際的 Hive 表與 Topic 中的字段信息。在運(yùn)行時(shí)通過 connector 創(chuàng)建流表和批表的時(shí)候,邏輯表中的字段會通過映射關(guān)系被替換成實(shí)際的字段。
在產(chǎn)品端,我們可以給邏輯表分別綁定流表和批表,通過拖拽的方式來指定字段之間的映射關(guān)系。這種模式使得我們的開發(fā)方式與之前有所差異,之前的方式是先新建一個(gè)任務(wù)并指定是流任務(wù)還是批任務(wù),然后進(jìn)行 SQL 開發(fā),再去指定任務(wù)相關(guān)的配置,最后發(fā)布任務(wù)。而在流批一體模式下,開發(fā)模式變?yōu)榱耸紫韧瓿?SQL 的開發(fā),其中包括邏輯的、物理的 DDL 的定義,以及它們之間的字段映射關(guān)系的指定,DML 的編寫等,然后分別指定流批任務(wù)相關(guān)的配置,最后發(fā)布成流批兩個(gè)任務(wù)。
第二,與調(diào)度系統(tǒng)打通。
離線數(shù)倉的數(shù)據(jù)加工基本是以 Hive/Spark 結(jié)合調(diào)度的模式,以上圖中居中的圖為例,數(shù)據(jù)的加工被分為 4 個(gè)階段,分別對應(yīng)數(shù)倉的 BDM、FDM、GDM 和 ADM 層。隨著 Flink 能力的增強(qiáng),用戶希望把 GDM 層的數(shù)據(jù)加工任務(wù)替換為 FlinkSQL 的批任務(wù),這就需要把 FlinkSQL 批任務(wù)嵌入到當(dāng)前的數(shù)據(jù)加工過程中,作為中間的一個(gè)環(huán)節(jié)。
為了解決這個(gè)問題,除了任務(wù)本身支持配置調(diào)度規(guī)則,我們還打通了調(diào)度系統(tǒng),從中繼承了父任務(wù)的依賴關(guān)系,并將任務(wù)自身的信息同步到調(diào)度系統(tǒng)中,支持作為下游任務(wù)的父任務(wù),從而實(shí)現(xiàn)了將 FlinkSQL 的批任務(wù)作為原數(shù)據(jù)加工的其中一個(gè)環(huán)節(jié)。
第三,對用戶自定義的 Hive UDF、UDAF 及 UDTF 的復(fù)用。
對于現(xiàn)存的基于 Hive 的離線加工任務(wù),如果用戶已經(jīng)開發(fā)了 UDF 函數(shù),那么最理想的方式是在遷移 Flink 時(shí)對這些 UDF 進(jìn)行直接復(fù)用,而不是按照 Flink UDF 定義重新實(shí)現(xiàn)。
在 UDF 的兼容問題上,針對使用 Hive 內(nèi)置函數(shù)的場景,社區(qū)提供了 load hive modules 方案。如果用戶希望使用自己開發(fā)的 Hive UDF,可以通過使用 create catalog、use catalog、create function,最后在 DML 中調(diào)用的方式來實(shí)現(xiàn), 這個(gè)過程會將 Function 的信息注冊到 Hive 的 Metastore 中。從平臺管理的角度,我們希望用戶的 UDF 具備一定的隔離性,限制用戶 Job 的粒度,減少與 Hive Metastore 交互以及產(chǎn)生臟函數(shù)元數(shù)據(jù)的風(fēng)險(xiǎn)。
此外,當(dāng)元信息已經(jīng)被注冊過,希望下次能在 Flink 平臺端正常使用,如果不使用 if not exist 語法,通常需要先 drop function,再進(jìn)行 create 操作。但是這種方式不夠優(yōu)雅,同時(shí)也對用戶的使用方式有限制。另一種解決方法是用戶可以注冊臨時(shí)的 Hive UDF,在 Flink1.12 中注冊臨時(shí) UDF 的方式是 create temporary function,但是該 Function 需要實(shí)現(xiàn) UserDefinedFunction 接口后才能通過后面的校驗(yàn),否則會注冊失敗。
所以我們并沒有使用 create temporary function,而是對 create function 做了一些調(diào)整,擴(kuò)展了 ExtFunctionModule,將解析出來的 FunctionDefinition 注冊到 ExtFunctionModule 中,做了一次 Job 級別的臨時(shí)注冊。這樣的好處就是不會污染 Hive Metastore,提供了良好的隔離性,同時(shí)也沒有對用戶的使用習(xí)慣產(chǎn)生限制,提供了良好的體驗(yàn)。
不過這個(gè)問題在社區(qū) 1.13 的版本已經(jīng)得到了綜合的解決。通過引入 Hive 解析器等擴(kuò)展,已經(jīng)可以把實(shí)現(xiàn) UDF、GenericUDF 接口的自定義 Hive 函數(shù)通過 create temporary function 語法進(jìn)行注冊和使用。

資源占用方面,流處理和批處理是天然錯(cuò)峰的。對于批處理,離線數(shù)倉每天 0 點(diǎn)開始計(jì)算過去一整天的數(shù)據(jù),所有的離線報(bào)表的數(shù)據(jù)加工會在第二天上班前全部完成,所以通常 00:00 到 8:00 是批計(jì)算任務(wù)大量占用資源的時(shí)間段,而這個(gè)時(shí)間段通常在線的流量都比較低。流處理的負(fù)載與在線的流量是正相關(guān)的,所以這個(gè)時(shí)間段流處理的資源需求是比較低的。上午 8 點(diǎn)到晚上 0 點(diǎn),在線的流量比較高,而這個(gè)時(shí)間段批處理的任務(wù)大部分都不會被觸發(fā)執(zhí)行。
基于這種天然的錯(cuò)峰,我們可以通過在專屬的 JDOS Zone 中進(jìn)行不同類型的流批應(yīng)用的混部來提升資源的使用率,并且如果統(tǒng)一使用 Flink 引擎來處理流批應(yīng)用,資源的使用率會更高。
同時(shí)為了使應(yīng)用可以基于流量進(jìn)行動態(tài)調(diào)整,我們還開發(fā)了自動彈性伸縮的服務(wù) (Auto-Scaling Service)。它的工作原理如下:運(yùn)行在平臺上的 Flink 任務(wù)上報(bào) metrics 信息到 metrics 系統(tǒng),Auto-Scaling Service 會基于 metrics 系統(tǒng)中的一些關(guān)鍵指標(biāo),比如 TaskManager 的 CPU 使用率、任務(wù)的背壓情況等來判定任務(wù)是否需要增減計(jì)算資源,并把調(diào)整的結(jié)果反饋給 JRC 平臺,JRC 平臺通過內(nèi)嵌的 fabric 客戶端將調(diào)整的結(jié)果同步到 JDOS 平臺,從而完成對 TaskManager Pod 個(gè)數(shù)的調(diào)整。此外,用戶可以在 JRC 平臺上通過配置來決定是否為任務(wù)開啟此功能。
上圖右側(cè)圖表是我們在 JDOS Zone 中進(jìn)行流批混部并結(jié)合彈性伸縮服務(wù)試點(diǎn)測試時(shí)的 CPU 使用情況。可以看到 0 點(diǎn)流任務(wù)進(jìn)行了縮容,將資源釋放給批任務(wù)。我們設(shè)置的新任務(wù)在 2 點(diǎn)開始執(zhí)行,所以從 2 點(diǎn)開始直到早上批任務(wù)結(jié)束這段時(shí)間,CPU 的使用率都比較高,最高到 80% 以上。批任務(wù)運(yùn)行結(jié)束后,在線流量開始增長時(shí),流任務(wù)進(jìn)行了擴(kuò)容,CPU 的使用率也隨之上升。
02技術(shù)方案及優(yōu)化
流批一體是以 FlinkSQL 為核心載體,所以我們對于 FlinkSQL 的底層能力也做了一些優(yōu)化,主要分為維表優(yōu)化、join 優(yōu)化、window 優(yōu)化和 Iceberg connector 優(yōu)化幾個(gè)方面。

首先是維表相關(guān)的幾個(gè)優(yōu)化。目前社區(qū)版本的 FlinkSQL 只支持部分?jǐn)?shù)據(jù)源 sink 算子并行度的修改,并不支持 source 以及中間處理算子的并行度修改。
假設(shè)一個(gè) FlinkSQL 任務(wù)消費(fèi)的 topic 有 5 個(gè)分區(qū),那么下游算子的實(shí)際并行度是 5,算子之間是 forward 的關(guān)系。對于數(shù)據(jù)量比較大的維表 join 場景,為了提高效率,我們希望并行度高一些,希望可以靈活設(shè)置它的并行度而不與上游的分區(qū)數(shù)綁定。
基于此,我們開發(fā)了預(yù)覽拓?fù)涞墓δ埽徽撌?Jar 包、SQL 任務(wù)都可以解析并生成 StreamGraph 進(jìn)行預(yù)覽,進(jìn)一步還能支持修改分組、算子 chain 的策略、并行度、設(shè)置 uid 等。
借助這個(gè)功能,我們還可以調(diào)整維表 join 算子的并行度,并且將分區(qū)策略由 forward 調(diào)整為 rebalance,然后把這些調(diào)整后的信息更新到 StreamGraph。此外我們還實(shí)現(xiàn)了動態(tài) rebalance 策略,可以基于 backLog 去判斷下游分區(qū)中的負(fù)載情況,從而選擇最優(yōu)的分區(qū)進(jìn)行數(shù)據(jù)分發(fā)。

為了提升維表 join 的性能,我們對所有平臺支持的維表數(shù)據(jù)源類型都實(shí)現(xiàn)了異步 IO 并支持在內(nèi)存中做緩存。不論是原生的 forward 方式還是 rebalance 方式,都存在緩存失效和替換的問題。那么,如何提高維表緩存的命中率以及如何降低維表緩存淘汰的操作?
以原生的 forward 方式為例,forward 意味著每個(gè) subtask 緩存著隨機(jī)的維表數(shù)據(jù),與 joinkey 的值有關(guān)。對維表的 joinkey 做哈希,就能保證下游每一個(gè)算子緩存著與 joinkey 相關(guān)的、不同的維表數(shù)據(jù),從而有效地提升緩存的命中率。
在實(shí)現(xiàn)層面我們新增了一條叫 StreamExecLookupHashJoinRule 的優(yōu)化規(guī)則,并且把它添加到物理 rewrite 的階段。在最底層的掃描數(shù)據(jù) StreamExecTableSourceScan 和維表 join StreamExecLookupJoin 之間增加了一個(gè) StreamExecChange 節(jié)點(diǎn),由它來完成對維表數(shù)據(jù)的哈希操作。可以通過在定義維表 DDL 時(shí)指定 lookup.hash.enable=true 來開啟這個(gè)功能。
我們對于 forward、rebalance、哈希三種方式開啟緩存,進(jìn)行了相同場景的性能測試。主表一億條數(shù)據(jù)去 join 維表的 1 萬條數(shù)據(jù),在不同的計(jì)算資源下,rebalance 相較于原生的 forward 方式有數(shù)倍的性能提升,而哈希相較于 rebalance 的方式又有數(shù)倍的性能提升,整體效果是比較可觀的。

針對維表 join 單條查詢效率比較低的問題,解決思路也很簡單,就是攢批,按照微批的方式去訪問 (mini-batch)。可以在 DDL 的定義中通過設(shè)置 lookup.async.batch.size 的值來指定批次的大小。除此之外,我們還在時(shí)間維度上引入了 Linger 機(jī)制來做限制,防止極端場景出現(xiàn)遲遲無法攢夠一批數(shù)據(jù)而導(dǎo)致時(shí)延比較高的情況,可以通過在 DDL 的定義中設(shè)置 lookup.async.batch.linger 的值來指定等待時(shí)間。
經(jīng)過測試,mini-batch 的方式能夠帶來 15% ~ 50% 的性能提升。

Interval join 也是生產(chǎn)上一個(gè)使用比較頻繁的場景,這類業(yè)務(wù)的特點(diǎn)是流量非常大,比如 10 分鐘百 GB 級別。Interval join 兩條流的數(shù)據(jù)都會緩存在內(nèi)部 state 中,任意一邊的數(shù)據(jù)到達(dá)都會獲取對面流相應(yīng)時(shí)間范圍的數(shù)據(jù)去執(zhí)行 join function,所以這種大流量的任務(wù)會有非常大的狀態(tài)。
對此我們選用了 RocksDB 來做狀態(tài)后端,但是進(jìn)行了調(diào)參優(yōu)化后效果仍不理想,任務(wù)運(yùn)行一段時(shí)間之后會出現(xiàn)背壓,導(dǎo)致 RocksDB 的性能下降,CPU 的使用率也比較高。
通過分析我們發(fā)現(xiàn),根本原因與 Flink 底層掃描 RocksDB 是基于前綴的掃描方式有關(guān)。因此解決思路也很簡單,根據(jù)查詢條件,精確地構(gòu)建查詢的上下界,把前綴查詢變?yōu)榉秶樵儭2樵儣l件依賴的具體上下界的 key 變?yōu)榱?keyGroup+joinKey+namespace+timestamp[lower,upper],可以精確地只查詢某些 timestamp 之間的數(shù)據(jù),任務(wù)的背壓問題也得到了解決。而且數(shù)據(jù)量越大,這種優(yōu)化帶來的性能提升越明顯。

Regular join 使用狀態(tài)來保存所有歷史數(shù)據(jù),所以如果流量大也會導(dǎo)致狀態(tài)數(shù)據(jù)比較大。而它保存狀態(tài)是依賴 table.exec.state.ttl 參數(shù),這個(gè)參數(shù)值比較大也會導(dǎo)致狀態(tài)大。
針對這種場景,我們改為使用外部存儲JimDB存儲狀態(tài)數(shù)據(jù)。目前只做了 inner join 的實(shí)現(xiàn),實(shí)現(xiàn)機(jī)制如下:兩邊的流對 join 到的數(shù)據(jù)進(jìn)行下發(fā)的同時(shí),將所有數(shù)據(jù)以 mini-batch 的方式寫入到 JimDB,join 時(shí)會同時(shí)掃描內(nèi)存中以及 JimDB 中對應(yīng)的數(shù)據(jù)。此外,可以通過 JimDB ttl 的機(jī)制來實(shí)現(xiàn) table.exec.state.ttl 功能,從而完成對過期數(shù)據(jù)的清理。
上述實(shí)現(xiàn)方式優(yōu)缺點(diǎn)都比較明顯,優(yōu)點(diǎn)是可以支持非常大的狀態(tài),缺點(diǎn)是目前無法被 Flink checkpoint 覆蓋到。

對于 window 的優(yōu)化,首先是窗口偏移量。需求最早來源于一個(gè)線上場景,比如我們想統(tǒng)計(jì)某個(gè)指標(biāo) 2021 年 12 月 4 日 0 點(diǎn) ~ 2021 年 12 月 5 日 0 點(diǎn)的結(jié)果, 但由于線上集群是東 8 區(qū)時(shí)間,所以實(shí)際統(tǒng)計(jì)的結(jié)果是 2021 年 12 月 4 日早上 8 點(diǎn) ~ 2021 年 12 月 5 日早上 8 點(diǎn)的結(jié)果,這顯然不符合預(yù)期。因此這個(gè)功能最早是為了修復(fù)非本地時(shí)區(qū)跨天級別的窗口統(tǒng)計(jì)錯(cuò)誤的問題。
在我們增加了窗口偏移量參數(shù)后,可以非常靈活地設(shè)置窗口的起始時(shí)間,能夠支持的需求也更廣泛。
其次,還存在另外一個(gè)場景:雖然用戶設(shè)定了窗口大小,但是他希望更早看到窗口當(dāng)前的計(jì)算結(jié)果,便于更早地去做決策。因此我們新增了增量窗口的功能,它可以根據(jù)設(shè)置的增量間隔,觸發(fā)執(zhí)行輸出窗口的當(dāng)前計(jì)算結(jié)果。

對于端到端實(shí)時(shí)性要求不高的應(yīng)用,可以選擇 Iceberg 作為下游的統(tǒng)一存儲。但是鑒于計(jì)算本身的特性、用戶 checkpoint 間隔的配置等原因,可能導(dǎo)致產(chǎn)生大量的小文件。Iceberg 的底層我們選用 HDFS 作為存儲,大量的小文件會對 Namenode 產(chǎn)生較大的壓力,所以就有了合并小文件的需求。
Flink 社區(qū)本身提供了基于 Flink batch job 的合并小文件的工具可以解決這個(gè)問題,但這種方式有點(diǎn)重,所以我們開發(fā)了算子級別的小文件合并的實(shí)現(xiàn)。思路是這樣的,在原生的 global commit 之后,我們新增了三個(gè)算子 compactCoordinator、 compactOperator 和 compactCommitter,其中 compactCoordinator 負(fù)責(zé)獲取待合并的 snapshot 并下發(fā),compactOperator 負(fù)責(zé) snapshot 的合并操作的執(zhí)行,并且可以多個(gè) compactOperator 并發(fā)執(zhí)行,compactCommitter 負(fù)責(zé)合并后 datafiles 的提交。
我們在 DDL 的定義中新增了兩個(gè)參數(shù),auto-compact 指定是否開啟合并文件的功能,compact.delta.commits 指定每提交多少次 commit 來觸發(fā)一次 compaction。

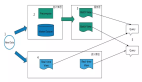
在實(shí)際的業(yè)務(wù)需求中,用戶可能會從 Iceberg 中讀取嵌套數(shù)據(jù),雖然可以在 SQL 中指定讀取嵌套字段內(nèi)部的數(shù)據(jù),但是在實(shí)際讀取數(shù)據(jù)時(shí)是會將包含當(dāng)前嵌套字段的所有字段都讀取到,再去獲取用戶需要的字段,而這會直接導(dǎo)致 CPU 和網(wǎng)絡(luò)帶寬負(fù)載的增高,所以就產(chǎn)生了如下需求:如何只讀取到用戶真正需要的字段?
解決這個(gè)問題,要滿足兩個(gè)條件,第一個(gè)條件是讀取 Iceberg 的數(shù)據(jù)結(jié)構(gòu) schema 只包含用戶需要的字段,第二個(gè)條件是 Iceberg 支持按列名去讀取數(shù)據(jù),而這個(gè)本身已經(jīng)滿足了,所以我們只需要實(shí)現(xiàn)第一個(gè)條件即可。
如上圖右側(cè)所示,結(jié)合之前的 tableSchema 和 projectFields 信息重構(gòu),生成了一個(gè)只包含用戶需要字段的新的數(shù)據(jù)結(jié)構(gòu) PruningTableSchema,并且作為 Iceberg schema 的輸入,通過這樣的操作實(shí)現(xiàn)了根據(jù)用戶的實(shí)際使用情況對嵌套結(jié)構(gòu)進(jìn)行列裁剪。圖中左下部的示例展示了用戶優(yōu)化前后讀取嵌套字段的對比,可以看到基于 PruningTablesSchema 能夠?qū)o用的字段進(jìn)行有效的裁剪。
經(jīng)過上述優(yōu)化,CPU 使用率降低了 20%~30%。而且,在相同的數(shù)據(jù)量下,批任務(wù)的執(zhí)行時(shí)間縮短了 20%~30%。

此外,我們還實(shí)現(xiàn)了一些其他優(yōu)化,比如修復(fù)了 interval outer join 數(shù)據(jù)晚于 watermark 下發(fā)、且下游有時(shí)間算子時(shí)會導(dǎo)致的數(shù)據(jù)丟失問題,UDF 的復(fù)用問題,F(xiàn)linkSQL 擴(kuò)展 KeyBy 語法,維表數(shù)據(jù)預(yù)加載以及 Iceberg connector 從指定的 snapshot 去讀取等功能。
03落地案例

京東目前 FlinkSQL 線上任務(wù) 700+,占Flink總?cè)蝿?wù)數(shù)的 15% 左右,F(xiàn)linkSQL 任務(wù)累計(jì)峰值處理能力超過 1.1 億條/秒。目前主要基于社區(qū)的 1.12 版本進(jìn)行了一些定制優(yōu)化。
3.1 案例一

實(shí)時(shí)通用數(shù)據(jù)層 RDDM 流批一體化的建設(shè)。RDDM 全稱是 real-time detail data model - 實(shí)時(shí)明細(xì)數(shù)據(jù)模型,它涉及訂單、流量、商品、用戶等,是京東實(shí)時(shí)數(shù)倉的重要一環(huán),服務(wù)了非常多的核心業(yè)務(wù),例如黃金眼/商智、JDV、廣告算法、搜推算法等。
RDDM 層的實(shí)時(shí)業(yè)務(wù)模型與離線數(shù)據(jù)中 ADM 和 GDM 層的業(yè)務(wù)加工邏輯一致。基于此,我們希望通過 FlinkSQL 來實(shí)現(xiàn)業(yè)務(wù)模型的流批計(jì)算統(tǒng)一。同時(shí)這些業(yè)務(wù)也具備非常鮮明的特點(diǎn),比如訂單相關(guān)的業(yè)務(wù)模型都涉及大狀態(tài)的處理,流量相關(guān)的業(yè)務(wù)模型對于端到端的實(shí)時(shí)性要求比較高。此外,某些特殊場景也需要一些定制化的開發(fā)來支持。

RDDM 的實(shí)現(xiàn)主要有兩個(gè)核心訴求:首先它的計(jì)算需要關(guān)聯(lián)的數(shù)據(jù)比較多的,大量的維度數(shù)據(jù)都存儲在 HBase 中;此外部分維度數(shù)據(jù)的查詢存在二級索引,需要先查詢索引表,從中取出符合條件的 key 再去維度表中獲取真正的數(shù)據(jù)。
針對上述需求,我們通過結(jié)合維表數(shù)據(jù)預(yù)加載的功能與維表 keyby 的功能來提升 join 的效率。針對二級索引的查詢需求,我們定制了 connector 來實(shí)現(xiàn)。
維表數(shù)據(jù)預(yù)加載的功能指在初始化的階段就將維表數(shù)據(jù)加載到內(nèi)存中,這個(gè)功能結(jié)合 keyby 使用可以非常有效地減少緩存的數(shù)量,提高命中率。
部分業(yè)務(wù)模型關(guān)聯(lián)的歷史數(shù)據(jù)比較多,導(dǎo)致狀態(tài)數(shù)據(jù)比較大,目前我們是根據(jù)場景進(jìn)行定制的優(yōu)化。我們認(rèn)為根本的解決方案是實(shí)現(xiàn)一套高效的基于 KV 的 statebackend,對于此功能的實(shí)現(xiàn)正在規(guī)劃中。
3.2 案例二

流量買賣黑產(chǎn)的輿情分析。它的主要流程如下:源端通過爬蟲獲取相關(guān)信息并寫入到 JMQ,數(shù)據(jù)同步到 JDQ 以后,通過 Flink 處理然后繼續(xù)寫下游的 JDQ。與此同時(shí),通過 DTS 數(shù)據(jù)傳輸服務(wù),將上游 JDQ 的數(shù)據(jù)同步到 HDFS,然后通過 Hive 表進(jìn)行離線的數(shù)據(jù)加工。
此業(yè)務(wù)有兩個(gè)特點(diǎn):首先,端到端的實(shí)時(shí)性要求不高,可以接受分鐘級別的延時(shí);第二,離線和實(shí)時(shí)的加工邏輯一致。因此,可以直接把中間環(huán)節(jié)的存儲從 JDQ 換成 Iceberg,然后通過 Flink 去增量讀取,并通過 FlinkSQL 實(shí)現(xiàn)業(yè)務(wù)邏輯加工,即完成了流批兩套鏈路的完全統(tǒng)一。其中 Iceberg 表中的數(shù)據(jù)也可以供 OLAP 查詢或離線做進(jìn)一步的加工。
上述鏈路端到端的時(shí)延在一分鐘左右,基于算子的小文件合并功能有效地提升了性能,存儲計(jì)算成本有了顯著的降低,綜合評估開發(fā)維護(hù)成本降低了 30% 以上。
04未來規(guī)劃

未來規(guī)劃主要分為以下兩個(gè)方面:
首先,業(yè)務(wù)拓展方面。我們會加大 FlinkSQL 任務(wù)的推廣,探索更多流批一體的業(yè)務(wù)場景,同時(shí)對產(chǎn)品形態(tài)進(jìn)行打磨,加速用戶向 SQL 的轉(zhuǎn)型。同時(shí),將平臺元數(shù)據(jù)與離線元數(shù)據(jù)做更深度的融合,提供更好的元數(shù)據(jù)服務(wù)。
其次,平臺能力方面。我們會繼續(xù)深挖 join 場景和大狀態(tài)場景,同時(shí)探索高效 KV 類型的狀態(tài)后端實(shí)現(xiàn),并在統(tǒng)一計(jì)算和統(tǒng)一存儲的框架下不斷優(yōu)化設(shè)計(jì),以降低端到端時(shí)延。?