快手流批一體數(shù)據(jù)湖構(gòu)建實(shí)踐

一、數(shù)據(jù)湖架構(gòu):從離線數(shù)倉到湖倉一體的轉(zhuǎn)變
數(shù)據(jù)建設(shè)的核心目標(biāo)一般為:
① 標(biāo)準(zhǔn)統(tǒng)一。
② 可共享。
③ 簡(jiǎn)單易用。
④ 高性能。
⑤ 成熟安全可靠。
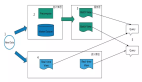
但是,現(xiàn)在常用來作為實(shí)現(xiàn)方案的 Lambda 架構(gòu),架構(gòu)一般如下:

這里存在三個(gè)比較嚴(yán)重的問題:
① 離線鏈路時(shí)效性差。若是直接在這個(gè)鏈路上進(jìn)行提效,則需要的成本比較高。
② 處理邏輯異構(gòu)。由于目前將實(shí)時(shí)數(shù)據(jù)和離線數(shù)據(jù)分成了兩個(gè)鏈路來處理數(shù)據(jù),導(dǎo)致很多的處理邏輯無法復(fù)用。同時(shí),也會(huì)存在一致性的問題。
③ 數(shù)據(jù)孤島。本身多個(gè)鏈路的生產(chǎn)會(huì)存在數(shù)據(jù)孤島,數(shù)據(jù)無法復(fù)用,并且管理相當(dāng)復(fù)雜。
為了解決上述問題,快手使用了數(shù)據(jù)湖作為數(shù)據(jù)建設(shè)的一個(gè)集中式倉儲(chǔ)方案。同時(shí),數(shù)據(jù)湖也能夠滿足數(shù)據(jù)建設(shè)的核心目標(biāo)。數(shù)據(jù)湖具有以下特性:
① 海量存儲(chǔ)。
② 支持可擴(kuò)展的數(shù)據(jù)類型。
③ Schema 演進(jìn)。
④ 支持可擴(kuò)展的數(shù)據(jù)源。
⑤ 強(qiáng)大的數(shù)據(jù)管理能力。
⑥ 高效數(shù)據(jù)處理。
⑦ 高性能的分析。
業(yè)內(nèi)有很多的數(shù)據(jù)湖開源實(shí)現(xiàn)方案,快手對(duì)這些方案的基礎(chǔ)優(yōu)勢(shì)及特性、社區(qū)建設(shè)情況和技術(shù)開發(fā)的可擴(kuò)展程度進(jìn)行了比較,最終選擇了 Hudi 作為數(shù)據(jù)湖實(shí)現(xiàn)方案。Hudi 在攝入、處理、存儲(chǔ)到查詢,基礎(chǔ)能力支持地比較完善,其具有的多個(gè)特點(diǎn)能夠支持?jǐn)?shù)據(jù)湖的快速構(gòu)建和應(yīng)用,這些特點(diǎn)包括:更新能力強(qiáng),支持流批讀寫,可插拔的 Payload,支持 MOR 表類型,適配多種查詢引擎,豐富的數(shù)據(jù)管理操作等。
Hudi 可以幫助快手構(gòu)建更優(yōu)的數(shù)據(jù)鏈路,去完成數(shù)據(jù)建設(shè)的核心目標(biāo),架構(gòu)參考如下:

快手基于 Hudi 構(gòu)建的數(shù)據(jù)湖架構(gòu)具有以下優(yōu)勢(shì):
① 數(shù)據(jù) CURD。優(yōu)化生產(chǎn)場(chǎng)景模型,提升了整體更新場(chǎng)景的時(shí)效;
② 流批讀寫。實(shí)現(xiàn)統(tǒng)一的處理,減少了多鏈路多引擎的建設(shè)成本;
③ 海量數(shù)據(jù)管理。對(duì)所有的入湖數(shù)據(jù)進(jìn)行統(tǒng)一管理,數(shù)據(jù)平臺(tái)的服務(wù)和管理方面能夠復(fù)用,降低數(shù)據(jù)的使用成本。
二、基于 Hudi 快速構(gòu)建快手?jǐn)?shù)據(jù)湖:
建設(shè)快手?jǐn)?shù)據(jù)湖遇到的挑戰(zhàn)以及解決方案
如何使用 Hudi 建設(shè)達(dá)到核心目標(biāo),需要先了解 Hudi 的基本能力:
① 支持不同類型的寫入方式:特別是通過增量寫入和數(shù)據(jù)合并的兩個(gè)基本操作,實(shí)現(xiàn)快照的生成;
② 可插拔:可支持所需要的更新邏輯,比如定制化更新模式,可以基于此進(jìn)行擴(kuò)展應(yīng)用場(chǎng)景;
③ 表類型:正如前面提到的,增量寫入和數(shù)據(jù)合并的操作共同組成快照更新。這兩種基本操作的實(shí)現(xiàn)決定了表的類型。不同類型的表,作用不同的應(yīng)用場(chǎng)景,比如寫多讀少的情況下,選擇使用 MOR 更實(shí)時(shí)和節(jié)約資源;
④ 元數(shù)據(jù)統(tǒng)計(jì):因?yàn)?Hudi 本身實(shí)現(xiàn)了更新能力,甚至在之上實(shí)現(xiàn)一部分的業(yè)務(wù)邏輯的,需要保障可描述、可追溯的能力。所以通過元數(shù)據(jù)的收集和應(yīng)用,來保證數(shù)據(jù)的可追溯性;
⑤ 讀取方式:支持 Hadoop 的 inputformat 的方式,兼容常用的查詢引擎,比如spark、trino 等。
使用這些能力,可以為生產(chǎn)鏈路實(shí)現(xiàn)提效與統(tǒng)一。
提效主要還是在優(yōu)化構(gòu)建離線數(shù)倉的時(shí)間:
① 比如分層建設(shè)時(shí),需要先同步數(shù)據(jù),然后再使用離線清洗,再生成后續(xù)的數(shù)倉的加工數(shù)據(jù)。現(xiàn)在可以直接一步通過 Flink 任務(wù)清洗實(shí)時(shí)數(shù)據(jù),然后使用 Hudi 多級(jí)動(dòng)態(tài)分區(qū)同步。
② 還有,在離線鏈路生產(chǎn)時(shí),有些數(shù)據(jù)生產(chǎn)是有更新邏輯的,比如更改部分?jǐn)?shù)據(jù)內(nèi)容。在老的架構(gòu)下,需要將所有數(shù)據(jù)都讀取一遍,然后將修改了某幾列的新數(shù)據(jù)再完全寫入。這里不但時(shí)效很差,而且成本消耗很大。現(xiàn)在可以利用 Hudi 的更新能力來高效地更新列數(shù)據(jù)。
③ 其他的,比如活動(dòng)的數(shù)據(jù)需要進(jìn)行快照分析時(shí),離線鏈路都是小時(shí)級(jí)別的延遲,一般都需要使用實(shí)時(shí)鏈路同時(shí)生產(chǎn)。使用 Hudi 就可以進(jìn)行準(zhǔn)實(shí)時(shí)快照的構(gòu)建,并提供兼容的查詢。
統(tǒng)一的實(shí)現(xiàn),主要是選用了 Flink 引擎作為流批一體的計(jì)算引擎,在整體 Hudi 數(shù)據(jù)湖的生產(chǎn)中進(jìn)行應(yīng)用。
通過 Hudi 數(shù)據(jù)湖架構(gòu)建設(shè)的數(shù)據(jù)鏈路如下所示:

快手在通過 Hudi 數(shù)據(jù)湖架構(gòu)建設(shè)新的數(shù)據(jù)鏈路中,遇到了許多問題。下面,介紹一下快手在建設(shè)數(shù)據(jù)湖過程中遇到的 5 個(gè)重要問題以及具體的解決方案。
1、數(shù)據(jù)攝入的瓶頸
問題描述
快手的數(shù)據(jù)鏈路都是基于 Flink 生產(chǎn)的,其 Hudi On Flink 架構(gòu)如下圖所示。

采用上述架構(gòu)進(jìn)行數(shù)據(jù)生產(chǎn)時(shí)會(huì)遇到性能瓶頸。由于寫入多分區(qū)的數(shù)據(jù)時(shí)會(huì)通過 BucketAssigner 來進(jìn)行數(shù)據(jù)分發(fā),再使用 BucketWriter 實(shí)現(xiàn)緩存寫入,那么,當(dāng) BucketWriter 之間數(shù)據(jù)不均衡時(shí),寫入會(huì)頻繁觸發(fā)溢寫。而當(dāng)溢寫發(fā)生時(shí),又會(huì)產(chǎn)生背壓。另外,在提交數(shù)據(jù)時(shí),由于 BucketWriter 與 Flink 快照進(jìn)行了綁定,所以 Flink 快照無法實(shí)現(xiàn)整點(diǎn)觸發(fā)。
解決方案
為了解決上述提到的寫入瓶頸問題,快手優(yōu)化了寫入邏輯,主要應(yīng)用于增量數(shù)據(jù)的同步鏈路。首先,優(yōu)化寫入模式以提升性能。Flink 寫入方式從緩存寫入修改為流式寫入。寫入數(shù)據(jù)時(shí)不需要緩存,而是直接落盤,并且支持單生產(chǎn)者多消費(fèi)者的模式,每一個(gè)分區(qū)文件都可以并行寫入。這樣,可以提高 CPU 的使用率。其次,在攝入的過程中對(duì)分發(fā)邏輯進(jìn)行了優(yōu)化,實(shí)現(xiàn)了一個(gè)動(dòng)態(tài)感知的模塊。該模塊用于統(tǒng)計(jì)數(shù)據(jù)流量,均衡分發(fā)數(shù)據(jù)到寫入節(jié)點(diǎn),從而保證了各分區(qū)之間的數(shù)據(jù)均衡,來避免某個(gè)寫入節(jié)點(diǎn)受到過大的數(shù)據(jù)壓力。
為了實(shí)現(xiàn)數(shù)據(jù)的整點(diǎn)提交,快手實(shí)現(xiàn)了自動(dòng)分區(qū)發(fā)布功能。根據(jù)數(shù)據(jù)的時(shí)間戳生成了分區(qū)時(shí)間,并且在攝入過程中實(shí)時(shí)上傳數(shù)據(jù)的輪轉(zhuǎn)的時(shí)間。在中心協(xié)調(diào)器里面實(shí)現(xiàn)了一個(gè)判斷邏輯,如果所有的節(jié)點(diǎn)均已完成輪轉(zhuǎn),則進(jìn)行快照的觸發(fā),完成最終的數(shù)據(jù)提交和分區(qū)的同步,來實(shí)現(xiàn)整點(diǎn)級(jí)的分區(qū)發(fā)布。

在上述架構(gòu)中,算子可以進(jìn)行橫向擴(kuò)展,整體吞吐量比社區(qū)版本提升 10 倍以上,并且能將文件控制在需要的大小(例如:256M)左右。
2、無法使用數(shù)據(jù)時(shí)間進(jìn)行快照查詢
問題描述

在準(zhǔn)實(shí)時(shí)的數(shù)據(jù)鏈路上,需要使用 Hudi 的 Time Travel 功能來實(shí)現(xiàn)快照查詢。但是,在 SQL 查詢是使用 Timeline 的時(shí)間點(diǎn)來進(jìn)行定位的,而 Timeline 的時(shí)間與數(shù)據(jù)時(shí)間不同,且具體的 Timeline 的提交時(shí)間在存儲(chǔ)時(shí)無法準(zhǔn)確感知。
解決方案
快手在 Hudi 的 Time Travel 功能上增加了一個(gè)時(shí)間版本的元信息。每次寫入時(shí),會(huì)通過數(shù)據(jù)的時(shí)間字段來計(jì)算數(shù)據(jù)的版本號(hào)。與分區(qū)發(fā)布過程相同,會(huì)實(shí)時(shí)上傳版本的輪轉(zhuǎn)時(shí)間。在中心協(xié)調(diào)器判斷是否所有分區(qū)已經(jīng)完成了輪轉(zhuǎn),以快照觸發(fā)。

由于在提交時(shí)存儲(chǔ)快照的數(shù)據(jù)版本信息,在查詢時(shí),SQL 可以直接使用版本信息來進(jìn)行查詢。在構(gòu)建輸入快照的過程中間,會(huì)讀取 TimeTravel 的提交信息。這樣,通過判斷數(shù)據(jù)版本信息是否小于等于 SQL 中指定的時(shí)間戳的版本號(hào)來構(gòu)建增量快照,實(shí)現(xiàn)某一個(gè)時(shí)間點(diǎn)的快照查詢。
3、Flink On Hudi 的更新瓶頸
問題描述
在使用 Flink 引擎生產(chǎn) Hudi 表的過程中,更新是存在一定的瓶頸的。主要體現(xiàn)在,對(duì) Hudi 的不同操作使用的資源是錯(cuò)配的。比如,寫入操作的寫入內(nèi)存一般就是攝入的緩存大小。而對(duì)于合并操作,合并過程會(huì)根據(jù)增量數(shù)據(jù)的數(shù)據(jù)量來決定 compaction 所需要的內(nèi)存,一般情況下,這個(gè)內(nèi)存占用量是大于緩存空間的。清理操作中,在構(gòu)建 FileSystemView 對(duì)象時(shí),所占用的內(nèi)存比較大。
然后,混合操作會(huì)影響增量寫入的穩(wěn)定性。比如合并過程中,并發(fā)度無法進(jìn)行擴(kuò)展,會(huì)導(dǎo)致運(yùn)行時(shí)間長(zhǎng),進(jìn)而導(dǎo)致快照產(chǎn)生時(shí)間延遲(因?yàn)榭煺沼|發(fā)是需要水位(watermark)下推),甚至?xí)?dǎo)致任務(wù)超時(shí)。清理的時(shí)候如果遇到異常,也會(huì)導(dǎo)致任務(wù)的失敗。因此,操作之間的資源復(fù)用對(duì)操作的執(zhí)行進(jìn)度會(huì)有影響。

解決方案
解決問題的主要工作是將操作進(jìn)行分離,支持多種操作并行執(zhí)行來構(gòu)建 Hudi 的數(shù)據(jù)源。

首先,Hudi 支持多種索引。在快手活動(dòng)期間,會(huì)選用 State Index,配置 TTL 來保存一定時(shí)間內(nèi)的快照結(jié)果。在需要并發(fā)寫入的任務(wù)中,由于任務(wù)的索引需要相互感知,因此會(huì)選用 Bucket Index,可以有效控制寫入緩存資源的占用,而且可以在外部進(jìn)行操作的運(yùn)行管理。在表創(chuàng)建時(shí),觸發(fā)生成和合并的調(diào)度作業(yè);表下線時(shí),自動(dòng)下線掛載的調(diào)度作業(yè)。
此外,多個(gè)數(shù)據(jù)源的寫入還需要實(shí)現(xiàn)并發(fā)控制。首先,對(duì)元數(shù)據(jù)進(jìn)行加鎖,來避免對(duì)元數(shù)據(jù)的并發(fā)操作。然后,在支持并發(fā)寫入的過程中,支持了關(guān)聯(lián)引用,為合并的功能增加了占位邏輯,后續(xù)的寫入基于占位合并的 instant,在合并完成之后,基于合并的寫入也是對(duì)外可見的,這種方式可以提高寫入的吞吐量。此外,也支持開啟 OCC 控制的并發(fā)寫入,在寫入相同的 base 文件時(shí)進(jìn)行并發(fā)檢查,支持沖突的失敗回滾或者合并處理,以防止數(shù)據(jù)結(jié)果不正確的現(xiàn)象出現(xiàn)。
4、多任務(wù)合并能力不足
問題描述
多任務(wù)合并寬表時(shí),在多任務(wù)并發(fā)運(yùn)行寫入的場(chǎng)景中,進(jìn)行索引選擇時(shí),需要考慮到索引數(shù)據(jù)需要被多任務(wù)感知到的因素。若是采用外部索引,則使用成本較高。若是采用 Bucket Index 作為索引,則進(jìn)行多任務(wù)并發(fā)寫入時(shí),性能上有優(yōu)勢(shì)。但是,存在一個(gè)合并時(shí)的瓶頸,這是由于一般情況下,Bucket Index 使用文件大小來控制計(jì)算桶數(shù),而合并時(shí)使用的資源又取決于增量文件的數(shù)據(jù)大小,這會(huì)導(dǎo)致合并任務(wù)的并發(fā)度較小,無法滿足合并時(shí)的性能需求。在合并的過程中,存在讀取和更新的操作,若是過程中出現(xiàn)了溢寫現(xiàn)象,則整個(gè)合并速度會(huì)很慢。

在 Schema 的使用方面。不同的寫入任務(wù)會(huì)使用不同的 Schema,而合并時(shí)依賴于寫入任務(wù)的 Schema 來生成合并的 Schema 以生成最終的 Base 文件。但是,一些自動(dòng)上線的寫入任務(wù)無法被合并作業(yè)感知到。
解決方案
快手實(shí)現(xiàn)的并發(fā)寫入作業(yè)支持了邏輯分桶和多類型合并的能力。邏輯分桶是在物理桶的組織之上進(jìn)行了二次哈希,本質(zhì)上是將物理桶分成了更多的桶,在需要寫入時(shí),要先進(jìn)行桶的排序,并創(chuàng)建對(duì)應(yīng)的索引文件。在后續(xù)的合并過程中,基于邏輯桶來生成合并計(jì)劃,每一個(gè)邏輯桶都會(huì)生成一個(gè)對(duì)應(yīng)的算子實(shí)例。
合并時(shí),作業(yè)先讀取物理桶的數(shù)據(jù),然后通過索引 seek 到對(duì)應(yīng)邏輯桶的數(shù)據(jù)位置,之后進(jìn)行可選擇類型的合并。一般地,在寫入并發(fā)已知的情況下,sortMerge 是更快的。在元數(shù)據(jù)中,增加了合并 Schema 的配置,在寫入時(shí)將 Schema 更新到數(shù)據(jù)源,從而實(shí)現(xiàn)了合并Schema的自動(dòng)擴(kuò)展和合并任務(wù)的自動(dòng)感知生產(chǎn)。

5、Hudi 生產(chǎn)保障困難
問題描述
Hudi 作為一個(gè)較復(fù)雜的架構(gòu),從生產(chǎn)到運(yùn)維有比較豐富的支持,比如不同模塊有對(duì)應(yīng)的配置類,支持 metrics 系統(tǒng)、支持 Hudi-Cli 查詢?cè)畔ⅰ?/span>

但是,這些功能支持在實(shí)際生產(chǎn)環(huán)境的使用效果并不好。首先,Hudi 的配置過多,使用起來很麻煩。其次,在監(jiān)控報(bào)警和異常中斷的能力上,作為線上服務(wù)略顯不足,需要進(jìn)行自定義強(qiáng)化。因此,快手針對(duì)線上需要,加強(qiáng)了生產(chǎn)的保障能力。
解決方案
① 配置精簡(jiǎn)。只需要設(shè)置一些基本參數(shù)(SQL 方式),比如任務(wù)類型、保存時(shí)間、提交間隔,就可以自動(dòng)推導(dǎo)生成其他的配置參數(shù)。

② 一致性保障。在一致性保障方面,快手自定義實(shí)現(xiàn)了 PreCommit 檢驗(yàn)?zāi)K,比如,會(huì)對(duì)增量數(shù)據(jù)的輸入輸出條數(shù)進(jìn)行校驗(yàn),同時(shí)數(shù)據(jù)塊的寫入情況在提交之前也會(huì)做校驗(yàn)。
③ 穩(wěn)定保障。在穩(wěn)定性方面,快手完善了不同算子的 metrics,包括耗時(shí)和數(shù)據(jù)處理情況,流量吞吐情況等。同時(shí)還監(jiān)控著分區(qū)分布,耗時(shí),任務(wù)的指標(biāo)監(jiān)控來共同保障生產(chǎn)的穩(wěn)定性。
三、快手的實(shí)踐案例
快手?jǐn)?shù)據(jù)湖在構(gòu)建完成之后,在一些具體的業(yè)務(wù)上進(jìn)行了應(yīng)用,取得了明顯的收益。

下面使用四個(gè)比較典型的案例,來對(duì)比基于數(shù)據(jù)湖建設(shè)的新數(shù)據(jù)鏈路與舊數(shù)據(jù)鏈路之間的差異。
最早的時(shí)候,核心數(shù)倉的 DWD 層生成是需要多層的離線調(diào)度任務(wù)來進(jìn)行。在切換到 Hudi 之后,就可以準(zhǔn)實(shí)時(shí)的生成 DWD 層的動(dòng)態(tài)更新數(shù)據(jù)。此外,還可以根據(jù)需要來選擇性的進(jìn)行數(shù)據(jù)重分布的操作來對(duì)接下來的讀取操作進(jìn)行提效。這個(gè)場(chǎng)景上,快手將離線鏈路升級(jí)成了準(zhǔn)實(shí)時(shí)的鏈路,在計(jì)算資源上持平,時(shí)效上有 50% 以上的提升。
數(shù)據(jù)在應(yīng)用過程中,還會(huì)有活動(dòng)數(shù)據(jù)快照查詢的需求。早期,這些數(shù)據(jù)若要使用多個(gè)數(shù)據(jù)源進(jìn)行生產(chǎn)和查詢,需要用到離線鏈路,這種方式的時(shí)效性很差,一般會(huì)達(dá)到小時(shí)級(jí)。如果想使用實(shí)時(shí)鏈路加速,需要比較復(fù)雜的處理過程。切換到 Hudi 之后,將離線快照的更新時(shí)效從小時(shí)級(jí)縮短到了分鐘級(jí),整體時(shí)效達(dá)到十多分鐘左右,而且計(jì)算資源比以前節(jié)省了 15%。在后續(xù)的查詢過程中,可以對(duì)離線桶的快照數(shù)據(jù)進(jìn)行關(guān)聯(lián)查詢,最終生成需要的活動(dòng)的結(jié)果數(shù)據(jù)。

生產(chǎn)過程中的數(shù)據(jù)留存場(chǎng)景中,在生產(chǎn)留存數(shù)據(jù)時(shí),最早的生產(chǎn)流程是需要用多天的日活數(shù)據(jù)去重復(fù)地生產(chǎn)標(biāo)簽表,然后與日活的數(shù)據(jù) JOIN 生產(chǎn)到最終日活表內(nèi),這個(gè)過程涉及多次的日活表的讀取和全量數(shù)據(jù)的回收。切換至 Hudi 后,通過將日活留存狀態(tài)直接更新至留存表,數(shù)據(jù)生產(chǎn)模式從多次的合并生產(chǎn)轉(zhuǎn)換成了單表生產(chǎn)。在使用當(dāng)日的日活數(shù)據(jù)去更新留存表,之前的數(shù)據(jù)是已經(jīng)存在的,只需要將日活數(shù)據(jù)去更新留存狀態(tài)即可。這個(gè)場(chǎng)景下,鏈路的生產(chǎn)方式上的優(yōu)化,整體計(jì)算資源由于全量讀寫到增量寫入的轉(zhuǎn)換,根據(jù)需求進(jìn)行定時(shí)合并,時(shí)效上也有 50% 的提升。

在特征的生產(chǎn)場(chǎng)景內(nèi),上游的多個(gè)數(shù)據(jù)生產(chǎn)點(diǎn)合并生產(chǎn)出寬表結(jié)果。這個(gè)場(chǎng)景下,原來是使用 HBase 來進(jìn)行合并,在 HBase 中進(jìn)行行存,在外部用 Hbase 進(jìn)行生產(chǎn)有一個(gè)額外的維護(hù)成本,并且需要使用到 HBase 的導(dǎo)入導(dǎo)出工具來進(jìn)行離線操作,生產(chǎn)鏈路較長(zhǎng)。切換至 Hudi 后,可以直接復(fù)用已有的生產(chǎn)鏈路邏輯,然后直接對(duì)攝入到 Hudi 表內(nèi)的數(shù)據(jù)基于并發(fā)合并能力構(gòu)建一張寬表。這個(gè)過程中,也可以保證數(shù)據(jù)是有序的。例如,讀取時(shí)可以根據(jù)數(shù)據(jù)需求,比如上游增量寫入數(shù)據(jù)源的數(shù)據(jù)已經(jīng)就緒了,下游就可以直接進(jìn)行導(dǎo)入。可以理解為實(shí)時(shí)感知,可以提升整體的處理時(shí)效。
可以的觀察結(jié)果為,目前的離線分批的合并升級(jí)成了準(zhǔn)實(shí)時(shí)單表合并,對(duì)時(shí)效升級(jí)明顯。首先,處理鏈路的計(jì)算時(shí)間縮短,最長(zhǎng)時(shí)間節(jié)省 5 個(gè)小時(shí);在鏈路計(jì)算過程中所占用的臨時(shí)存儲(chǔ)空間和計(jì)算資源得到了節(jié)省,同時(shí),也節(jié)省了 HBase 集群所需要的開銷。
四、快手的發(fā)展規(guī)劃
快手?jǐn)?shù)據(jù)湖當(dāng)前還有一些待優(yōu)化的工作。首先,缺少完善的元數(shù)據(jù)和數(shù)據(jù)管理服務(wù)。在查詢模式上,由于不支持實(shí)時(shí)表,也還沒有達(dá)到離線和實(shí)時(shí)查詢的統(tǒng)一。此外,當(dāng)前快手?jǐn)?shù)據(jù)湖生產(chǎn)方式還沒有做到無感知的兼容,所以主要在新的場(chǎng)景上使用,總體的使用率占比不高。
未來快手?jǐn)?shù)據(jù)湖將作為統(tǒng)一存儲(chǔ)的技術(shù)組件,支持更多類型的數(shù)據(jù)以及拓寬數(shù)據(jù)湖支持的表類型,例如實(shí)現(xiàn)類似于實(shí)時(shí)表的定義。完善數(shù)據(jù)的管理來提升數(shù)據(jù)組織的合理性。實(shí)現(xiàn)兼容已有鏈路的輕量切換方案。將實(shí)現(xiàn)流批一體的數(shù)據(jù)生產(chǎn),提供高效統(tǒng)一的查詢能力作為數(shù)據(jù)湖建設(shè)的最終愿景。
五、問答環(huán)節(jié)
Q1:詳細(xì)介紹一下加鎖的部分。
A1:其實(shí)社區(qū)本身也支持 OCC 機(jī)制,其實(shí)現(xiàn)邏輯是,在寫入過程中對(duì)元數(shù)據(jù)進(jìn)行加鎖,在最終的提交階段,會(huì)對(duì)寫入文件做 CAS 操作,通過對(duì)比來發(fā)現(xiàn)沖突。若是發(fā)現(xiàn)兩個(gè)寫入任務(wù)寫入同一個(gè) base 文件的情況,即表示寫入任務(wù)之間存在沖突,會(huì)將后寫入的作業(yè)標(biāo)記為失敗。快手也使用了這個(gè)機(jī)制來避免并發(fā)寫入時(shí),寫入同一個(gè) base 文件,影響最終結(jié)果。
快手在這個(gè)基礎(chǔ)之上,對(duì)合并和更新過程做了一個(gè)優(yōu)化。比如說,F(xiàn)link On Hudi 架構(gòu)的準(zhǔn)實(shí)時(shí)寫入過程中,若按照社區(qū)的寫入邏輯,將合并和更新識(shí)別為兩種操作,會(huì)導(dǎo)致合并阻塞了整個(gè)寫入操作,或者合并操作一直無法完成,會(huì)導(dǎo)致讀取數(shù)據(jù)源的效率低。經(jīng)過快手的優(yōu)化后,寫入過程中,寫入效率不會(huì)受到 Compaction 結(jié)果的影響。因?yàn)椋焓謺?huì)使用之前合并執(zhí)行計(jì)劃的基于時(shí)間戳的占位符來進(jìn)行寫入操作。社區(qū)的默認(rèn)邏輯是基于 baseTime 來生成數(shù)據(jù),這使得合并的結(jié)果和寫入數(shù)據(jù)之間可能存在沖突。若是采用占位的合并計(jì)劃的 Instance 與已有的數(shù)據(jù)不會(huì)產(chǎn)生沖突。但是需要保證合并操作必須完成,否則后面的寫入數(shù)據(jù)是不可見的,通過這種方式,可以提升整體的增量寫入的吞吐量。
Q2:Compaction 資源錯(cuò)配的問題怎么解決?異步的 Compaction 是否有相關(guān)的經(jīng)驗(yàn)可以分享一下?
A2:資源錯(cuò)配的主要原因是寫入操作需要的資源和并發(fā)資源不一致。若是將寫入過程各個(gè)操作分離開,那么可以根據(jù)寫入任務(wù)的流量情況來調(diào)整寫入資源。快手目前仍然采用默認(rèn)的配置,寫入操作的一個(gè) TaskManager 占用了 6G-8G 的內(nèi)存,其中包含了多個(gè)并發(fā)寫入的 Slot。在合并過程中,取決于需要的時(shí)效。比如說,需要整體的合并時(shí)效比較高的話,需要盡量的避免溢寫現(xiàn)象的發(fā)生,這時(shí),需要將 Compact 的內(nèi)存設(shè)置得比較大。默認(rèn)情況下,快手將合并任務(wù)調(diào)整為 4 核 10G 左右。當(dāng)有寫入數(shù)據(jù)量比較大且合并速度快的需求時(shí),則需要將內(nèi)存設(shè)置更大一點(diǎn),這樣增量數(shù)據(jù)基本上存儲(chǔ)在合并操作的內(nèi)存中。這樣,1 到 2G 的文件可以在 10 分鐘以內(nèi)處理完成。