













談談數據倉庫中的數據建模
數據建模是創建數據及其在組織或系統內的關系的概念表示的過程。維度建模是一種以用戶直觀且易于理解的方式呈現數據。它還提供高性能訪問、靈活性和可擴展性,以適應業務需求的變化。
在本文中,我們將深入概述數據建模,特別關注 Kimball 的方法。此外,還將介紹用于以用戶友好且直觀的方式呈現數據的其他技術。現代數據倉庫的一項特別有趣的技術是將數據存儲在一個寬表中,盡管這種方法可能并不適合所有查詢引擎。我們還將介紹可在數據倉庫、數據湖、數據湖屋等中使用的技術。但是,為特定用例和查詢引擎選擇適當的方法非常重要。
什么是維度建模
每個維度模型都由一個或多個具有多部鍵的表(稱為事實表)以及一組稱為維度表的表組成。每個維度表都有一個主鍵,該主鍵與事實表中多部分鍵的組成部分之一精確對應。這種獨特的結構通常稱為星型模式。在某些情況下,可以使用稱為雪花模式的更復雜的結構,其中維度表連接到較小的維度表
維度建模的好處
維度建模提供了一種實用且有效的方法來組織和分析數據,從而帶來以下好處:
- 業務用戶簡單易懂。
- 改進的查詢性能可加快數據檢索速度。
- 靈活性和可擴展性,以適應不斷變化的業務需求。
- 確保跨多個來源的數據一致性和集成。
- 增強的用戶采用率和自助服務分析。
既然我們已經討論了維度建模是什么以及它給組織帶來的價值,那么讓我們探討一下如何有效地利用它。
數據和維度建模方法
雖然我打算主要關注 Kimball 的方法,但在深入探討之前,讓我們簡要介紹一下其他一些流行的技術。
Inmon方法論
Inmon 建議在數據倉庫中使用標準化數據模型。該方法支持數據集市的創建。這些數據集市是數據倉庫的較小的專門子集,可滿足特定業務領域或用戶組的需求。這些旨在為特定業務職能或部門提供更加定制和高效的數據訪問體驗。
數據拱頂
Data Vault 是一種專注于可擴展性、靈活性和可追溯性的建模方法。它由三個核心組件組成:Hub、Link 和 Satellite。
中心表
中心表是所有不同實體的集合。例如,帳戶中心將包括帳戶、account_ID、load_date 和 src_name。這使我們能夠跟蹤記錄加載時的原始位置,以及是否需要從業務密鑰生成的代理密鑰。
鏈接表
鏈接表在中心表之間建立關系并捕獲不同實體之間的關聯。它們包含相關中心表的外鍵,從而能夠創建多對多關系。
衛星表
衛星表存儲有關中心的描述信息,提供附加上下文和屬性。它們包括歷史數據、審計信息以及與特定時間點相關的其他相關屬性。
Data Vault 的設計允許靈活且可擴展的數據倉庫架構。它促進數據可追溯性、可審計性和歷史跟蹤。這使得它適合數據集成和敏捷性至關重要的場景,例如在高度監管的行業或快速變化的業務環境中。
單個大表
大表將數據存儲在一張寬表中。使用一張大表或非規范化表可以簡化查詢、提高性能并簡化數據分析。它消除了復雜連接的需要,簡化了數據集成,并且在某些情況下可能是有益的。然而,它可能會導致冗余、數據完整性挑戰以及維護復雜性增加。在選擇單個大表之前請考慮具體要求。


AND交易AS (
SELECT 1000001 AS order_id, TIMESTAMP ( '2017-12-18 15:02:00' ) AS order_time,
STRUCT( 65401 AS id, 'John Doe' AS name, 'Norway' AS location) AS customer,
[
STRUCT( 'xxx123456' AS sku, 3 AS數量, 1.3 AS價格),
STRUCT( 'xxx535522' AS sku, 6 AS數量, 500.4 AS價格),
STRUCT( 'xxx762222' AS sku, 4 AS數量, 123.6 AS價格)
] AS訂單
UNION ALL
SELECT 1000002 , TIMESTAMP ( '2017-12-16 11:34:00' ),
STRUCT( 74682 , 'Jane Smith' , '波蘭' ) AS客戶,
[
STRUCT( 'xxx635354' , 4 , 345.7 ),
STRUCT( 'xxx828822' , 2 , 9.5 )
] AS訂單
)從交易中選擇 *
對于一張寬表,我們不需要連接表。我們可以只用一張表來匯總數據并進行分析。此方法可提高 BigQuery 的性能。

從交易 t、UNNEST (t.orders)中選擇customer.name、sum (a.quantity)作為按 customer.name分組。
Kimball方法論
Kimball 方法非常強調創建稱為數據倉庫的集中式數據存儲庫。該數據倉庫作為單一事實來源,以一致且結構化的方式集成和存儲來自各種業務系統的數據。
該方法為設計、開發和實施數據倉庫系統提供了一套全面的指南和最佳實踐。它非常重視創建維度數據模型,并優先考慮簡單性、靈活性和易用性。現在,讓我們深入研究 Kimball 方法的關鍵原則和組成部分。
實體模型到維度模型
在我們的數據倉庫中,數據源通常位于實體模型中,這些實體模型被規范化為多個表,其中包含應用程序的業務邏輯。在這種情況下,這可能具有挑戰性,因為需要了解表和底層業務邏輯之間的依賴關系。創建分析報告或生成統計數據通常需要連接多個表。

要創建維度模型,數據需要經過提取、轉換和加載 (ETL) 過程,將其非規范化為星型模式或雪花模式。此過程中的關鍵活動包括識別事實表和維度表以及定義粒度。粒度決定了事實表中存儲的詳細程度。例如,可以每小時或每天聚合交易。

假設我們有一家銷售自行車和自行車配件的公司。在這種情況下,我們有以下信息:
- 交易
- 商店
- 客戶
- 產品
根據我們的業務知識,我們知道我們需要收集有關銷售量、一段時間內的數量以及按地區、客戶和產品細分的信息。有了這些信息,我們就可以設計我們的數據模型。交易表將充當我們的事實表,商店、客戶和產品表將充當維度表。
事實表
事實表通常表示業務事件或事務,并包括與該事件關聯的度量或度量。這些指標可以包含各種數據點,例如銷售額、銷售數量、客戶互動、網站點擊或任何其他可提供業務績效洞察的可衡量數據。事實表還包括與維度表建立關系的外鍵列。

事實表設計的最佳實踐是將所有外鍵放在表的頂部,然后進行測量。
事實表類型
- 事務事實表提供了最低級別的粒度,因為一行代表事務系統中的一條記錄。數據每天或實時刷新。
- 定期快照事實表捕獲某個時間點(例如月底)事實表的快照。
- 累積快照事實表總結了流程開始和結束之間的可預測步驟中發生的測量事件。
- 無事實事實表保存有關發生的事件的信息,無需任何指標。
維度表
維度表是維度建模中的一種表,包含描述性屬性,例如有關產品、其類別和類型的信息。維度表為事實表中存儲的定量數據提供上下文和視角。
維度表包含一個唯一鍵,用于標識表中的每條記錄,稱為代理鍵。該表可以包含業務鍵,該業務鍵是來自源系統的鍵。一個好的做法是生成代理鍵而不是使用業務鍵。
創建代理鍵有多種方法:
- 哈希:可以使用 MD5、SHA256 等哈希函數(例如 md5(key_1, key_2, key_3) )生成代理鍵。
- 遞增:使用始終遞增的數字生成的代理鍵(例如 row_number()、identity)。
- 連接:通過連接唯一鍵列生成的代理鍵(例如 concat(key_1, key_2, key_3) )。
- -Unique generated:使用生成唯一標識符的函數(例如GENERATE_UUID())生成的代理鍵
選擇的方法取決于用于處理和存儲數據的引擎。它會影響查詢數據的性能。
維度表通常包含層次結構。
a) 例如,父子層次結構可用于表示員工與其經理之間的關系。
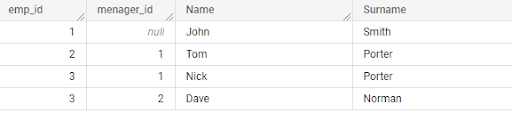
b) 屬性之間的層次關系。例如,時間維度可能具有年、季、月、日等屬性,形成層次結構。

維度表的類型
一致維度:
一致維度是可以被多個事實表使用的維度。例如,區域表可以由不同的事實表使用。
退化維度:
當屬性存儲在事實表而不是維度表中時,就會出現退化維度。例如,可以在事實表中找到交易號。
垃圾維度:
該屬性包含不適合現有維度表的無意義屬性,或者是表示各種狀態組合的標志和二進制值的組合。
同一扮演維度:
同一維度鍵在事實表中包含多個外鍵。例如,日期維度可以引用事實表中的不同日期,例如創建日期、訂單日期和交貨日期。
靜態維度:
靜態維度是通常永不改變的維度。它可以從參考數據加載,無需更新。一個例子是公司的分支機構列表。
橋接表:
當事實表和維度表之間存在一對多關系時,將使用橋接表。
緩慢變化的維度
緩慢變化的維度(SCD)是維度建模中的一個概念。它處理維度表中維度屬性隨時間的變化。SCD 提供了一種機制,用于在業務實體發展及其屬性變化時維護維度表中的歷史和當前數據。SCD 有六種類型,但最流行的三種是:
- SCD 類型 0:在此類型中,僅將新記錄導入到維度表中,而不進行任何更新。
- SCD 類型 1:在此類型中,將新記錄導入維度表,并更新現有記錄。
- SCD 類型 2:在此類型中,導入新記錄,并為更改的屬性創建具有新值的新記錄。
例如,當 John Smith 搬到另一個城市時,我們使用 SCD Type 2 來保存與倫敦相關的交易信息。在本例中,我們創建一條新記錄并更新前一條記錄。因此,歷史報告將保留他在倫敦購買的信息。


MERGE INTO client AS tgt
USING (
SELECT
Client_id,
Name,
Surname,
City
GETDATE() AS ValidFrom
' 20199 -01 -01 ' AS ValidTo
from client_stg
) AS src
ON (tgt.Clinet_id = src.Clinet_id AND tgt.iscurrent = 1 )匹配后更新設置 tgt.iscurrent = 0 , ValidTo = GETDATE(),當 不匹配時
INSERT (Client_id, name, Surname, City, ValidFrom, ValidTo, iscurrent)
VALUES (Client_id, name, Surname, City, ValidFrom, ValidTo, 1 );這就是當我們將新值和以前的值保留在不同的列中時 SCD 3 的外觀。

星型模式與雪花型模式
設計數據倉庫最流行的方法是使用星型模式或雪花模式。星型模式具有事實表和與事實表相關的維度表。在星型模式中,存在事實表和與事實表直接相關的維度表。另一方面,雪花模式由事實表、與事實表相關的維度表以及與這些維度表相關的附加維度組成。

這兩種設計之間的主要區別在于它們的標準化方法。星型模式保持數據非規范化,而雪花模式確保規范化。星型模式旨在提高查詢性能。雪花模式是專門為處理大維度的更新而定制的。如果您在更新大量維度表時遇到挑戰,請考慮轉換到雪花模式。
數據加載策略
在我們的數據倉庫、數據湖和數據湖屋中,我們可以有各種加載策略,例如:
全量加載:全量加載策略是將源系統中的所有數據加載到數據倉庫中。此策略通常用于出現性能問題或缺少可以通知行修改的列的情況。
Incremental Load:增量加載策略涉及僅加載自上次數據加載以來的新數據。如果源系統中的行無法更改,我們可以根據唯一標識符或創建日期僅加載新記錄。我們需要定義一個“水印”,用于選擇新行。
Delta Load:Delta加載策略側重于僅加載自上次加載以來已更改或增量的記錄。它與增量加載的不同之處在于它專門針對增量更改而不是所有新記錄。Delta 加載策略在處理大量數據更改時非常高效,并可顯著減少所需的處理時間和資源。
加載數據的最常見策略是先填充維度表,然后填充事實表。這里的順序很重要,因為我們需要使用事實表中維度表的主鍵來創建表之間的關系。有一個例外,當我們需要在維度表之前加載事實表時,這種技術名稱就是延遲到達維度。
在這種技術中,我們可以在維度表中創建代理鍵,并在填充事實表后通過 ETL 過程更新它。





















