萬字詳解大數據平臺異地多機房架構實踐
01 背景
隨著B站業務的高速發展,業務數據的生產速度變得越來越快,離線集群規模快速膨脹,既有機房內的機位急劇消耗,在可預見的不久的將來會達到機房容量上限,阻塞業務的發展。因此,如何解決單機房容量瓶頸成為了我們亟待解決的問題。
目前,針對機房容量問題的解決方案業界主要有以下兩種:
1) 集群整體搬遷至更高容量的機房(scale up) 。該方案是一種縱向擴容方案,即將現有集群搬遷至容量更大的機房,從而提供集群擴展的空間。現實中,集群遷移一般不能影響業務的發展,即保證不停機,因此,遷移過程中需要兩個規模相近的集群做全量遷移,或者需要一個具有一定規模的過渡集群,分批次遷移;對于大規模(tens of thousands)集群來說,遷移的經濟成本巨大;另外,遷移后的新機房會有再次達到容量上限的風險。
2) 多機房方案(scale out) ,即一個機房容量有限,擴展為多個機房,同時對既有架構進行一定的改造,保證用戶視角仍像是一個機房。此舉可依據業務需要,采用靈活的方式增量擴容,從而一定程度上避免容量冗余問題。然而,該方案會存在跨機房數據交互,而機房間網絡帶寬一般也存在瓶頸;同時,網絡的抖動或斷網可能造成跨機房業務出現異常。因此,該方案需要考慮/解決網絡帶寬不足及網絡抖動/斷網問題帶來的影響,技術成本較集群整體搬遷方案要高。
就我們目前自建機房的情況來看,中短期暫無清退既有機房(全部搬遷至新機房)的計劃,從長期來看也會存在多個機房;另外,比起方案2的技術成本,我們更難接受方案1的經濟成本和容量風險。因此,方案2是我們解決機房容量問題首選方案。
02 多機房方案
2.1 面臨的問題
上文提到多機房方案面臨帶寬等網絡問題,多機房方案的設計受其制約。
帶寬瓶頸
離線場景主要是批處理場景,是對海量歷史數據進行離線分析/處理的場景,該場景對延遲不敏感,但由于其處理數據量巨大對網絡帶寬等資源消耗較大;另外,生產場景中作業數量一般較多且執行時間不受控,若兩個機房的主機只是簡單疊加在一起做為一個集群來用,可能會存在大量的跨機房互訪,產生大量的隨機流量打滿有限的跨機房帶寬, 此時除離線自身受影響外, 還可能對其它跨機房業務造成影響 。因此,如何防止跨機房隨機流量打滿跨機房帶寬是多機房方案要解決的一個重要問題。
網絡抖動&連通性
跨城網絡會受供應商服務質量影響(或施工影響)造成抖動(或斷網), 與機房內CLOS架構的網絡質量相比會低很多。若兩個機房的主機當做為一個集群來用,如圖1 HDFS示例,當網絡抖動時,不但會導致跨機房讀寫延遲增加,還會影響DN的IBR等過程,造成服務性能和穩定性下降;當網絡出現嚴重問題造成斷網時,會導致異地機房數據不可用,還會導致異地機房DN失聯,造成大量Block低于預期副本數,觸發NN大量補副本等問題。因此,如何降低網絡抖動及網絡連通性問題帶來的影響是多機房方案要解決的另外一個不可忽視的問題。
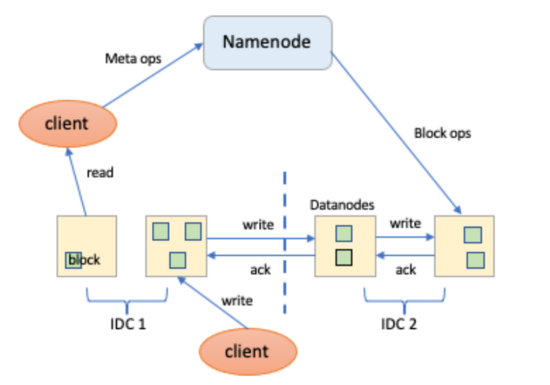
圖1 HDFS 架構
2.2 設計選型
如上所述,多機房的主要矛盾是跨機房網絡帶寬不足、穩定性差與離線海量數據處理任務高效產出之間的矛盾,解決該主要矛盾面臨的核心問題是如何減少跨機房帶寬的消耗,以及如何降低網絡穩定性問題帶來的影響。
經調研,單元化架構是為解決多地多中心問題演進而來的部署架構,其中,單元是指一個能完成所有業務操作的自包含集合,在這個集合中包含了業務所需的所有服務,以及分配給這個單元的數據 [1-2] 。按照單元化的思路,在多機房場景中,每個機房可以作為一個單元,每個單元內提供作業執行所需要的全部服務以及數據,保證作業在單元內完成,從而解決上述多機房面臨的核心問題;單元化拆分后任何一個單元的故障只會影響局部,不會造成整體癱瘓;在選定采用單元化思想來設計了多機房方案之后, 多機房方案的核心問題就限定在了如何決定作業與數據放置,以及如何讓作業訪問距離近的數據,來降低跨機房帶寬的消耗及網絡穩定性問題帶來的影響。
帶著上面的核心問題,我們調研了業界大廠的多機房解決方案 [3-7] 。這些方案在計算層面為防止Shuffle等中間結果數據造成跨機房流量,每個機房均獨立部署了計算集群,在該層面均符合單元化思想;但在存儲存面存在分歧,如圖2所示,依據數據和異地機房的數據副本是否屬于同一組NameSpace (NS),大體可以分為多機房單集群方案和多機房多集群方案。
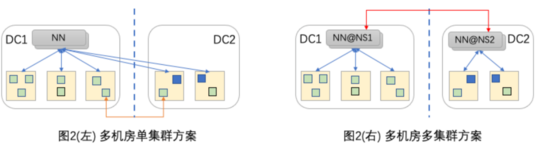
圖2 多機房方案分類
[3-5] 采用了多機房單集群方案,該方案中采用Block級的數據副本,數據和數據副本同屬于一組NS,無數據一致性問題,但因NS只能在其中一個機房,無法有效應對網絡連通性問題,且Namenode異地副本管理(BlockPlacementPolicy)和相關工具(Mover, Balancer等)改造成本較大,另外該方案可擴展性也受單集群規模制約。
[6-7] 采用了多機房多集群方案,整體符合單元化思想。其中 [6] 應用于云梯遷機房場景,它首先在同機房中通過Fast Copy將文件元數據分離到兩個NS,然后再通過同NS內DN到DN的跨機房Copy將數據復制到遠程機房,該方案在一定程度上可以有效應對跨機房網絡風險,但因存在兩次copy時效性上難以保障,另外也存在異地的數據節點,因此本質上也存在多機房單集群方案改造成本和擴展性問題;[7] 阿里Yugong(Yugong: Geo-Distributed Data and Job Placement at Scale)基于MetaStore針對分區表場景,通過調整作業放置和數據放置來降低跨機房帶寬的消耗;如圖3所示,計算A、B存在跨機房訪問行為,通過調整(互換)計算A、B的放置位置可以有效減少跨機房訪問流量;計算C、D同時跨機房消費同一份數據3, 若通過數據復制的方式將數據3復制到機房2, 讓C、D依賴數據3在機房2中的副本,則可以減少一次跨機房消費數據流量。但對于我們采用開源大數據架構的場景來說,需要改造(分屬于多個子部門的)多種計算框架來適配其基于MetaStore的數據副本管理和數據路由,改造實施成本較大;另外,其基于MetaStore的設計只能解決表(SQL)場景的多機房問題,也不能覆蓋我們對非表場景提供多機房支持的需求;不過,該方案中通過“作業放置-數據復制”來解決帶寬瓶頸問題的思路非常值得我們借鑒。
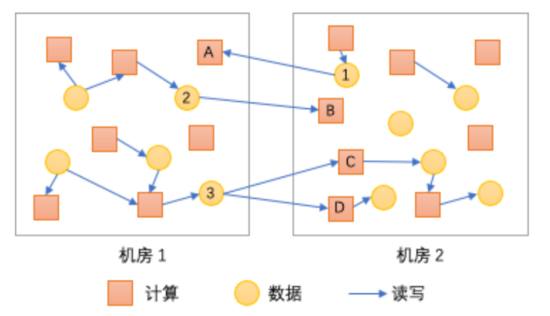
圖3 任務跨機房隨機分布
綜上,我們參考Yugong“作業放置-數據復制”的思路,采用有限的單元化思想設計多機房方案;如圖4所示,每個機房部署一套獨立的完整的集群(YARN&HDFS),為作業在一個機房內執行提供最基本的服務保障,從而在跨機房網絡出現異常時,降低影響范圍;同時,通過合理的作業放置和有計劃的數據復制,消除跨機房隨機訪問流量及跨機房數據重復消費等問題,來達到降低帶寬消耗的目的;另外,我們結合內部的基礎設施情況,以及滿足表和非表兩種場景的需求,我們選擇了基于擴展HDFS Router(RBF)多掛載點來實現數據副本管理和數據路由功能,并通過Client IP感知自動將數據請求路由至較近的機房;還有為解決數據復制帶來的一致性問題引入了Version服務等,圖中涉及組件將在實現部分進行介紹。
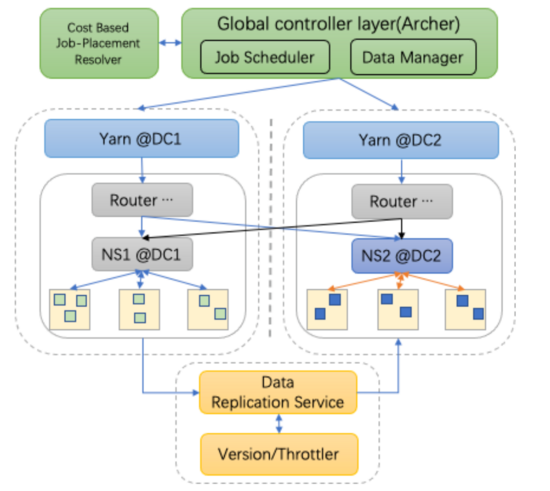
圖4 多機房架構
2.3 總體流程
圖5展示了以Hive作業為例的在上述設計思路下的總體流程,圖中綠色模塊為我們新增或改造組件。首先,通過周期性的分析作業間依賴關系及依賴的數據大小,確定作業放置位置信息并進行持久化(DataManager用于管理作業放置信息等),B站的作業調度平臺(Archer和Airflow)提交作業時,先獲取作業的放置機房信息,并檢查預期放置機房的數據副本是否Ready,若Ready則提交作業,否則,阻塞提交,等待數據復制服務完成復制數據;其次,作業調度提交后,拉起Hive/Spark Driver生成可執行計劃,向預期DC的Yarn集群提交Job,等待拉起Job,同時我們在Yarn層面也做了改造,基于Yarn Federation架構,實現了基于app tag和隊列的機房調度策略,這個在下文也會介紹; 最后,被拉起的作業請求HDFS數據,HDFS Router依據Client IP所屬的DC信息,自動將請求路由到距離Client較近的數據復本所在機房的NS, 并將結果返回Client。
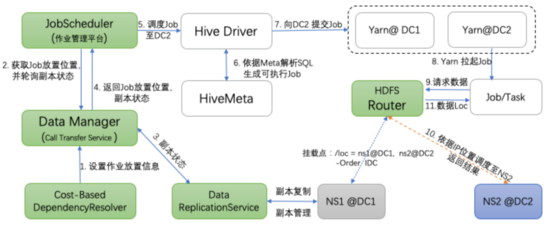
圖5 多機房作業調度執行流程
多機房核心流程包括作業放置、數據復制、數據路由、版本控制、數據限流、跨機房流量分析等幾個階段,上述Job提交流程并未完全涵蓋,下文實現部分我們將對所有階段進行詳細說明。
03 多機房方案實現
下面章節會對多機房核心環節進行介紹, 包括作業放置、數據復制、數據路由,以及為保障數據副本一致性引入的數據版本服務和帶寬控制的限流服務,并引入事后的跨機房流量分析工具,用以發現預期外的跨機房行為指導調整。
3.1 作業放置
a. 依賴分析
大數據離線場景,作業數量多,作業之間依賴復雜。比如,大數據離線報表處理業務,從數據采集,清洗,到各個層級的報表的匯總運算,到最后數據導出到外部業務系統,一個完整的業務流程,可能涉及到成百上千個相互交叉依賴關聯的作業。就作業放置來說,對復雜作業依賴的管理和分析工作至關重要, 而如我們自研的調度平臺Archer等DAG工作流類調度系統,自身具有較強的作業依賴管理能力,因此,我們僅需要聚焦作業依賴分析以確定要遷移的業務。
我們依據作業間依賴關系及需要處理的數據大小,基于社區發現(Community Detection)探索了一種考慮跨機房帶寬代價的作業關系鏈劃分模型。該模型首先依據調度系統管理的作業間的依賴關系構建DAG圖, 然后從DAG圖中圈出相對高內聚(相對比較閉環)的業務子單元,最后結合相互依賴的子單元間的數據量選擇出的可以遷移的子單元;如圖6所示的簡單DAG, 我們假定圖中正方形代表計算,圓形代表數據,圓的大小代表數據大小,則我們以虛線作為劃分邊界將DAG分成兩個子單元,分別調度到兩個機房,則可滿足數據傳輸代價小的目標。當然,整個過程除了考慮跨機房數據訪問代價外,還需要考慮機房計算和存儲資源是否可以滿足需求。
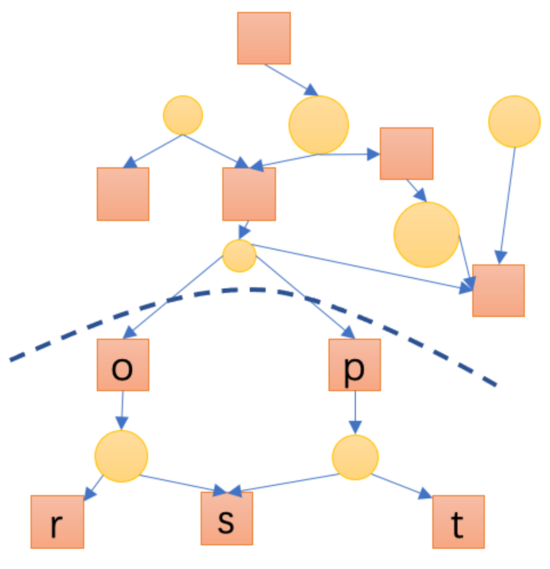
圖6 依賴關系劃分
一般而言,實際生產中的ETL等周期性調度作業相對比較穩定, 不會頻繁發生變化,甚至部分作業不會出現變化,因此,確定Job放置在那個機房的的依賴分析過程可以以天或周為單位周期性的離線計算產生;另外,從管理的角度來看,公司一般會有多個相對比較獨立的業務部門,每個業務部門又會垂直的劃分出多個業務子單元,業務內的作業間聯系緊密程度遠大于業務之間;同時,業務(單元)也是資源管理單元,以及多機房落地實施過程中的溝通單元;因此,在實踐中往往是以業務單元為邊界進行依賴劃分。
b. 作業放置
我們的生產環境中存在多個作業調度平臺,如Archer、Airflow等平臺,將Job放置在那個機房的信息維護在任一平臺都不能涵蓋所有作業, 因此我們引入DataManager服務(在整個體系中的位置見圖4)作為接入層,用來管理作業放置的IDC信息和需要進行數據復制的路徑信息,Archer/Airflow等調度平臺通過對接該服務來接入多機房體系;下面以自研DAG調度平臺Archer為例描述工作流程如下:
前置工作:Archer 通過DataManager接口設置作業的放置位置信息,以及依賴數據的路徑pattern、范圍、生命周期等信息。
Archer訪問DataManager確定作業放置的IDC信息,并為作業選擇符合IDC作業配置信息。
Archer詢問Job在該IDC的數據是否Ready,若Ready,則設置app tag為該IDC并通過Yarn RMProxy向計算集群提供作業;否則,掛起并等待數據Ready后嘗試重新提交;其中數據是否Ready,是通過DataManager轉發請求至數據復制服務得到。
另外由于我們的業務部門和Yarn上的一級隊列做了一一映射,所以一旦某個業務部門的數據整體遷移到新機房后,我們會在RMProxy中設置該部門對應的queue mapping策略到新機房,這樣無論是從調度平臺還是其他用戶客戶端提交的Job即使沒有接入DataManager也能正確路由到新機房的計算集群,同時回收老機房的計算和存儲資源。
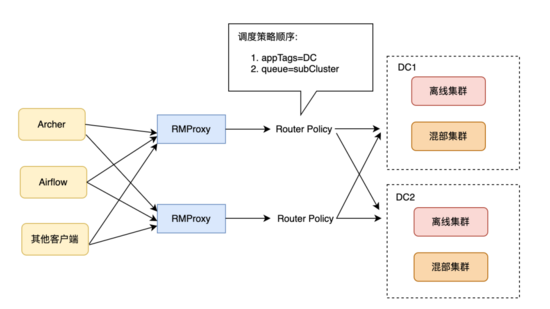
圖7 Yarn調度策略
3.2 數據復制
a. 復制服務
作業放置會將有聯系緊密的Job放在一個機房,以減少跨機房訪問,進而減少跨機房網絡帶寬消耗;對于無法消除的跨機房依賴,特別是異地機房使用頻次大于1的數據,需要異地機房也存在數據副本,以降低網絡帶寬消耗;因此,我們提供了數據復制服務來進行副本復制。
數據復制服務基于社區提供的DistCp工具實現, 并在正確性、原子性、冪等性、傳輸效率等方面作了增強, 同時支持流控、多租戶傳輸優先級(高優作業能得到更多跨機房流量和計算資源配額),副本生命周期管理等功能。
b. 復制流程
數據復制主要針對有規律的周期性調度作業進行,這類作業一般比較固定,通過對作業歷史運行記錄進行分析即可推測出作業的輸入輸出情況,包括數據路徑和使用的數據范圍(防止長時間跨度回刷任務大量復制)等信息。因此,當確定好待遷移的作業后,可以提煉出數據路徑規則(rules),并持久化到DataManager的規則庫中(規則庫會隨作業放置的變化而進行周期性更新)。
然后,針對不同的場景使用規則庫進行路徑抽取,下面以Hive表場景為例描述數據復制流程,如圖8所示, 首先收集Hive MetaStore的掛載表/分區相關的Event信息至Kafka服務,然后通過實時Flink任務清洗出符合上述規則庫中規則的路徑,當檢測到熱點表的新分區生成后,交由數據復制服務(DRS)進行傳輸,生成異地機房副本,DRS本質上是一個DistCp作業的管理服務,在傳輸完成后由數據復制服務持久化副本信息(包括路徑、版本、TTL等),以對副本數據進行全生命周期管理(刪除過期的跨機房副本,釋放存儲空間),目前B站線上有100+張Hive熱點表路徑設置了跨機房副本策略。
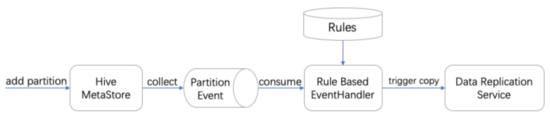
圖8 數據復制流程
上述復制流程采用自動發現主動復制的策略,可以快速捕獲并準備數據副本,經過統計在我們的生產中數據副本延遲的PT90可以控制在1min以內, PT99 在5min以內,可以有效滿足離線場景的業務需要;然而,上述自動發現主動復制的策略,可以有效解決增量數據副本的問題,但對于待遷移作業來說,可能還依賴較長一段時間的存量數據,針對該問題,我們除了采用提前啟動復制流程的方式準備存量數據外,還針對需要快速遷移的場景引入了基于Snapshot的數據遷移策略進行初始復制,因Snapshot為社區成熟技術不再綴述。
3.3 數據路由
上小節介紹的數據拷貝后雙機房均會存在某路徑的數據副本,當作業放置到IDC后如何定位到正確的數據是數據路由服務要解決的關鍵問題;
我們在 《HDFS在B站的探索和實踐》 中提到的基于HDFS Router的多掛載點實現的MergeFs的基礎上,實現了鏡像掛載點來實現數據路由功能。為方便描述,我們約定原始數據為主數據, 傳輸到異地機房的數據為副本數據(也稱為鏡像數據,該數據只允許讀取和刪除),并且約定鏡像掛載點中第一掛載點為主數據,之后的掛載點為副本數據(理論上可以擴展多個機房),為了在路由層面做到對用戶透明,我們在鏡像掛載點的處理邏輯中,增加了請求來源的IP位置感知功能,該功能能過獲取請求來源IP的位置信息,判斷請求來源的DC并將請求路由到相應的DC的HDFS。如圖9示例所示,若數據請求來自DC1, 則Router將數據請求重定向到DC1的HDFS集群,來自DC2則定向到DC2的HDFS集群(圖中同種顏色線條標識請求路徑)。
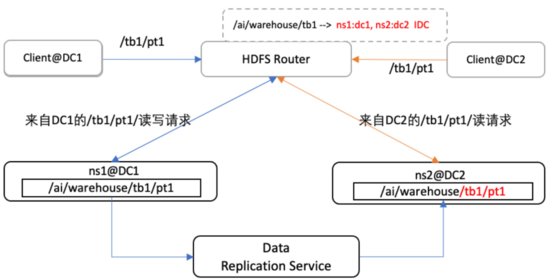
圖9 基于Router的數據路由
為了降低跨機房帶寬的消耗,原則上,我們規定所有對數據的讀取操作,都只允許在本地機房(即Client所在機房), 否則先拷貝到本地機房。但特殊情況下,如圖10所示,若Data Replication Service發生異常短時間無法修復或ns長時間異常時,則我們允許降級為跨機房限流讀(副本未ready情況, 超過一定的時間未在目標機房讀取到數據,則降級),限流部分在后面章節進行詳細介紹。
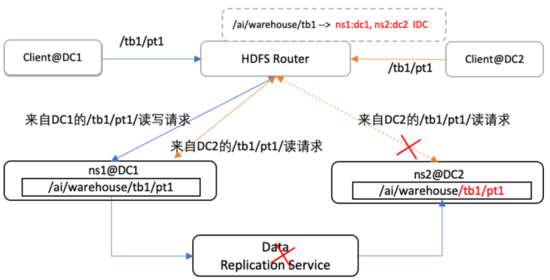
圖10 數據路由容錯
另外 ,由于歷史原因,在我們的生產中存在一種特殊的臨時庫,用于管理用戶SQL作業中的創建的短生命周期的臨時表(Temporary table,七天自動清理),該類臨時表表名不固定(例如一些ETL作業會在臨時表名上加上日期后綴),也就造成了表類路徑不固定;針對該類路徑不固定的情況,無法使用上述鏡像掛載點進行管理,因此, 我們引入一種名叫IDC_FOLLOW的多掛載點,用于掛載多個機房中的臨時庫路徑;當讀寫臨時表時,會依據Client所在的DC選擇DC內HDFS NS掛載路徑來存取數據,從而解決臨時表跨機房流量的問題。
3.4 版本服務
分布式場景下,通過數據復制方式產生副本,不可避免會導致一致性問題,因此,多機房存在數據副本時,除了涉及上述路由選擇問題外,還必須考慮數據版本一致性問題,我們通過引入版本服務(Version)解決該問題;為了簡化版本服務設計, 針對大數據離線場景寫少讀多的特性,我們依據CAP理論對鏡像掛載點的實現做了一定的取舍,規定了對主數據可以進行所有操作,副本數據只允許讀/刪操作;在這個前提下,我們引入了基于HDFS Editlog的版本服務,如圖11所示,該服務以觀察者的身份監控向HDFS JournalNodes(JN)訂閱路徑的變更行為,并以操作ID(transaction id)來標識數據版本;若訂閱的路徑中數據發生了變化,則會通過editlog傳導到JN,再由JN通知Version進行版本更新;因所有對數據的變更操作都會記錄editlog,因此,不論SQL場景和非SQL場景,只要數據存在變化均可被版本服務捕捉到,從而可以有效保證數據的一致性。

圖11 數據版本工作流程
上文2.3節總體流程所描述的提交作業時,當獲取到作業預期的放置機房后,檢查依賴數據是否Ready的工作也包括版本檢查工作;當作業需要副本數據時,會通過數據傳輸服務檢查已傳輸的數據副本的版本與版本服務中訂閱的最新版本是否一致,若一致允許作業提交使用數據副本;否則,作業臨時阻塞,待傳輸服務更新副本數據后,則允許提交作業;若超過一定的時間未在目標機房讀取到數據,則降級為讀取主數據。
3.5 限流服務
我們的場景下跨機房帶寬有限(約4Tbps),并且和在線服務、實時服務等對延遲更敏感的服務共用帶寬,為防止離線跨機房流量(特別是計劃外的跨機流量)打滿帶寬影響在線業務, 我們引入了基于令牌桶的限流服務。
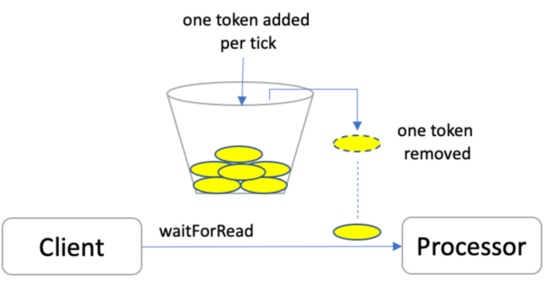
圖12 令牌桶
令牌桶限流的核心思想為當進行某操作需要令牌時,需要從令牌桶中取出相應的令牌數,如果獲取到令牌則繼續操作,否則阻塞,用完之后不用放回。基于該思想我們設計了全局中心限流服務,我們在HDFS DistributedFileSystem類基礎上,實現了具有讀寫限流功能的ThrottledDistributedFileSystem,當用戶使用該類去讀寫HDFS的文件時,ThrottledDistributedFileSystem會根據RBF返回的LocatedBlock中的client IDC信息和Block IDC信息,判斷此次讀寫流量是否會跨機房,如果是會先嘗試向ThrottleService發送申請跨機房帶寬請求(Token),申請到Token后,再進行后續的HDFS讀寫,如果申請的流量用完后,再向ThrottleService申請新的帶寬Token;除利用令牌桶固有的特性外,我們在令牌桶的基礎上實現了隊列優先級和加權公平特性,限流服務的隊列優先級和調度系統中的作業優先級也做一一映射,來保障多租戶情況下重要服務可以優先獲取到Token;在穩定性方面,為了降低限流服務的壓力,我們設置每個Token代表相對較大的流量單元,來降低Token的獲取次數過多帶來的性能影響;為防止限流服務宕機導致作業阻塞,我們增加了降級為本地固定帶寬的策略,同時隨著計算引擎持續接入限流服務,服務本身的穩定性和請求水位成為瓶頸(單機100K+ qps),我們通過水平擴展服務的方式增強了限流服務的性能。
3.6 跨機房流量分析
隨著多機房項目的逐漸推進,跨機房流量也日漸增長,高峰時刻偶爾會打滿專線帶寬。為了對跨機房帶寬流量進行有效管控,我們需要了解哪些作業貢獻了最多的跨機房流量,從而進行針對性治理。從離線作業的角度看,網絡流量來源主要有三塊:
- 從上游讀取數據
- 作業執行過程中不同Executor/Task之間shuffle數據
- 寫數據到下游表
在B站多機房的場景中,因為采用單元化架構每機房均存在獨立Yarn的集群,作業不會跨機房運行也就不存在跨機房Shuffle數據的情況,因此只需考慮讀寫HDFS文件過程中產生的跨機房流量即可,而讀寫HDFS文件產生的跨機房流量又可以分為計劃內流量和非計劃內流量兩大類:
- 計劃內流量:3.2 小節所述數據復制服務進行數據副本復制產生的流量,我們稱為計劃內流量, 該部分數據大概率會被多次使用
- 非計劃內流量:即非數據復制服務產生的數據流量,單次(或多次)使用,主要來源有以下幾種可能:a. 計劃內的調度任務發生長時間跨度的歷史回刷,依賴的數據副本已過期銷毀b. (漏遷/錯遷/新增等)放置位置不合理的周期性調度任務,可以通過優化作業放置消除c. Adhoc查詢,突發流量, 單次(或多次)使用,臨時生產需求,無法預知需要的數據,無法預先進行處理
流量分析工具
在實際生產過程中,非計劃內流量不可避免,為了對跨機房流量進行有效管控,我們引入了跨機房流量分析工具,我們在引擎端和DN端做了以下改造:
- 引擎端: 在初始化HDFS Client時將作業JobId注入到DFSClient的ClientName中
- DataNode: 在DataXceiver中埋點,從ClientName中解析出JobId,并按JobId和client ip網段合并讀寫流量,每30s輸出統計結果到流量日志中
我們將每臺DN上的跨機房流量日志進行實時收集,通過Flink匯總到ClickHouse上,然后聚合分析得出每個時間段的跨機房流量作業Top10,方便對跨機房流量進行治理(包括重新放置、緊急查殺、作業優化等)。
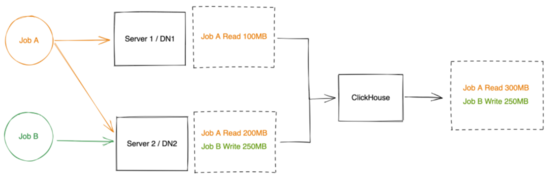
圖13 流量日志收集鏈路
以下是我們跨機房流量分析的監控面板:
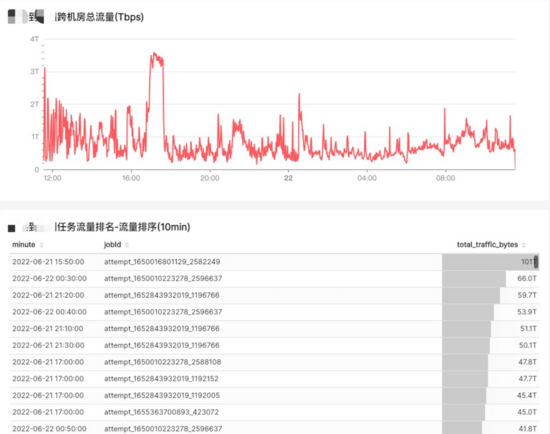
圖14 跨機房流量分析
Adhoc流量治理&優化
對于Adhoc類型的非計劃內流量,因為其隨機性,本文所述多機房體系中“數據復制-作業放置-數據路由”方式不適用;因此,我們采用一些其它的優化手段, 比如通過運行時SQL Scan掃描出依賴的數據大小、位置信息,以節省多機房帶寬為最主要目標,結合集群的實際負載情況,決定SQL調度哪個機房,比如:
- 訪問單張表:作業調度至數據所在機房
- 訪問多張表多表在同機房, 作業調度至數據所在機房多表在不同機房, 作業調度至數據量較大的表所在機房;較小表限流讀,或者阻塞通知拷貝服務拷貝
另外, 對于Presto這種有多源查詢能力的引擎,我們利用其Connector多源查詢功能力將每個機房視為一個Connector,在多表訪問場景中將子查詢下推發送到遠端機房進行處理,以減少垮機房流量帶寬,詳情見 《Persto在B站的實踐》 5.2節多機房架構。
04 小結&展望
本文描述了B站離線多機房方案,該方案已平穩上線運行半年以上,遷移數據量近300PB,作業數占集群所有作業數的1/3。從實踐的結果來看該方案在很大程度上解決了跨機房網絡帶寬不足、穩定性差與離線任務高效產出之間的矛盾。鑒于當前部分大數據關鍵組件的單元化進程,在抗網絡連通性風險方面的能力還有較大的提升空間,后續我們將不斷的推單元化進程,進一步降低網絡問題的影響范圍,同時賦予部分高優化作業“雙活”的能力。
另外隨著新機房的持續擴容(老機房無法擴容,新增節點都會部署在新機房),我們也需要持續遷移更多作業到新機房,為了提高遷移的推進速度,需要盡量減少對上下游業務方的依賴(如:請求業務方協助對子業務進行劃分和梳理),因此,我們需要實現更智能更自動化的待遷移數據和作業的自動劃分流程,進一步強化使用社區發現(Community Detection)算法將DAG能自動劃分成多個內聚性較高的子集/社區,按照社區粒度進行遷移的工作。