Kafka分區數據Skew導致Watermark放賴怎么辦?
原創拋出疑無路?
有一種非常..非常...常見的痛苦是Kafka分區數據Skew,由于某一個分區數據緩慢導致整個作業無法事件驅動計算。From @孫金城的知識星球用戶,如下:

示例說明比如我們有一個Kafka的Topic,有2個分區,如下數據:
S001,1, 2020-06-13 09:58:00
S001,1, 2020-06-13 09:58:01
S001,2, 2020-06-13 09:58:02
S001,3, 2020-06-13 09:58:03
S001,4, 2020-06-13 09:58:04
S001,5, 2020-06-13 09:58:05
S001,6, 2020-06-13 09:58:06
S001,7, 2020-06-13 09:58:07
S001,8, 2020-06-13 09:58:08
S001,9, 2020-06-13 09:58:09
S001,10, 2020-06-13 09:58:10
S001,11, 2020-06-13 09:58:11
S001,12, 2020-06-13 09:58:12
S001,13, 2020-06-13 09:58:13
S001,14, 2020-06-13 09:58:14
S001,15, 2020-06-13 09:58:15
S001,16, 2020-06-13 09:58:16
S001,17, 2020-06-13 09:58:17
S001,18, 2020-06-13 09:58:18
S001,19, 2020-06-13 09:58:19
S001,20, 2020-06-13 09:58:20
S001,21, 2020-06-13 09:58:21 // 這條數據在第一個分區,其他數據在第二個分區。
S001,22, 2020-06-13 09:58:22
S001,23, 2020-06-13 09:58:23
S001,24, 2020-06-13 09:58:24
S001,25, 2020-06-13 09:58:25
S001,26, 2020-06-13 09:58:26
S001,27, 2020-06-13 09:58:27
S001,28, 2020-06-13 09:58:28
S001,29, 2020-06-13 09:58:29
S001,30, 2020-06-13 09:58:30
S001,31, 2020-06-13 09:58:31
S001,32, 2020-06-13 09:58:32
S001,33, 2020-06-13 09:58:33
S001,34, 2020-06-13 09:58:34
S001,35, 2020-06-13 09:58:35
S001,36, 2020-06-13 09:58:36
S001,37, 2020-06-13 09:58:37
S001,38, 2020-06-13 09:58:38
S001,39, 2020-06-13 09:58:39
我們利用自定義Partitioner的方式,讓第21條數據到第一個分區,其他的在第二個分區。這時候,如果業務需求是一個5秒鐘的窗口。
那么,目前Flink-1.10默認只能觸發4個窗口計算,也就是從22條數據到39條數據都不會觸發計算了。利用本篇提及的解決方案可以完成
7個窗口的觸發(全部窗口)。
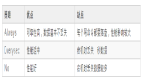
不考慮Idle情況,計算結果 如下:

考慮Idle情況,計算結果 如下:

再現又一村!
【Flink 1.10 】這又是一個知道1秒鐘,不知道坐地哭的情況。問題的本質是目前生成Watermark的機制是min(partition1, partition2,..,partitionN), 所以就出現了木桶效應,也就是用戶描述的情況,怎么辦呢?修改代碼.... 還是那句話,看這個系列的朋友都是來看怎么快速解決問題的,所以咱們不啰嗦,直接看解決步驟:
- 仿照下面的代碼開發一個`StreamSource`, 放到`org.apache.flink.streaming.api.operators`包下面,與你的業務代碼一起打包:
https://github.com/sunjincheng121/know_how_know_why/blob/master/QA/v110/discover-idle-sources/src/main/java/org/apache/flink/streaming/api/operators/StreamSource.java

注意上面添加了一個配置`idleTimeout`的配置項,這個配置下默認`-1`,也就是不生效,那么只要你配置了這個數值,指定的時間不來數據Flink系統就認為這個Partition沒數據了,那么計算Watermark的時候就不考慮他了,等他有數據再把他列入計算Watermark的范疇。
- 在寫作業的時候配置`source.idle.timeout.ms`參數,如下:

OK,上面兩個步驟就解決了這個問題。如你遇到classloader問題,我說的是如果,那么把下面默認值進行修改。

【說明】如上解決方案適用 Flink 1.10 及之前版本 DataStream 和SQL flink planner開發(我想以后也一樣,因為flink planner 逐步被blink planner替代)。
對 Flink blink planner SQL (1.9+) 可以添加`table.exec.source.idle-timeout`。 對于Flink 1.11及之后的DataStrem可以利用`WatermarkStrategy`進行設置,最終參考1.11發布之后的文檔。
前進一小步?
如果是已經遇到這個問題的朋友,那么按照上面兩步應該可以解決問題。如果你沒有遇到這個問題,想自己體驗一下,那么可以clone我的git:
https://github.com/sunjincheng121/know_how_know_why/tree/master/QA/v110/discover-idle-sources
把這個項目拉到本地,按照README.md 體驗一把:
https://github.com/sunjincheng121/know_how_know_why/blob/master/QA/v110/discover-idle-sources/src/main/java/qa/README.md

如果你上面操作還遇到了困難,那也不用著急,關注我《Apache Flink知其然,知其所以然》視頻課程,里面會有視頻演示(這個系列文章保持簡單,只說How,不細說Why)
Flink 的鍋?...
關于這個問題社區也在不斷的做努力,感興趣的朋友可以參閱 FLIP-27&FLIP-126。當然對于flink planner(old)目前看只能用本篇提到的方案進行解決,這里也建議大家盡早升級到 blink planner。
作者介紹
孫金城,51CTO社區編輯,Apache Flink PMC 成員,Apache Beam Committer,Apache IoTDB PMC 成員,ALC Beijing 成員,Apache ShenYu 導師,Apache 軟件基金會成員。關注技術領域流計算和時序數據存儲。