













為邊緣編程成功值得借鑒的六個經驗
譯文?譯者 | 布加迪
審校 | 孫淑娟
鑒于許多組織紛紛獲得邊緣計算在延遲、靈活性、成本和性能等方面帶來的好處,邊緣計算正在迅猛發展。IDC估計,2022年全球在邊緣硬件、軟件和服務上的支出將超過1760億美元,比上一年猛增14.8%,到2025年將達到2740億美元。因此,您的開發人員很可能現正在開發邊緣應用程序,或者在不遠的將來會開發。

在積極試水之前,有幾個方面需要考慮。我是一名企業架構師,與多家開發組織有過合作,在創建邊緣應用程序方面可以給出幾個重要的經驗。牢記這些經驗可以幫助您避免令人沮喪的結果,并確保您充分發揮邊緣計算的優勢。
經驗一:質疑自己的想法
開發人員常常將創建邊緣應用程序視為它們就像是面向數據中心或云的應用程序。但是邊緣是一種不同的范式,需要不同的方法來編寫代碼,還需要深思熟慮地選擇哪些應用程序適合邊緣。
大多數開發人員習慣于少量服務器擁有大量計算資源的集中式計算環境。但邊緣計算顛覆了這種情形,將數量適中的資源分布在不同位置的多臺服務器上。這會影響任何一種邊緣工作負載的可擴展性。比如說,使用大量內存的應用程序面對成百上千個邊緣實例時可能無法很好地擴展。出于這個原因,大多數邊緣應用程序將是專門為邊緣構建的,而不是從現有數據中心或云部署環境“平移”。
您需要批判性地思考邊緣架構如何影響自己的應用程序、哪些應用程序將受益于這種分布式方法。將邏輯引入到數據所在的位置通常比較容易。因此,如果數據比較分散,或需要訪問大型集中式數據存儲,基于云的方法可能很明智。但當應用程序使用邊緣處生成的數據時,比如來自在線用戶的請求/響應、Cookie和標頭,這時候邊緣計算就能真正大放異彩。
經驗二:不要忽視基本面

雖然將代碼分發到邊緣可以改善延遲和可擴展性,但不會一下子運行得更快。低效的代碼在邊緣同樣很低效。如前所述,邊緣的每個接入點都將比典型的集中式計算環境更受資源的限制,尤其是在無服務器邊緣環境下。在為邊緣編寫代碼時,優化效率對于充分利用這種架構至關重要。
當將功能推送到邊緣相對快速和容易時,您仍然需要運用通常用于任何代碼的同樣的妥善管理流程。這包括良好的變更管理流程、將代碼存儲在源代碼控制系統中,以及使用代碼審查來評估代碼質量。
經驗三:重新考慮可擴展性
如果使用邊緣,您是“橫向擴展”而不是“縱向擴展”。因此,您需要開發代碼以適應每個請求的約束,而不是從每個服務器的約束方面來考慮。這包括內存使用、CPU 周期和每個請求的時間等方面的約束。約束會因您使用的邊緣平臺而異,因此了解這些約束并相應地設計代碼很重要。
通常,您需要使用每個操作所需的最小數據集進行操作。比如說,如果您在邊緣進行 A/B測試,您可能只想存儲您在處理的特定請求或頁面所需的那部分數據,而不是整個規則集。如果是基于位置的體驗,您只需要輕量級查詢中該邊緣實例為特定的州或地區所提供的數據,而不是所有地區的數據。
經驗四:為確保可靠性編寫代碼
確保邊緣應用程序的可靠性對于提供積極的用戶體驗而言至關重要。確保您的質量保證(QA)計劃包含測試邊緣代碼。添加適當的錯誤處理對于確保代碼能夠從容地處理錯誤也很重要,包括規劃和測試出現問題時的回退行為。比如說,如果您的代碼超出了平臺施加的限制,您希望創建回退機制,以便退回到一些默認內容,這樣用戶不會收到影響體驗的出錯消息。
執行分布式負載測試是證實應用程序具有可擴展性的好方法。一旦您部署了代碼,繼續監控平臺,以確保不會超出CPU和內存方面的限制,并跟蹤任何錯誤。
經驗五:優化性能
邊緣計算的主要好處是將數據和計算資源移到靠近用戶的位置,從而大幅縮短延遲。當您在成百上千個接入點(PoP)進行擴展時,創建輕量級高效代碼對于獲得這個優點至關重要。完成一項功能所需的數據也應該在邊緣處。開發需要從集中式數據存儲獲取數據的代碼將使邊緣帶來的延遲優點蕩然無存。
對于您可能希望用于邊緣應用程序的任何第三方代碼,同樣需要強調高效執行。一些現有的代碼庫很低效,損害性能及/或超出邊緣平臺在CPU和內存方面的限制。因此在將任何代碼合并到部署的邊緣環境之前,先仔細評估一番。
經驗六:不重新發明輪子
雖然邊緣是一種新范式,但這并不意味著必須從頭開始編寫所有代碼。大多數邊緣平臺與各種內容交付網絡(CDN)功能相集成,允許您創建自定義邏輯,以生成表示現有CDN功能(如緩存)的輸出。
構建代碼確保可重用也是一個好主意,以便代碼在邊緣和集中式計算環境中都可以執行。將核心功能抽取到不依賴瀏覽器、Node.JS或特定平臺功能的庫中,讓代碼可以“同構”,能夠在客戶端、服務器和邊緣處運行。
使用現有的開源庫是另一種避免重寫通用功能的方法。但要注意需要Node.JS或瀏覽器功能的庫。一些第三方開發人員開發與您使用的邊緣平臺集成的產品,還要考慮與他們合作,這可以節省時間和精力,同時獲得互操作性經過驗證的優點。
將經驗付諸實踐
為了說明這些最佳實踐帶來的影響,不妨考慮一個真實案例:一家組織在邊緣實施地理圍欄應用程序時遇到了困難。由于超出了平臺在CPU和內存方面的限制,該組織面臨高錯誤率。
看看該組織如何構建應用程序,他們擁有所有地理圍欄區域的數據,即900KB的JSON,存儲在每個邊緣PoP處。使用CPU密集型算法針對每個地理圍欄檢查興趣點,在接受檢查的前幾個區域中未找到興趣點時,就觸發CPU超時。
為了糾正這個問題,每個地理圍欄區域的數據都被移到了鍵值存儲(KVS)系統,每個區域存儲在一個單獨的條目中。并添加了輕量級檢查,以確定某個興趣點可能存在的“候選區域”(通常是1到3個候選區域)。僅針對候選區域執行完整的數據和CPU密集型檢查,這大大減少了CPU工作量。這些變化將錯誤率降到了可忽略不計的水平,同時縮短了初始化時間,并減少了內存使用量,如下圖所示。
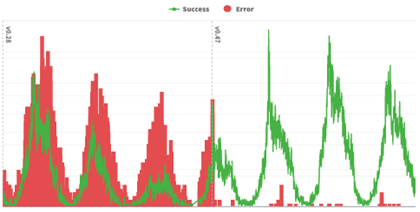
圖1:成功率和錯誤率的前后對比(請注意,成功和錯誤度量指標在不同的尺度上,因此無法直接比較)
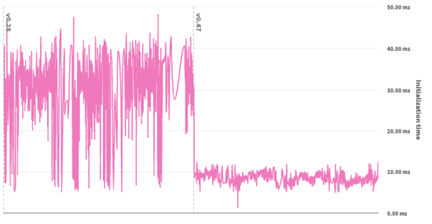
圖2:初始化時間前后對比
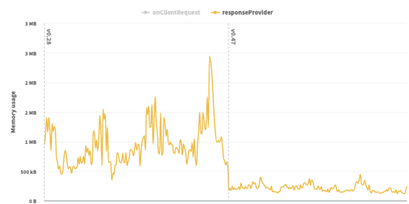
圖 3:內存使用量前后對比。(圖片來源:Akamai)
充分發揮邊緣的優勢
邊緣計算為受益于貼近用戶的應用程序提供了巨大的優勢,不僅帶來了速度和效率,還帶來了個性化用戶體驗。成功的關鍵是確保您的應用程序很適合邊緣,然后優化代碼以充分利用邊緣平臺功能,又不超出約束范圍。
如果注意我在與多家組織合作中獲得的經驗,您可以更快速地充分發揮邊緣的好處,又沒有棘手的問題。
原文標題:??Coding for the Edge: Six Lessons for Success???,作者:Josh Johnson?
















