













向量化執行引擎框架 Gluten 宣布正式開源,并亮相 Spark 技術峰會
近日舉辦的 Databricks Data & AI Summit 2022 上,來自 Intel 的陳韋廷和來自 Kyligence 的張智超共同分享了 Intel 和 Kyligence 兩家企業自 2021 年合作共建的全新開源項目「Gluten」。這也是 Gluten 首次在全球平臺上亮相,今天我們將一起通過本文進一步了解 Gluten。
Gluten 項目旨在為 Apache Spark 注入 Native Vectorized Execution 的能力,極大優化 Spark 的執行效率和成本。目前,Gluten 社區的主要參與方有 Intel、Kyligence 等。
“ Kyligence 企業級產品源自 Apache Kylin,今天,兩者在離線數據處理、即時查詢分析等方面,都深度集成了 Spark 的能力。通過 Gluten 這一開源項目,Kylin 和 Kyligence 企業級產品將有效提升 OLAP 查詢性能和執行效率,尤其是在云原生版本 Kyligence Cloud 中,將更大程度地降低整體擁有成本(TCO),提高云端數據分析的成本效率,加速大型客戶從傳統數據分析架構轉向云原生數據湖架構的進程。
——Kyligence 聯合創始人兼 CTO 李揚”
#01
為什么需要 Gluten
近年來,隨著 IO 技術的提升,尤其是 SSD 和萬兆網卡的普及,大家基于 Apache Spark 的數據負載場景遇到越來越多的 CPU 計算瓶頸,而不是傳統認知中的 IO 瓶頸。而眾所周知,基于 JVM 進行 CPU 指令的優化比較困難,因為 JVM 提供的 CPU 指令級的優化(例如 SIMD)要遠遠少于其他 Native 語言(例如 C++)。
同時,大家也發現目前開源社區已經有比較成熟的 Native Engine(例如 ClickHouse、Velox),具備了優秀的向量化執行(Vectorized Execution)能力,并被證明能夠帶來顯著的性能優勢,然而它們往往游離于 Spark 生態之外,這對已經嚴重依賴 Spark 計算框架、無法接受大量運維和遷移成本的用戶而言不夠友好。Gluten 社區希望能夠讓 Spark 用戶無需遷移,就能享受這些成熟的 Native Engine 帶來的性能優勢。
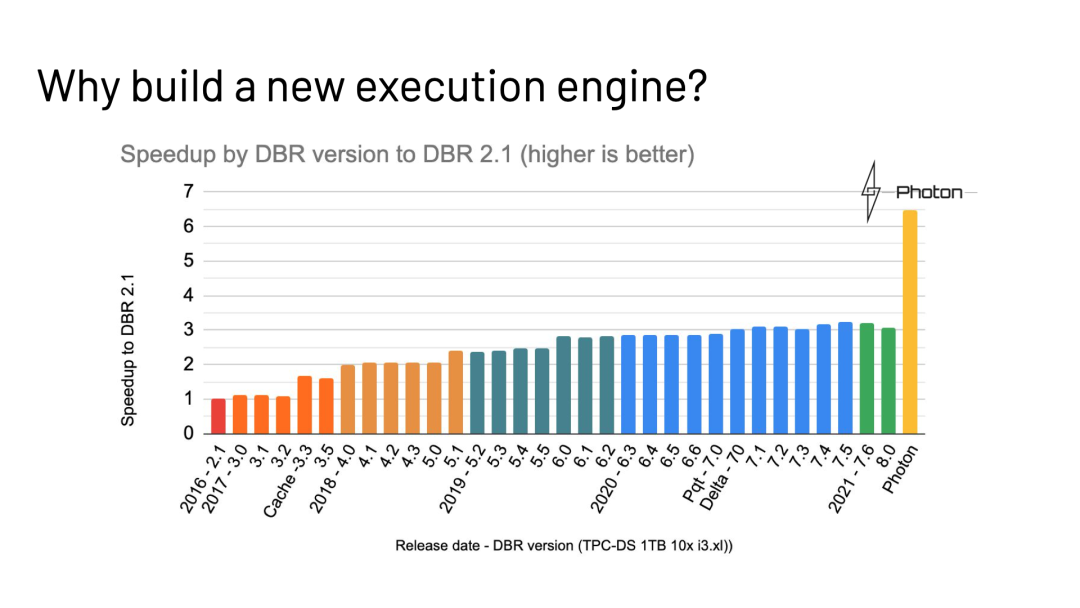
無獨有偶,前不久 Databricks 在 SIGMOD 2022 發表了一篇關于 Photon 項目的文章“Photon: A Fast Query Engine for Lakehouse Systems”[1],文章詳細描述了 Databricks 如何在 Apache Spark 中集成 Photon 這一 Native 子系統,通過向量化執行等方面的優化,為 Apache Spark 帶來執行性能的大幅提升。Gluten 項目在 Photon 公開前就已獨立地立項和啟動,不過我們看到在實現思路和加速效果上兩者具有一定的相似性。
下圖來自 Databricks 公開的演講材料[2],從圖中可以看出引入 Native Vectorized 引擎(Photon)的性能收益,勝過過去 5 年來所有性能優化的總和。而性能的提升又可以帶來 Spark 使用體驗的提升和 IT 成本的下降,這一點在企業用戶動輒使用成百上千臺服務器用來運行 Spark 作業的今天,是非常誘人的進步。目前 Photon 并不開源,因此 Gluten 項目可以很好地填補行業在這里的空白。
#02
Gluten 項目是什么?
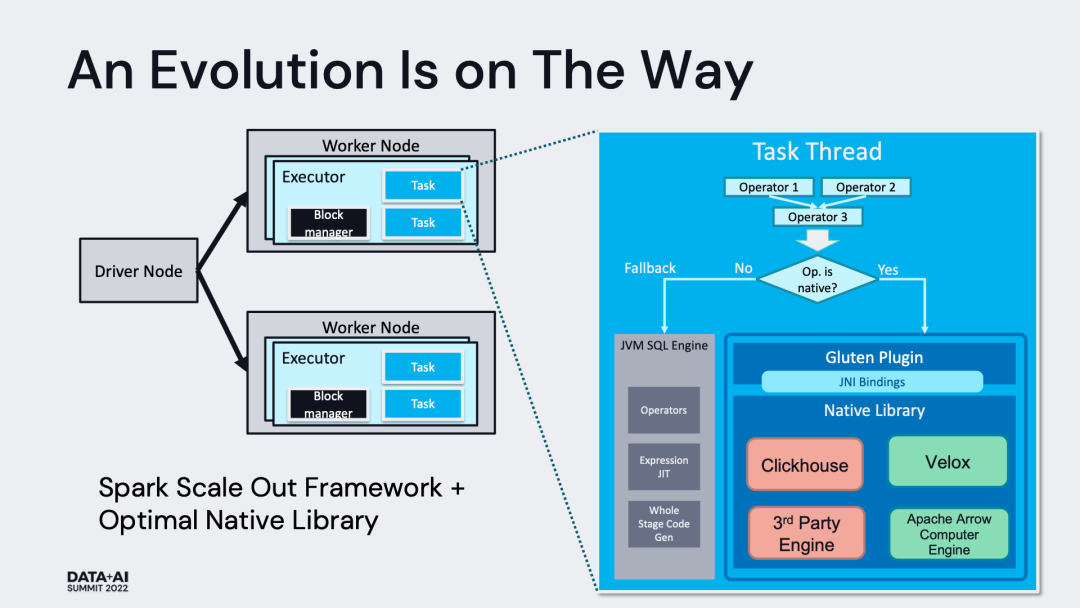
Gluten 這個單詞在拉丁文中有膠水的意思,Gluten 項目的作用也正像膠水一樣,主要用于“粘合” Apache Spark 和作為 Backend 的 Native Vectorized Engine。Backend 的選項有很多,目前在 Gluten 項目中已經明確開始支持的有 Velox[3]、Clickhouse 和 Apache Arrow。
從這個定位出發,我們結合下圖可以大致看到 Gluten 項目需要提供哪些能力:

2.1 Plan Conversion & Fallback
這是 Gluten 最核心的能力,簡單來講就是通過 Spark Plugin 的機制,把 Spark 查詢計劃攔截并下發給 Native Engine 來執行,跳過原生 Spark 不高效的執行路徑。整體的執行框架仍沿用 Spark 既有實現,包括消費接口、資源和執行調度、查詢計劃優化、上下游集成等。
一般來講,Native Engine 的能力,無法 100% 覆蓋 Spark 查詢執行計劃中的算子,因此 Gluten 必須分析 Spark 查詢執行計劃中哪些算子是可以下推給 Native Engine 的,并將這些相鄰的、可下推的算子封裝成一個 Pipeline,序列化并發送給 Native Engine 來執行并返回結果。我們依賴了一個獨立的名為 substrait 的開源項目[4],其使用 protobuf 來實現引擎中立的查詢計劃的序列化。
對于 Native Engine 無法承接的算子,Gluten 安排 fallback 回正常的 Spark 執行路徑進行計算。Databricks 的 Photon 目前也只是支持了部分 Spark 算子,應該是采用了類似的做法。
在線程模型的角度,Gluten 使用以 JNI 調用 Library 的形式,在 Spark Executor Task 線程中直接調用 Native 代碼,并且嚴格控制 JNI 調用的次數。因此,Gluten 并不會引入復雜的線程模型,具體示意可參考下圖:
2.2 Memory Management
由于 Native 代碼和 Spark Java 代碼在同一個進程中運行,因此 Gluten 具備了統一管理 Native 空間和 JVM 空間內存的條件。在 Gluten 中,Native 空間的代碼在申請內存的時候,會先向本地的 Memory Pool 申請內存,如果內存不足,會進一步向 JVM 中 Task Memory Manager 申請內存配額,得到相應配額后才會在 Native 空間成功申請下內存。通過這種方式,Native 空間的內存申請也受到 Task Memory Manager 的統一管理。當發生內存不足的現象時,Task Memory Manager 會觸發 spill,不管是 Native 還是 JVM 中的 operator 在收到 spill 通知時都會釋放內存。

2.3 Columnar Shuffle
Shuffle 本身就是影響性能的重要一環,由于 Native Engine 大多采用列式(Columnar)數據結構暫存數據,如果簡單的沿用 Spark 的基于行數據模型的 Shuffle,則會在 Shuffle Write 階段引入數據列轉行的環節,在 Shuffle Read 階段引入數據行轉列的環節,才能使數據可以流暢周轉。但是無論行轉列,還是列轉行的成本都不低。因此,Gluten 必須提供完整的 Columnar Shuffle 機制以避開這里的轉化開銷。
和原生 Spark 一樣,Columnar Shuffle 也需要支持內存不足時的 spill 操作,優先保證查詢的健壯性。
2.4 Compatibility
用戶出于所在公司技術棧的考慮,可能會偏向使用兼容不同的 Native Engine。因此,Gluten 有必要定義清晰的 JNI 接口,作為 Spark 框架和底層 Backend 通信的橋梁。這些接口用來滿足請求傳遞、數據傳輸、能力檢測等多個方面的需求。開發者只需要實現這些接口,并滿足相應的語義保障,就能利用 Gluten 完成 Spark 和 Native Engine 的“粘合”工作。
在 Spark 一側, 目前的架構設計中也預留的 Shim Layer 用來適配支持不同版本的 Spark。
2.5 其他方面的優化
除了使用 Native 代碼挖掘向量化執行的性能收益,Photon 的性能收益也來源于其他方面的優化(主要是查詢優化器),不過這些優化很多并未開源,Gluten 項目也在不斷吸納這部分的開源版本的優化。
#03
Status & Roadmap
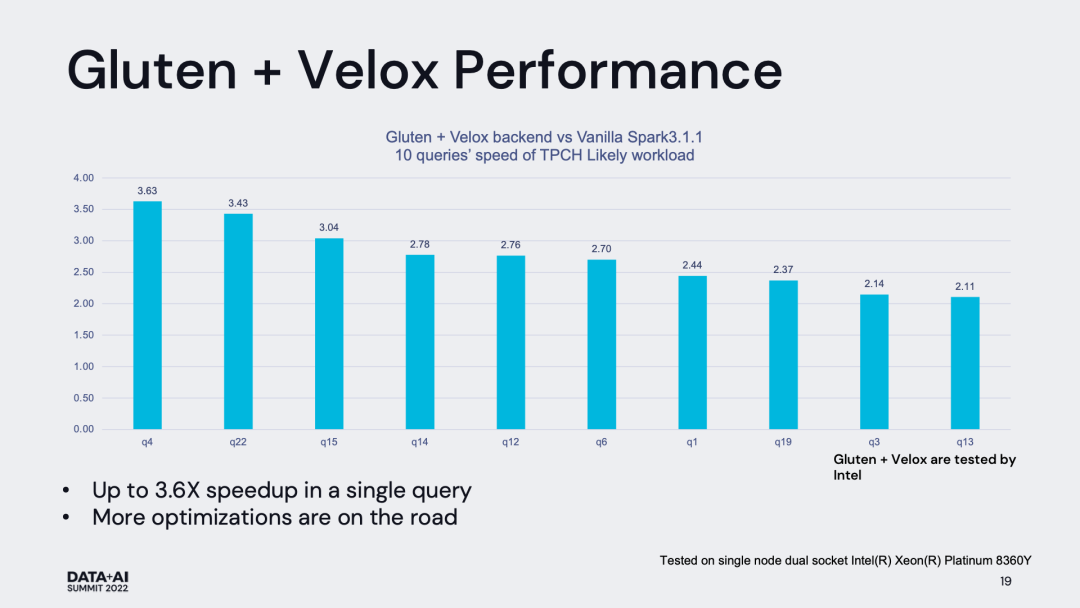
目前 Gluten 社區已經完成 Velox Backend 和 Clickhouse Backend 在 TPC-H 數據集上的驗證工作。兩種 backend 在 TPC-H 1000 數據集下的性能表現如下圖所示,可以看到無論是哪種 backend,都收獲了較為顯著的性能提升。對于所有 TPC-H 的所有查詢,我們僅通過簡單的集成,在并沒有對 backend 做深度定制的前提下就能普遍獲得大于兩倍的性能提升,這是非常令人振奮的。

接下來,我們將圍繞以下方面展開 Gluten 社區的工作:
完成在 TPC-DS 數據集上的驗證和性能測試工作
完善數據類型和函數的支持工作
完善數據源對接、數據源格式的支持工作
完善 CICD 流程和測試覆蓋
嘗試 Remote Shuffle Service 的對接工作
嘗試其他硬件加速的工作














