使用 pandas 對數據進行移動計算

假設有 10 天的銷售額數據,我們想每三天求一次總和,比如第五天的總和就是第三天 + 第四天 + 第五天的銷售額之和,這個時候該怎么做呢?
Series 對象有一個 rolling 方法,專門用來做移動計算,我們來看一下。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(amount.rolling(3).sum())
"""
0 NaN # NaN + NaN + 100
1 NaN # NaN + 100 + 90
2 300.0 # 100 + 90 + 110
3 350.0 # 90 + 110 + 150
4 370.0 # 110 + 150 + 110
5 390.0 # 150 + 110 + 130
6 320.0 # 110 + 130 + 80
7 300.0 # 130 + 80 + 90
8 270.0 # 80 + 90 + 100
9 340.0 # 90 + 100 + 150
dtype: float64
"""
結果和我們想要的是一樣的,amount.rolling(3) 相當于創(chuàng)建了一個長度為 3 的窗口,窗口從上到下依次滑動,我們畫一張圖:
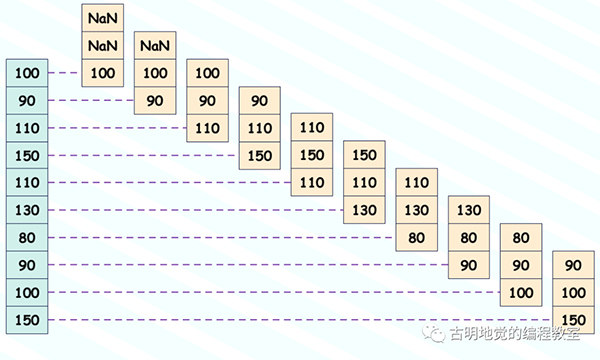
amount.rolling(3) 就做了類似于圖中的事情,然后在其基礎上調用 sum,會將每個窗口里面的元素加起來,就得到上面代碼輸出的結果。另外窗口的大小可以任意,這里我們以 3 為例。
除了sum,還可以求平均值、求方差等等,可以進行很多的操作,有興趣可以自己嘗試一下。當然我們也可以自定義函數:
import pandas as pd
import numpy as np
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# 調用 agg 方法,傳遞一個函數
# 參數 x 就是每個窗口里面的元素組成的 Series 對象
amount.rolling(3).agg(lambda x: np.sum(x) * 2)
)
"""
0 NaN # (NaN + NaN + 100) * 2
1 NaN # (NaN + 100 + 90) * 2
2 600.0 # (100 + 90 + 110) * 2
3 700.0 # (90 + 110 + 150) * 2
4 740.0 # (110 + 150 + 110) * 2
5 780.0 # (150 + 110 + 130) * 2
6 640.0 # (110 + 130 + 80) * 2
7 600.0 # (130 + 80 + 90) * 2
8 540.0 # (80 + 90 + 100) * 2
9 680.0 # (90 + 100 + 150) * 2
dtype: float64
"""
agg 里面的函數的邏輯可以任意,但返回的必須是一個數值。
此外我們注意到,開始的兩個元素為 NaN,這是因為 rolling(3) 表示從當前位置往上篩選,總共篩選 3 個元素,圖上已經畫的很清晰了。但如果我們希望元素不夠的時候有多少算多少,該怎么辦呢?比如:第一個窗口里面的元素之和就是第一個元素,第二個窗口里面的元素之和是第一個元素加上第二個元素。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# min_periods 表示窗口的最小觀測值
amount.rolling(3, min_periods=1).sum()
)
"""
0 100.0
1 190.0
2 300.0
3 350.0
4 370.0
5 390.0
6 320.0
7 300.0
8 270.0
9 340.0
dtype: float64
"""
添加一個 min_periods 參數即可實現,這個參數表示窗口的最小觀測值,即:窗口里面元素的最小數量,默認它和窗口的長度相等。我們窗口長度為 3,但指定了 min_periods 為 1,表示元素不夠也沒關系,只要有一個就行。
因此元素不夠的話,有幾個就算幾個。如果我們指定 min_periods 為 2 的話,那么會是什么結果呢?顯然第一個是 NaN,第二個還是 190.0,因為窗口里面的元素個數至少為 2。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# 窗口的最小觀測值為 2
amount.rolling(3, min_periods=2).sum()
)
"""
0 NaN
1 190.0
2 300.0
3 350.0
4 370.0
5 390.0
6 320.0
7 300.0
8 270.0
9 340.0
dtype: float64
"""
- 注意:min_periods必須小于等于窗口長度,否則報錯。
rolling 里面還有一個 center 參數,默認為 False。我們知道 rolling(3) 表示從當前元素往上篩選,加上本身總共篩選 3 個。
但如果將 center 指定為 True 的話,那么會以當前元素為中心,從兩個方向上進行篩選。比如 rolling(3, center=True),那么會往上選一個、往下選一個,再加上本身總共 3 個。所以示意圖會變成下面這樣:
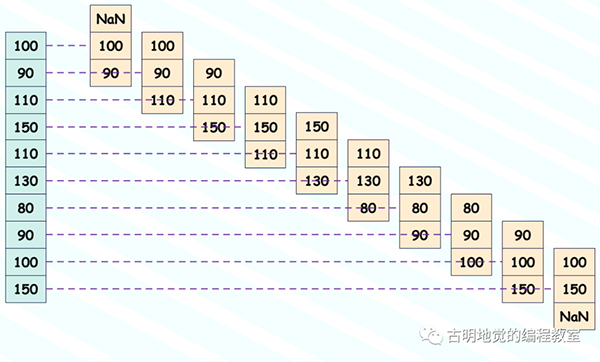
我們來測試一下:
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(3, center=True).sum()
)
"""
0 NaN
1 300.0
2 350.0
3 370.0
4 390.0
5 320.0
6 300.0
7 270.0
8 340.0
9 NaN
dtype: float64
"""
這里沒有指定 min_periods,最小觀測值和窗口長度相等,所以 rolling(3, center=True)會使得開頭出現一個 NaN,結尾出現一個 NaN。
這時候可能有人好奇了,如果窗口的長度為奇數的話很簡單,比如長度為 9,那么往上選 4 個、往下選 4 個,加上本身正好 9 個。但如果窗口的長度為偶數該怎么辦?比如長度為 8,這個時候會往上選 4 個、往下選 3 個,加上本身正好 8 個。
另外我們還可以從上往下篩選,比如窗口長度為 3,但我們是希望從當前元素開始往下篩選,加上本身總共篩選 3 個。
import pandas as pd
from pandas.api.indexers import FixedForwardWindowIndexer
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(
FixedForwardWindowIndexer(window_size=3)).sum()
)
"""
0 300.0
1 350.0
2 370.0
3 390.0
4 320.0
5 300.0
6 270.0
7 340.0
8 NaN
9 NaN
dtype: float64
"""
通過類FixedForwardWindowIndexer即可實現這一點,當然此時就不可以指定 center 參數了。
調用 amount.rolling() 會返回一個 Rolling 對象,再調用 Rolling 對象的 sum, max, min, mean, std 等方法即可對每個窗口求總和、最大值、最小值等等。當然我們也可以調用 agg 方法,里面?zhèn)魅胍粋€函數,來自定義每個窗口的計算邏輯。然后重點是,agg 里面除了接收一個函數之外,還能接收一個列表,列表里面可以有多個函數,然后同時執(zhí)行多個操作。
import pandas as pd
import numpy as np
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(3).agg(
[np.sum, np.mean, lambda x: np.sum(x) * 2])
)
# 執(zhí)行多個操作,那么會返回一個 DataFrame
"""
sum mean <lambda>
0 NaN NaN NaN
1 NaN NaN NaN
2 300.0 100.000000 600.0
3 350.0 116.666667 700.0
4 370.0 123.333333 740.0
5 390.0 130.000000 780.0
6 320.0 106.666667 640.0
7 300.0 100.000000 600.0
8 270.0 90.000000 540.0
9 340.0 113.333333 680.0
"""
除了 Series 之外,DataFrame 也有 rolling 方法,功能和用法是一樣的,只不過后者可以同時作用于多列。但大部分情況下,我們都調用 Series 對象的 rolling 方法。
rolling 方法還有一個強大的功能,就是它可以對時間進行移動分析,因為 pandas 本身就誕生在金融領域,所以非常擅長對時間的操作。
那么對時間進行移動分析的使用場景都有哪些呢?舉一個筆者在大四實習時所遇到的問題吧,當時在用 pandas 做審計,遇到過這樣一個需求:判斷是否存在 30 秒內充值次數超過 1000 次的情況(也就是檢測是否存在同時大量充值的情況),如果有就把它們找出來。
因為每一次充值都對應一條記錄,每條記錄都有一個具體的時間,換句話說就是要判斷是否存在某個 30 秒,在這其中出現了超過 1000 條的記錄。當時剛實習,被這個問題直接搞懵了,不過有了 rolling 方法就變得簡單多了。
import pandas as pd
amount = pd.Series(
[100, 100, 100, 100, 100, 100, 100, 100, 100, 100],
index=pd.DatetimeIndex(
["2020-1-1", "2020-1-3", "2020-1-4", "2020-1-6",
"2020-1-7", "2020-1-9", "2020-1-12", "2020-1-13",
"2020-1-14", "2020-1-15"])
)
print(amount)
"""
2020-01-01 100
2020-01-03 100
2020-01-04 100
2020-01-06 100
2020-01-07 100
2020-01-09 100
2020-01-12 100
2020-01-13 100
2020-01-14 100
2020-01-15 100
dtype: int64
"""
# 這里我們還是算 3 天之內的總和吧
# 為了簡單直觀我們把值都改成100
print(amount.rolling("3D").sum())
"""
2020-01-01 100.0
2020-01-03 200.0
2020-01-04 200.0
2020-01-06 200.0
2020-01-07 200.0
2020-01-09 200.0
2020-01-12 100.0
2020-01-13 200.0
2020-01-14 300.0
2020-01-15 300.0
dtype: float64
"""
我們來分析一下,首先 rolling("3D") 表示篩選 3 天之內的,而且如果是對時間進行移動分析的話,那么要求索引必須是 datetime 類型。
- 先看 2020-01-01,它上面沒有記錄了,所以是100(此時就沒有NaN了);
- 然后是 2020-01-03,由于上面的 2020-01-01 和它之間沒有超過3天,所以加起來總共是200;
- 再看 2020-01-12,由于它只能往上找 2020-01-10, 2020-01-11,然后加在一起。但它的上面是 2020-01-09,已經超過3天了,所以結果是 100(就是它本身);
- 最后看 2020-01-14,3 天之內的話,應該 2020-01-12, 2020-01-13,再加上自身的 2020-01-14,所以結果是300。2020-01-15 也是同理。
怎么樣,是不是很簡單呢?回到筆者當初的那個問題上來,如果是找出 30 秒內超過 1000 次的記錄的話,將交易時間設置為索引、直接 rolling("30S").count()。然后找出大于 1000 的記錄,說明該條記錄往上的第 1000 條記錄的交易時間和該條記錄的交易時間之差的絕對值不超過 30 秒(記錄是按照交易時間排好序的)。
至于這 30 秒內到底交易了多少次,直接將該條記錄的交易時間減去 30 秒,進行篩選就行了。所以用 rolling 方法處理該問題非常方便,但當時不知道,傻了吧唧地寫 for 循環(huán)一條條遍歷。
另外,關于 pandas 中表示時間的符號估計有人還不太清楚,最主要的是容易和 Python datetime 在格式化時所使用的符號搞混,下面我們來區(qū)分一下。
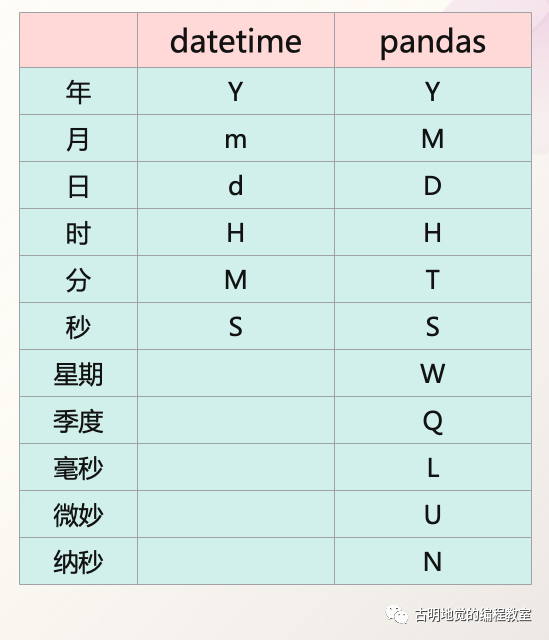
感覺如何,是不是既好用,功能又強大呢?