BI系統中為什么會有很多快照表
觀察一些大型用戶的 BI 系統,經常會發現數據倉庫中有很多快照表。如某交易業務的 BI 系統,交易明細表很大,被按月存儲成多個分段表。還有一些相對不太大的表,計算時要和交易明細表關聯,比如客戶表、雇員表、商品表等等。每個月底,這些表的完整數據都會被存儲成快照表,用于匹配當月的交易明細分段表。
為什么會有這么多看似很冗余的快照表存在呢?
這個交易明細表就是常說的事實表,是用來存儲發生事件的數據表,數據量會隨著時間不斷增長。除了交易明細表之外,訂單表、保險單表、銀行帳戶存取記錄表等也都是事實表。事實表中會有一些代碼字段和其它表關聯,比如上面說的交易明細表通過客戶號、雇員號、商品號分別關聯客戶表、雇員表和商品表。再比如訂單表通過產品號字段關聯產品表、銀行帳戶存取記錄表通過帳號字段關聯帳戶表等等。這些和事實表關聯的表稱為維表,下圖中的交易明細表與客戶表就構成了事實表和維表的關聯關系:
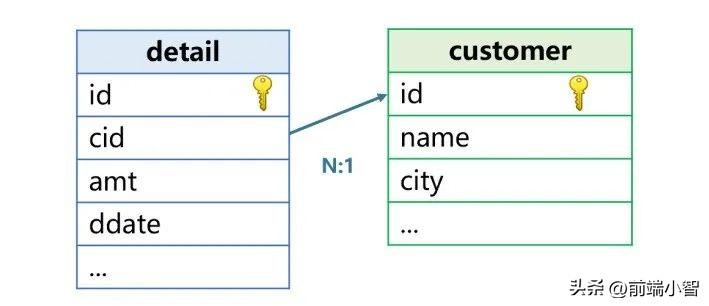
事實表關聯維表的目的,是需要用維表的字段參與計算。例如交易明細表與客戶表關聯后,就可以按照客戶所在城市來分組匯總交易金額、交易筆數等。
維表的數據相對比較固定,但仍然也會有修改。維表數據變動后,事實表中新產生的數據不受影響。而事實表以前的歷史數據則可能和維表的新數據不匹配。這時,如果用事實表的老數據,去關聯維表的新數據,就會出現錯誤的情況。
例如,編號為 B20101 的客戶 James,原先在紐約居住,產生了一些交易記錄。到了 2020 年 5 月 15 日,James 搬家到芝加哥,又產生了一些新的交易明細記錄。如果我們直接將客戶表中 James 的城市改成芝加哥,那么按照客戶城市分組匯總交易金額時,James 以前在紐約的交易也會被算到芝加哥,這明顯是不對的。之所以出錯,是因為 James 的交易記錄到底算哪個城市和時間有關,一律算成紐約或者芝加哥都是不對的。
如果不對這個問題加以特別處理,就會導致 BI 系統中(針對歷史數據)的統計值和 ERP 系統中(針對當時的數據)的統計值對不上的現象,而且這種錯誤還很難排查。
快照表就是為了解決這種問題而產生的。定時(比如每月末)生成有關數據表的快照,保存事實表某段時間(比如一個月)的數據和維表當時的完整數據,供后續統計分析計算,這樣就會保證事實表總是和同期的維表關聯,統計結果就不會出錯了。
但是,這就會造成很多冗余的維表數據,增加數據庫的存儲量;維表通常還會有多個,每個維表又有多個快照表,會導致表間關系變得異常復雜,大大增加系統的復雜度。
這樣,還會導致計算代碼也隨之變得復雜。比如說,每個月都有一個交易明細表及其對應的一批維表快照,如果要統計一年中按客戶所在城市分組的交易金額和筆數,就要將十二個月的交易明細表和各自的維表快照關聯后,再做十一次 UNION。這還僅僅是簡單的分組匯總,再復雜一些的統計分析計算,會出現非常長且復雜的 SQL 語句。維護都很困難,更不用說性能調優了。為此,很多采用快照方案的 BI 系統都禁止較長時間范圍的統計分析計算,嚴重時只能選擇一個時間周期(一個月)的數據做計算。
而且,快照方案也沒有徹底解決維表變動帶來的查詢不準確問題。BI 系統不可能在維度發生變動時就立即生成一個快照(那樣會有太多的快照而造成巨大的存儲量),一般只會定期生成快照表。這樣,兩次生成快照的時間點之間,如果發生維表數據的變動,仍然會出現計算錯誤。假設每個月最后一天生成交易明細表和客戶表的快照。James 是 5 月 15 日搬家的,在 5 月 31 日生成快照的時候,James 的城市會被保存為芝加哥。而 6 月 1 日之后就要基于這個快照做 5 月的查詢統計,那么 5 月 1 日到 15 日這段時間 James 的交易本來應該算紐約的,現在也都算成芝加哥的了,還是會出現錯誤,只是錯誤量相對較小而已。
還有一種變通辦法是用事實表和維表生成寬表。將交易明細表和客戶表數據關聯好,生成交易寬表,這個寬表中的客戶姓名、城市等就不會受到客戶維表數據變動的影響了,并且能保證系統的數據結構相對簡單。但是,寬表通常仍然只能是定期生成(實時生成寬表記錄會拖累交易系統的性能),也就仍然會有上述的在兩個生成時間點之間發生維表變化后導致的錯誤。而且,由于事實表和維表是多對一關系,交易寬表中的客戶數據將出現大量冗余,造成事實表膨脹,空間占用會遠遠超過快照方案。再者,寬表結構維護很不靈活,特別是需要增加字段時還要考慮大量歷史數據的處理。這就要求建立寬表時盡量將字段添加完全,而大而全的寬表占用的空間會更大。
其實,維表數據雖然有變動,但會相對很少,變動量與總數據量相比通常會少一個到幾個數量級。利用這個特征,我們可以設計更低成本的方法來解決這個問題。
開源數據計算引擎 SPL 提供的時間鍵機制,就利用了這個特征,可以便捷、準確地解決維表數據變動問題。
具體的做法是,在維表中增加一個時間字段,和原有主鍵一起組成聯合主鍵,這個字段稱為時間鍵。事實表和維表關聯時,用原來的外鍵字段加上合適的時間字段,與新維表的聯合主鍵關聯。時間鍵的關聯方式和原來的外鍵有所不同,并不是用“相等”的關系判斷的,而是找“指定時間前的最新記錄”來關聯。
仍以上述交易明細表和客戶表為例,后者要增加一個生效時間字段 edate,如下圖:
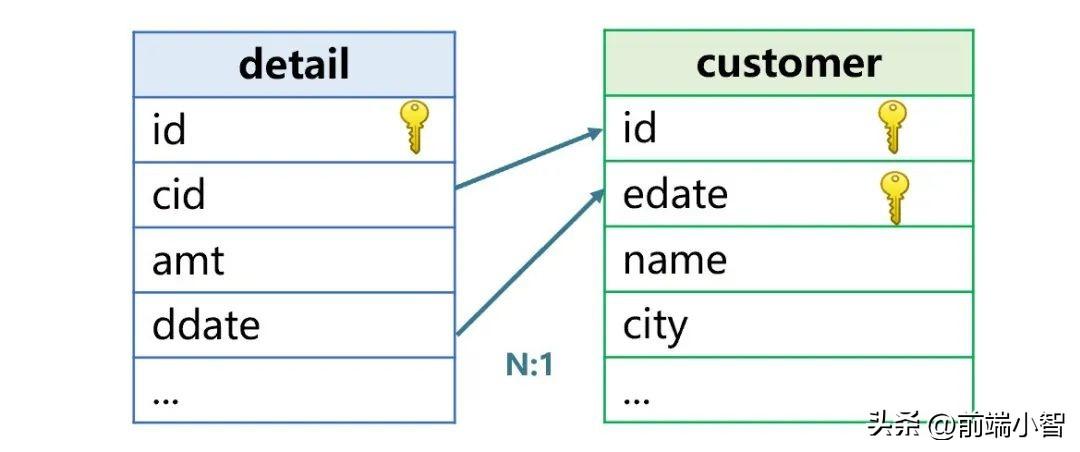
edate 存儲的是這條記錄是什么時候生效的,也就是維表發生變動的時間。比如客戶 James 搬家后,客戶表就會變成下圖這樣:
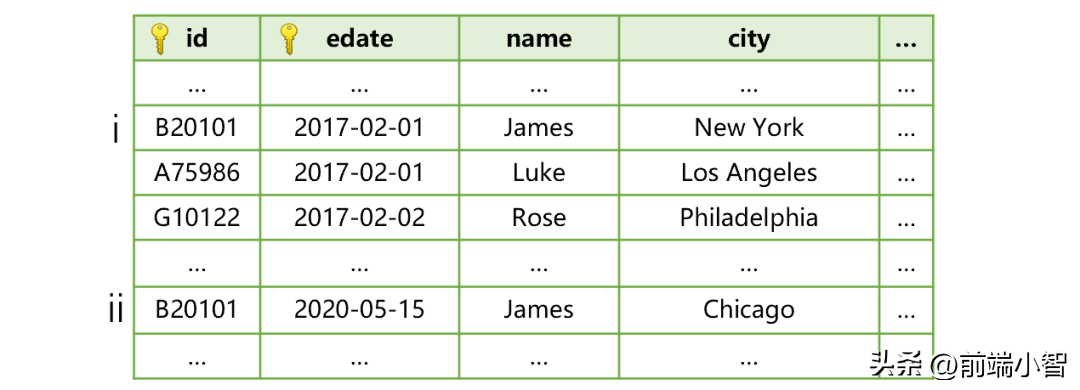
圖中,客戶 James 搬家前只有一條維表記錄 i。而搬家當天新增了第 ii 條記錄,生效日期是搬家的時間 2020-05-15。
這時,SPL 做交易明細表和客戶表關聯,除了比較 cid 和 id 是否相等,還要比較交易時間 ddate 和客戶記錄生效時間 edate,找到 edate 不大于 ddate 的最大值,其所在記錄才是對應的關聯記錄(也就是這個時間點之前的最新記錄)。這樣,James 搬家前的交易記錄日期是早于 2020-05-15 的,會和客戶表中生效日期為 2017-02-01 的記錄 i 關聯,所以這些交易明細會被算作紐約的。而 James 搬家后的交易記錄日期等于或晚于 2020-05-15,就會和客戶表中生效日期為 2020-05-15 的記錄 ii 關聯,這些交易明細就會被算作是芝加哥的。
可以看到,采用時間鍵機制后的關聯結果是符合實際情況的。這是因為,我們是在維表發生數據變動的當時,增加維表記錄并存入生效時間,所以可以保證后續計算的正確性。這樣,就可以避免定期生成快照或者寬表時存在的問題,不會出現兩次生成時間點之間的計算錯誤現象。
而且,因為維表的變動量很小,增加了變動信息的維表和原來的維表規模基本上是一樣的,并不會大幅加大存儲量。
理論上,也可以在關系數據庫的維表中增加類似的時間字段,但是卻沒辦法表示這種關聯關系。時間鍵的關聯顯然不是常規的等值 JOIN,使用非等值 JOIN 也要用復雜的子查詢選出最新的維表記錄再來關聯,語句很復雜,也很難保證執行性能。所以,在關系數據庫中,就只能用快照或寬表等方案來解決了。
SPL 實現時間鍵機制的代碼也很簡單,大致是下面這樣:
A | B | |
1 | =T("customer.btx") | >A1.keys@t(id,edate) |
2 | =file("detail.ctx").open().cursor() | =A2.switch(cid:ddate,A1) |
3 | =B2.groups(cid.city;sum(amt),count(~)) | |
A1 讀入客戶表,B1 定義聯合主鍵 id 和 edate,@s 選項就表示主鍵的最后一個字段是時間鍵。如果業務需要,也可以用精度更高的日期時間類型字段作為時間鍵。
A2 建立交易明細表的游標。
B2 將游標和 A1 中的客戶表關聯起來,明細表的關聯字段是 cid 和 ddate,客戶表是主鍵。使用方式和普通沒有時間鍵的維表是一樣的。
A3 用關聯的結果游標按照客戶所在城市分組匯總交易金額和交易筆數,這時候就不必再關心時間鍵了。
SPL 內置了時間鍵處理機制,運算性能和沒有時間鍵的維表差別很小。關聯時和普通維表一樣,可以隨意選定時間區間進行統計,不存在快照表那種難以跨越時間周期的問題。
SPL 提供的時間鍵可以很簡便地解決維表數據變動問題。事實表保持原狀,只在維表中增加時間字段,并記錄變動情況即可。可以在保證統計結果準確和計算性能的前提下,避免保留大量的快照表,降低系統復雜度;也可以避免寬表的大量數據冗余,保持靈活的系統結構。
SPL下載地址:http://c.raqsoft.com.cn/article/1595816810031
SPL開源地址:https://github.com/SPLWare/esProc