Spring Batch 批處理框架,真心強啊!!

Spring Batch是spring提供的一個數(shù)據(jù)處理框架。企業(yè)域中的許多應(yīng)用程序需要批量處理才能在關(guān)鍵任務(wù)環(huán)境中執(zhí)行業(yè)務(wù)操作。這些業(yè)務(wù)運營包括:
- 無需用戶交互即可最有效地處理大量信息的自動化,復雜處理。這些操作通常包括基于時間的事件(例如月末計算,通知或通信)。
- 在非常大的數(shù)據(jù)集中重復處理復雜業(yè)務(wù)規(guī)則的定期應(yīng)用(例如,保險利益確定或費率調(diào)整)。
- 集成從內(nèi)部和外部系統(tǒng)接收的信息,這些信息通常需要以事務(wù)方式格式化,驗證和處理到記錄系統(tǒng)中。批處理用于每天為企業(yè)處理數(shù)十億的交易。
Spring Batch是一個輕量級,全面的批處理框架,旨在開發(fā)對企業(yè)系統(tǒng)日常運營至關(guān)重要的強大批處理應(yīng)用程序。Spring Batch構(gòu)建了人們期望的Spring Framework特性(生產(chǎn)力,基于POJO的開發(fā)方法和一般易用性),同時使開發(fā)人員可以在必要時輕松訪問和利用更高級的企業(yè)服務(wù)。Spring Batch不是一個schuedling的框架。
Spring Batch提供了可重用的功能,這些功能對于處理大量的數(shù)據(jù)至關(guān)重要,包括記錄/跟蹤,事務(wù)管理,作業(yè)處理統(tǒng)計,作業(yè)重啟,跳過和資源管理。它還提供更高級的技術(shù)服務(wù)和功能,通過優(yōu)化和分區(qū)技術(shù)實現(xiàn)極高容量和高性能的批處理作業(yè)。
Spring Batch可用于兩種簡單的用例(例如將文件讀入數(shù)據(jù)庫或運行存儲過程)以及復雜的大量用例(例如在數(shù)據(jù)庫之間移動大量數(shù)據(jù),轉(zhuǎn)換它等等) 上)。大批量批處理作業(yè)可以高度可擴展的方式利用該框架來處理大量信息。
Spring Batch架構(gòu)介紹
一個典型的批處理應(yīng)用程序大致如下:
- 從數(shù)據(jù)庫,文件或隊列中讀取大量記錄。
- 以某種方式處理數(shù)據(jù)。
- 以修改之后的形式寫回數(shù)據(jù)。
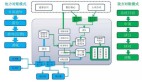
其對應(yīng)的示意圖如下:

spring batch的一個總體的架構(gòu)如下:

在spring batch中一個job可以定義很多的步驟step,在每一個step里面可以定義其專屬的ItemReader用于讀取數(shù)據(jù),ItemProcesseor?用于處理數(shù)據(jù),ItemWriter用于寫數(shù)據(jù),而每一個定義的job則都在JobRepository?里面,我們可以通過JobLauncher來啟動某一個job。關(guān)注公眾號:“碼猿技術(shù)專欄”,回復關(guān)鍵詞:“081“ 獲取阿里內(nèi)部的Spring Cloud Alibaba進階教程!
Spring Batch核心概念介紹
下面是一些概念是Spring batch框架中的核心概念。
什么是Job
Job和Step是spring batch執(zhí)行批處理任務(wù)最為核心的兩個概念。
其中Job是一個封裝整個批處理過程的一個概念。Job在spring batch的體系當中只是一個最頂層的一個抽象概念,體現(xiàn)在代碼當中則它只是一個最上層的接口,其代碼如下:
/**
* Batch domain object representing a job. Job is an explicit abstraction
* representing the configuration of a job specified by a developer. It should
* be noted that restart policy is applied to the job as a whole and not to a
* step.
*/
public interface Job {
String getName();
boolean isRestartable();
void execute(JobExecution execution);
JobParametersIncrementer getJobParametersIncrementer();
JobParametersValidator getJobParametersValidator();
}
在Job這個接口當中定義了五個方法,它的實現(xiàn)類主要有兩種類型的job,一個是simplejob,另一個是flowjob。在spring batch當中,job是最頂層的抽象,除job之外我們還有JobInstance?以及JobExecution這兩個更加底層的抽象。推薦Java之家:www.java-fmaily.cn
一個job是我們運行的基本單位,它內(nèi)部由step組成。job本質(zhì)上可以看成step的一個容器。一個job可以按照指定的邏輯順序組合step,并提供了我們給所有step設(shè)置相同屬性的方法,例如一些事件監(jiān)聽,跳過策略。
Spring Batch以SimpleJob?類的形式提供了Job接口的默認簡單實現(xiàn),它在Job之上創(chuàng)建了一些標準功能。一個使用java config的例子代碼如下:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}
這個配置的意思是:首先給這個job起了一個名字叫footballJob?,接著指定了這個job的三個step,他們分別由方法,playerLoad,gameLoad, playerSummarization實現(xiàn)。
什么是JobInstance
我們在上文已經(jīng)提到了JobInstance,他是Job的更加底層的一個抽象,他的定義如下:
public interface JobInstance {
/**
* Get unique id for this JobInstance.
* @return instance id
*/
public long getInstanceId();
/**
* Get job name.
* @return value of 'id' attribute from <job>
*/
public String getJobName();
}
他的方法很簡單,一個是返回Job的id,另一個是返回Job的名字。
JobInstance指的是job運行當中,作業(yè)執(zhí)行過程當中的概念。Instance本就是實例的意思。關(guān)注公眾號:“碼猿技術(shù)專欄”,回復關(guān)鍵詞:“081“ 獲取阿里內(nèi)部的Spring Cloud Alibaba進階教程!
比如說現(xiàn)在有一個批處理的job,它的功能是在一天結(jié)束時執(zhí)行行一次。我們假定這個批處理job的名字為'EndOfDay?'。在這個情況下,那么每天就會有一個邏輯意義上的JobInstance, 而我們必須記錄job的每次運行的情況。
什么是JobParameters
在上文當中我們提到了,同一個job每天運行一次的話,那么每天都有一個jobIntsance?,但他們的job定義都是一樣的,那么我們怎么來區(qū)別一個job的不同jobinstance?了。不妨先做個猜想,雖然jobinstance的job定義一樣,但是他們有的東西就不一樣,例如運行時間。
spring batch中提供的用來標識一個jobinstance?的東西是:JobParameters。JobParameters?對象包含一組用于啟動批處理作業(yè)的參數(shù),它可以在運行期間用于識別或甚至用作參考數(shù)據(jù)。我們假設(shè)的運行時間,就可以作為一個JobParameters。
例如, 我們前面的'EndOfDay'的job現(xiàn)在已經(jīng)有了兩個實例,一個產(chǎn)生于1月1日,另一個產(chǎn)生于1月2日,那么我們就可以定義兩個JobParameter?對象:一個的參數(shù)是01-01, 另一個的參數(shù)是01-02。因此,識別一個JobInstance的方法可以定義為:

因此,我么可以通過Jobparameter?來操作正確的JobInstance
什么是JobExecution
JobExecution?指的是單次嘗試運行一個我們定義好的Job的代碼層面的概念。job的一次執(zhí)行可能以失敗也可能成功。只有當執(zhí)行成功完成時,給定的與執(zhí)行相對應(yīng)的JobInstance才也被視為完成。
還是以前面描述的EndOfDay的job作為示例,假設(shè)第一次運行01-01-2019的JobInstance?結(jié)果是失敗。那么此時如果使用與第一次運行相同的Jobparameter?參數(shù)(即01-01-2019)作業(yè)參數(shù)再次運行,那么就會創(chuàng)建一個對應(yīng)于之前jobInstance?的一個新的JobExecution?實例,JobInstance仍然只有一個。
JobExecution的接口定義如下:
public interface JobExecution {
/**
* Get unique id for this JobExecution.
* @return execution id
*/
public long getExecutionId();
/**
* Get job name.
* @return value of 'id' attribute from <job>
*/
public String getJobName();
/**
* Get batch status of this execution.
* @return batch status value.
*/
public BatchStatus getBatchStatus();
/**
* Get time execution entered STARTED status.
* @return date (time)
*/
public Date getStartTime();
/**
* Get time execution entered end status: COMPLETED, STOPPED, FAILED
* @return date (time)
*/
public Date getEndTime();
/**
* Get execution exit status.
* @return exit status.
*/
public String getExitStatus();
/**
* Get time execution was created.
* @return date (time)
*/
public Date getCreateTime();
/**
* Get time execution was last updated updated.
* @return date (time)
*/
public Date getLastUpdatedTime();
/**
* Get job parameters for this execution.
* @return job parameters
*/
public Properties getJobParameters();
}
每一個方法的注釋已經(jīng)解釋的很清楚,這里不再多做解釋。只提一下BatchStatus,JobExecution?當中提供了一個方法getBatchStatus?用于獲取一個job某一次特地執(zhí)行的一個狀態(tài)。BatchStatus是一個代表job狀態(tài)的枚舉類,其定義如下:
public enum BatchStatus {STARTING, STARTED, STOPPING,
STOPPED, FAILED, COMPLETED, ABANDONED }
這些屬性對于一個job的執(zhí)行來說是非常關(guān)鍵的信息,并且spring batch會將他們持久到數(shù)據(jù)庫當中. 在使用Spring batch的過程當中spring batch會自動創(chuàng)建一些表用于存儲一些job相關(guān)的信息,用于存儲JobExecution?的表為batch_job_execution,下面是一個從數(shù)據(jù)庫當中截圖的實例:

什么是Step
每一個Step對象都封裝了批處理作業(yè)的一個獨立的階段。事實上,每一個Job本質(zhì)上都是由一個或多個步驟組成。每一個step包含定義和控制實際批處理所需的所有信息。
任何特定的內(nèi)容都由編寫Job的開發(fā)人員自行決定。一個step可以非常簡單也可以非常復雜。例如,一個step的功能是將文件中的數(shù)據(jù)加載到數(shù)據(jù)庫中,那么基于現(xiàn)在spring batch的支持則幾乎不需要寫代碼。更復雜的step可能具有復雜的業(yè)務(wù)邏輯,這些邏輯作為處理的一部分。
與Job一樣,Step具有與JobExecution類似的StepExecution,如下圖所示:

什么是StepExecution
StepExecution表示一次執(zhí)行Step, 每次運行一個Step時都會創(chuàng)建一個新的StepExecution?,類似于JobExecution?。但是,某個步驟可能由于其之前的步驟失敗而無法執(zhí)行。且僅當Step實際啟動時才會創(chuàng)建StepExecution。
一次step執(zhí)行的實例由StepExecution?類的對象表示。每個StepExecution?都包含對其相應(yīng)步驟的引用以及JobExecution和事務(wù)相關(guān)的數(shù)據(jù),例如提交和回滾計數(shù)以及開始和結(jié)束時間。
此外,每個步驟執(zhí)行都包含一個ExecutionContext,其中包含開發(fā)人員需要在批處理運行中保留的任何數(shù)據(jù),例如重新啟動所需的統(tǒng)計信息或狀態(tài)信息。下面是一個從數(shù)據(jù)庫當中截圖的實例:

什么是ExecutionContext
ExecutionContext?即每一個StepExecution? 的執(zhí)行環(huán)境。它包含一系列的鍵值對。我們可以用如下代碼獲取ExecutionContext:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
什么是JobRepository
JobRepository?是一個用于將上述job,step等概念進行持久化的一個類。它同時給Job和Step以及下文會提到的JobLauncher實現(xiàn)提供CRUD操作。
首次啟動Job時,將從repository?中獲取JobExecution?,并且在執(zhí)行批處理的過程中,StepExecution和JobExecution將被存儲到repository當中。
@EnableBatchProcessing?注解可以為JobRepository提供自動配置。
什么是JobLauncher
JobLauncher這個接口的功能非常簡單,它是用于啟動指定了JobParameters?的Job,為什么這里要強調(diào)指定了JobParameter?,原因其實我們在前面已經(jīng)提到了,jobparameter和job一起才能組成一次job的執(zhí)行。下面是代碼實例:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
上面run方法實現(xiàn)的功能是根據(jù)傳入的job以及jobparamaters從JobRepository?獲取一個JobExecution并執(zhí)行Job。
什么是Item Reader
ItemReader是一個讀數(shù)據(jù)的抽象,它的功能是為每一個Step提供數(shù)據(jù)輸入。當ItemReader以及讀完所有數(shù)據(jù)時,它會返回null來告訴后續(xù)操作數(shù)據(jù)已經(jīng)讀完。Spring Batch為ItemReader?提供了非常多的有用的實現(xiàn)類,比如JdbcPagingItemReader,JdbcCursorItemReader等等。
ItemReader支持的讀入的數(shù)據(jù)源也是非常豐富的,包括各種類型的數(shù)據(jù)庫,文件,數(shù)據(jù)流,等等。幾乎涵蓋了我們的所有場景。
下面是一個JdbcPagingItemReader的例子代碼:
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}
JdbcPagingItemReader?必須指定一個PagingQueryProvider,負責提供SQL查詢語句來按分頁返回數(shù)據(jù)。
下面是一個JdbcCursorItemReader的例子代碼:
private JdbcCursorItemReader<Map<String, Object>> buildItemReader(final DataSource dataSource, String tableName,
String tenant) {
JdbcCursorItemReader<Map<String, Object>> itemReader = new JdbcCursorItemReader<>();
itemReader.setDataSource(dataSource);
itemReader.setSql("sql here");
itemReader.setRowMapper(new RowMapper());
return itemReader;
}
什么是Item Writer
既然ItemReader是讀數(shù)據(jù)的一個抽象,那么ItemWriter自然就是一個寫數(shù)據(jù)的抽象,它是為每一個step提供數(shù)據(jù)寫出的功能。寫的單位是可以配置的,我們可以一次寫一條數(shù)據(jù),也可以一次寫一個chunk的數(shù)據(jù),關(guān)于chunk下文會有專門的介紹。ItemWriter對于讀入的數(shù)據(jù)是不能做任何操作的。
Spring Batch為ItemWriter也提供了非常多的有用的實現(xiàn)類,當然我們也可以去實現(xiàn)自己的writer功能。
什么是Item Processor
ItemProcessor?對項目的業(yè)務(wù)邏輯處理的一個抽象, 當ItemReader?讀取到一條記錄之后,ItemWriter還未寫入這條記錄之前,I我們可以借助temProcessor提供一個處理業(yè)務(wù)邏輯的功能,并對數(shù)據(jù)進行相應(yīng)操作。
如果我們在ItemProcessor?發(fā)現(xiàn)一條數(shù)據(jù)不應(yīng)該被寫入,可以通過返回null來表示。ItemProcessor和ItemReader以及ItemWriter可以非常好的結(jié)合在一起工作,他們之間的數(shù)據(jù)傳輸也非常方便。我們直接使用即可。
chunk 處理流程
spring batch提供了讓我們按照chunk處理數(shù)據(jù)的能力,一個chunk的示意圖如下:

它的意思就和圖示的一樣,由于我們一次batch的任務(wù)可能會有很多的數(shù)據(jù)讀寫操作,因此一條一條的處理并向數(shù)據(jù)庫提交的話效率不會很高,因此spring batch提供了chunk這個概念,我們可以設(shè)定一個chunk size?,spring batch 將一條一條處理數(shù)據(jù),但不提交到數(shù)據(jù)庫,只有當處理的數(shù)據(jù)數(shù)量達到chunk size設(shè)定的值得時候,才一起去commit.
java的實例定義代碼如下:


在上面這個step里面,chunk size被設(shè)為了10,當ItemReader讀的數(shù)據(jù)數(shù)量達到10的時候,這一批次的數(shù)據(jù)就一起被傳到itemWriter?,同時transaction被提交。
skip策略和失敗處理
一個batch的job的step,可能會處理非常大數(shù)量的數(shù)據(jù),難免會遇到出錯的情況,出錯的情況雖出現(xiàn)的概率較小,但是我們不得不考慮這些情況,因為我們做數(shù)據(jù)遷移最重要的是要保證數(shù)據(jù)的最終一致性。spring batch當然也考慮到了這種情況,并且為我們提供了相關(guān)的技術(shù)支持,請看如下bean的配置:

我們需要留意這三個方法,分別是skipLimit(),skip(),noSkip(),skipLimit方法的意思是我們可以設(shè)定一個我們允許的這個step可以跳過的異常數(shù)量,假如我們設(shè)定為10,則當這個step運行時,只要出現(xiàn)的異常數(shù)目不超過10,整個step都不會fail。
注意,若不設(shè)定skipLimit,則其默認值是0。
skip方法我們可以指定我們可以跳過的異常,因為有些異常的出現(xiàn),我們是可以忽略的。
noSkip方法的意思則是指出現(xiàn)這個異常我們不想跳過,也就是從skip的所以exception?當中排除這個exception,從上面的例子來說,也就是跳過所有除FileNotFoundException?的exception。那么對于這個step來說,F(xiàn)ileNotFoundException?就是一個fatal的exception?,拋出這個exception的時候step就會直接fail
批處理操作指南
本部分是一些使用spring batch時的值得注意的點。
批處理原則
在構(gòu)建批處理解決方案時,應(yīng)考慮以下關(guān)鍵原則和注意事項:
(1) 批處理體系結(jié)構(gòu)通常會影響體系結(jié)構(gòu)
(2) 盡可能簡化并避免在單批應(yīng)用程序中構(gòu)建復雜的邏輯結(jié)構(gòu)
(3) 保持數(shù)據(jù)的處理和存儲在物理上靠得很近(換句話說,將數(shù)據(jù)保存在處理過程中)。
(4) 最大限度地減少系統(tǒng)資源的使用,尤其是I / O?. 在internal memory中執(zhí)行盡可能多的操作。
(5) 查看應(yīng)用程序I / O?(分析SQL語句)以確保避免不必要的物理I / O. 特別是,需要尋找以下四個常見缺陷:
- 當數(shù)據(jù)可以被讀取一次并緩存或保存在工作存儲中時,讀取每個事務(wù)的數(shù)據(jù)。
- 重新讀取先前在同一事務(wù)中讀取數(shù)據(jù)的事務(wù)的數(shù)據(jù)。
- 導致不必要的表或索引掃描。
- 未在SQL語句的WHERE子句中指定鍵值。
(6) 在批處理運行中不要做兩次一樣的事情。例如,如果需要數(shù)據(jù)匯總以用于報告目的,則應(yīng)該(如果可能)在最初處理數(shù)據(jù)時遞增存儲的總計,因此您的報告應(yīng)用程序不必重新處理相同的數(shù)據(jù)。
(7) 在批處理應(yīng)用程序開始時分配足夠的內(nèi)存,以避免在此過程中進行耗時的重新分配。
(8) 總是假設(shè)數(shù)據(jù)完整性最差。插入適當?shù)臋z查和記錄驗證以維護數(shù)據(jù)完整性。
(9) 盡可能實施校驗和以進行內(nèi)部驗證。例如,對于一個文件里的數(shù)據(jù)應(yīng)該有一個數(shù)據(jù)條數(shù)紀錄,告訴文件中的記錄總數(shù)以及關(guān)鍵字段的匯總。
(10) 在具有真實數(shù)據(jù)量的類似生產(chǎn)環(huán)境中盡早計劃和執(zhí)行壓力測試。
(11) 在大批量系統(tǒng)中,數(shù)據(jù)備份可能具有挑戰(zhàn)性,特別是如果系統(tǒng)以24-7在線的情況運行。數(shù)據(jù)庫備份通常在在線設(shè)計中得到很好的處理,但文件備份應(yīng)該被視為同樣重要。如果系統(tǒng)依賴于文件,則文件備份過程不僅應(yīng)該到位并記錄在案,還應(yīng)定期進行測試。
如何默認不啟動job
在使用java config使用spring batch的job時,如果不做任何配置,項目在啟動時就會默認去跑我們定義好的批處理job。那么如何讓項目在啟動時不自動去跑job呢?
spring batch的job會在項目啟動時自動run,如果我們不想讓他在啟動時run的話,可以在application.properties中添加如下屬性:
spring.batch.job.enabled=false
在讀數(shù)據(jù)時內(nèi)存不夠
在使用spring batch做數(shù)據(jù)遷移時,發(fā)現(xiàn)在job啟動后,執(zhí)行到一定時間點時就卡在一個地方不動了,且log也不再打印,等待一段時間之后,得到如下錯誤:

紅字的信息為:Resource exhaustion event:the JVM was unable to allocate memory from the heap。
翻譯過來的意思就是項目發(fā)出了一個資源耗盡的事件,告訴我們java虛擬機無法再為堆分配內(nèi)存。
造成這個錯誤的原因是: 這個項目里的batch job的reader是一次性拿回了數(shù)據(jù)庫里的所有數(shù)據(jù),并沒有進行分頁,當這個數(shù)據(jù)量太大時,就會導致內(nèi)存不夠用。解決的辦法有兩個:
- 調(diào)整reader讀數(shù)據(jù)邏輯,按分頁讀取,但實現(xiàn)上會麻煩一些,且運行效率會下降
- 增大service內(nèi)存