開發一套高容錯分布式系統
一、寫在前面
上篇文章《??億流量大考(1):日增上億數據,把MySQL直接搞宕機了...??》,聊了一下商家數據平臺第一個階段的架構演進。通過離線與實時計算鏈路的拆分,離線計算的增量計算優化,實時計算的滑動時間窗口計算引擎,分庫分表 + 讀寫分離,等各種技術手段,支撐住了百億量級的數據量的存儲與計算。
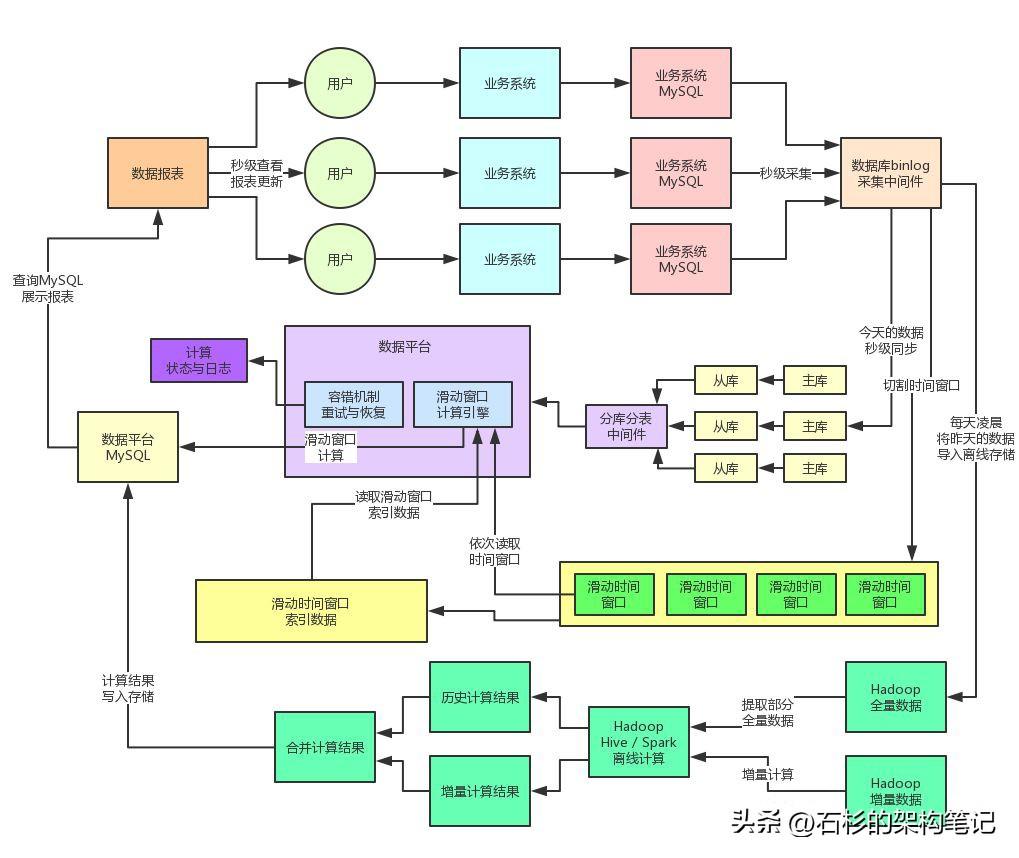
我們先來回看一下當時的那個架構圖,然后繼續聊聊這套架構在面對高并發、高可用、高性能等各種技術挑戰下,應該如何繼續演進。
二、active-standby高可用架構
大家看看上面的那個架構圖,有沒有發現里面有一個比較致命的問題?就是如何避免系統單點故障!
在最初的部署架構下,因為數據平臺系統對CPU、內存、磁盤的要求很高,所以我們是單機部署在一臺較高配置的虛擬機上的,16核CPU、64G內存、SSD固態硬盤。這個機器的配置是可以保證數據平臺系統在高負載之下正常運行的。
但是如果僅僅是單機部署數據平臺系統的話,會導致致命的單點故障問題,也就是如果單臺機器上部署的數據平臺系統宕機的話,就會立馬導致整套系統崩潰。
因此在初期的階段,我們對數據平臺實現了active-standby的高可用架構,也就是一共部署在兩臺機器上,但是同一時間只有一臺機器是會運行的,但是另外一臺機器是備用的。處于active狀態的系統會將滑動窗口計算引擎的計算狀態和結果寫入zookeeper中,作為元數據存儲起來。
關于元數據基于zookeeper來存儲,我們是充分參考了開源的Storm流式計算引擎的架構實現,因為Storm作為一個非常優秀的分布式流式計算系統,同樣需要高并發的讀寫大量的計算中間狀態和數據,他就是基于zookeeper來進行存儲的。
本身zookeeper的讀寫性能非常的高,而且zookeeper集群自身就可以做到非常高的可用性,同時還提供了大量的分布式系統需要的功能支持,包括分布式鎖、分布式協調、master選舉、主備切換等等。
因此基于zookeeper我們實現了active-standby的主備自動切換,如果active節點宕機,那么standby節點感知到,會自動切花為active,同時自動讀取他們共享的一個計算引擎的中間狀態,然后繼續恢復之前的計算。
大家看下面的圖,一起感受一下。
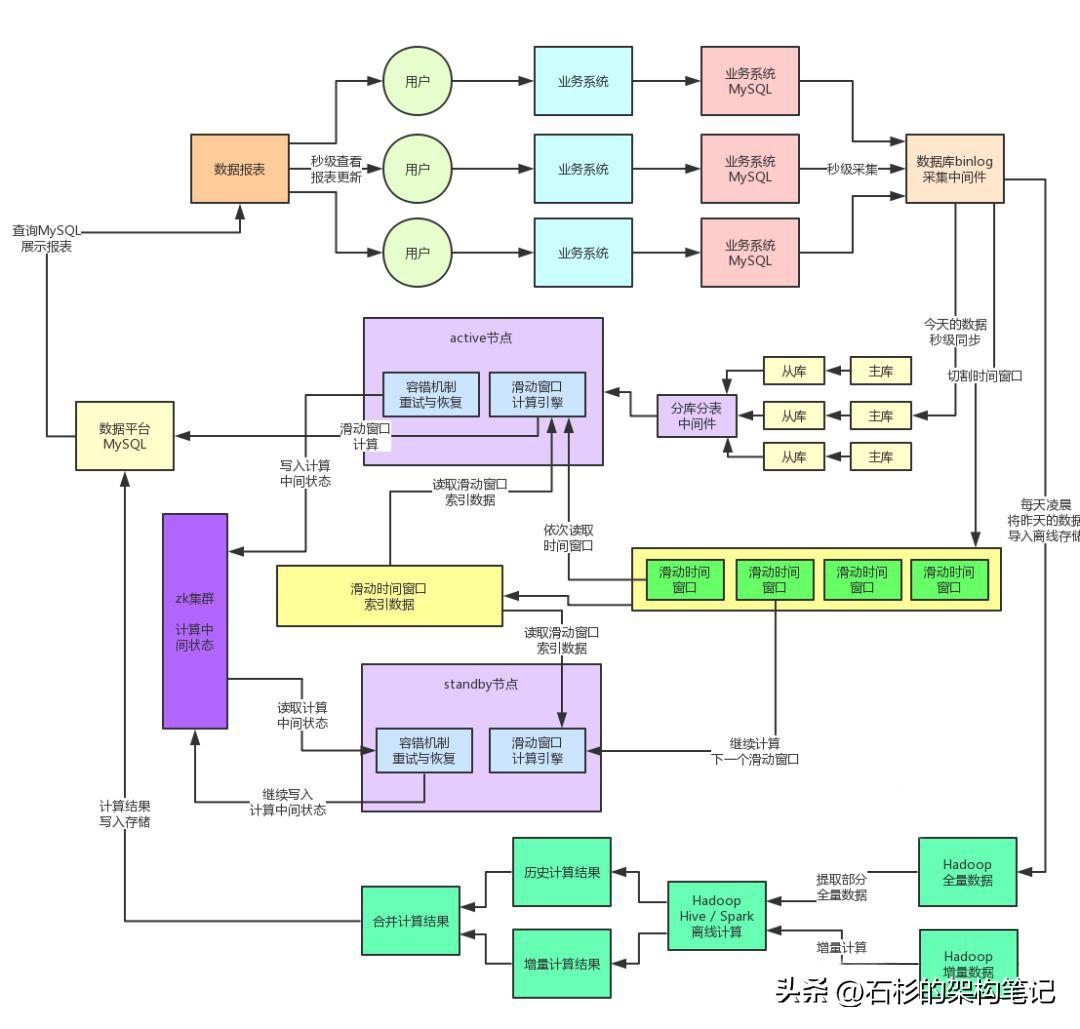
在完成上述的active-standby架構之后,肯定是消除掉了系統的單點故障了,保證了基本的可用性。而且在實際的線上生產環境中表現還不錯,一年系統總有個幾次會出現故障,但是每次都能自動切換standby機器穩定運行。
這里隨便給大家舉幾個生產環境機器故障的例子,因為部署在公司的云環境中,用的都是虛擬機,可能遇到的坑爹故障包括但不限于下面幾種情況:
- 虛擬機所在的宿主機掛了
- 虛擬機的網絡出現故障
- 負載過高導致磁盤壞了
所以在線上高負載環境中,永遠別寄希望于機器永遠不宕機,你要隨時做好準備,機器會掛!系統必須做好充分的故障預測、高可用架構以及故障演練,保證各種場景下都可以繼續運行。
三、Master-Slave架構的分布式計算系統
但是此時另外一個問題又來了,大家考慮一個問題,數據平臺系統其實最核心的任務就是對一個一個的時間窗口中的數據進行計算,但是隨著每天的日增數據量越來越多,每個時間窗口內的數據量也會越來越大,同時會導致數據平臺系統的計算負載越來越高。
在線上生產環境表現出來的情況就是,數據平臺系統部署機器的CPU負載越來越高,高峰期很容易會100%,機器壓力較大。新一輪的系統重構,勢在必行。
首先我們將數據平臺系統徹底重構和設計為一套分布式的計算系統,將任務調度與任務計算兩個職責進行分離,有一個專門的Master節點負責讀取切分好的數據分片(也就是所謂的時間窗口,一個窗口就是一個數據分片),然后將各個數據分片的計算任務分發給多個Slave節點。
Slave節點的任務就是專門接收一個一個的計算任務,每個計算任務就是對一個數據分片執行一個幾百行到上千行的復雜SQL語句來產出對應的數據分析結果。
同時對Master節點,我們為了避免其出現單點故障,所以還是沿用了之前的Active-Standby架構,Master節點是在線上部署一主一備的,平時都是active節點運作,一旦宕機,standby節點會切換為active節點,然后自動調度運行各個計算任務。
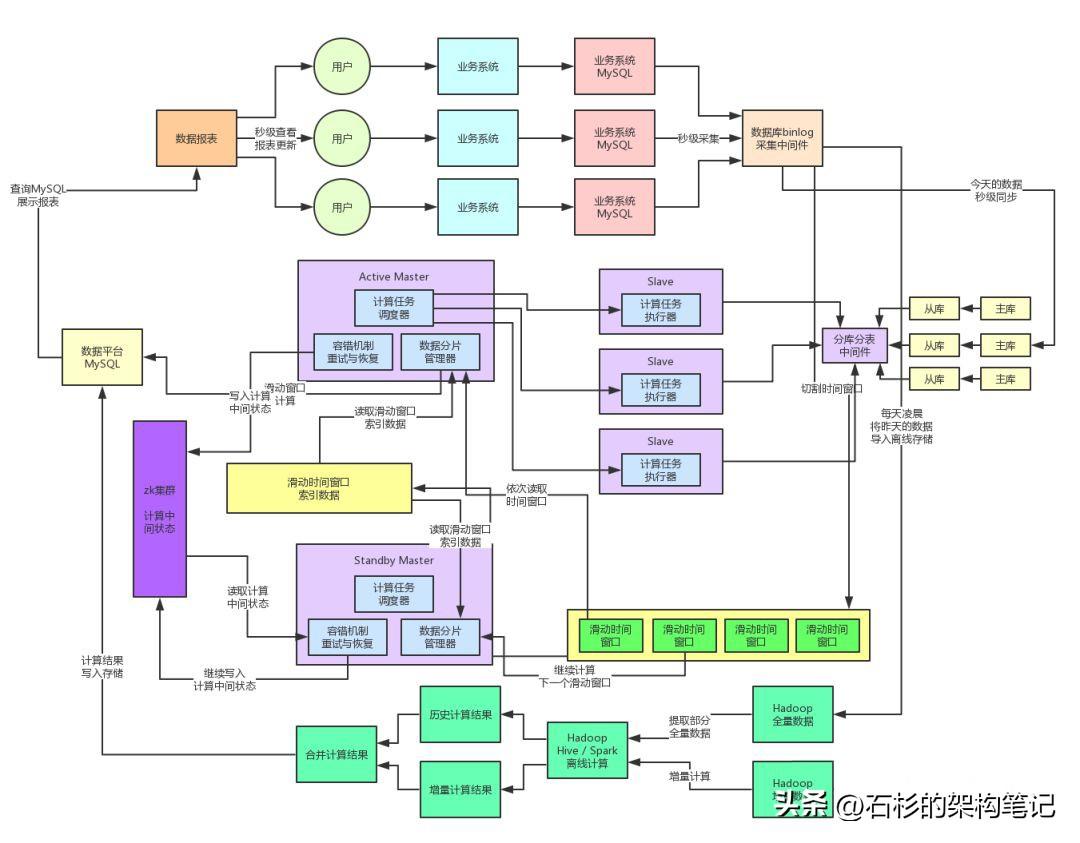
這套架構部署上線之后,效果還是很不錯的,因為Master節點其實就是讀取數據分片,然后為每個數據分片構造計算任務,接著就是將計算任務分發給各個Slave節點進行計算。
Master節點幾乎沒有太多復雜的任務,部署一臺高配置的機器就絕對沒問題。
負載主要在Slave節點,而Slave節點因為部署了多臺機器,每臺機器就是執行部分計算任務,所以很大程度上降低了單臺Slave節點的負載,而且只要有需要,隨時可以對Slave集群進行擴容部署更多的機器,這樣無論計算任務有多繁忙,都可以不斷的擴容,保證單臺Slave機器的負載不會過高。
四、彈性計算資源調度機制
在解決了單臺機器計算負載壓力過高的問題之后,我們又遇到了下一個問題,就是在線上生產環境中偶爾會發現某個計算任務耗時過長,導致某臺Slave機器積壓了大量的計算任務一直遲遲得不到處理。
這個問題的產生,其實主要是由于系統的高峰和低谷的數據差異導致的。
大家可以想想,在高峰期,瞬時涌入的數據量很大,很可能某個數據分片包含的數據量過大,達到普通數據分片的幾倍甚至幾十倍,這是原因之一。
還有一個原因,因為截止到目前為止的計算操作,其實還是基于幾百行到上千行的復雜SQL落地到MySQL從庫中去執行計算的。
因此,在高峰期可能MySQL從庫所在數據庫服務器的CPU負載、IO負載都會非常的高,導致SQL執行性能下降數倍,這個時候數據分片里的數據量又大,執行的又慢,很容易就會導致某個計算任務執行時間過長。
最后一個造成負載不均衡的原因,就是每個計算任務對應一個數據分片和一個SQL,但是不同的SQL執行效率不同,有的SQL可能只要200毫秒就可以結束,有的SQL要1秒,所以不同的SQL執行效率不同,造成了不同的計算任務的執行時間的不同。
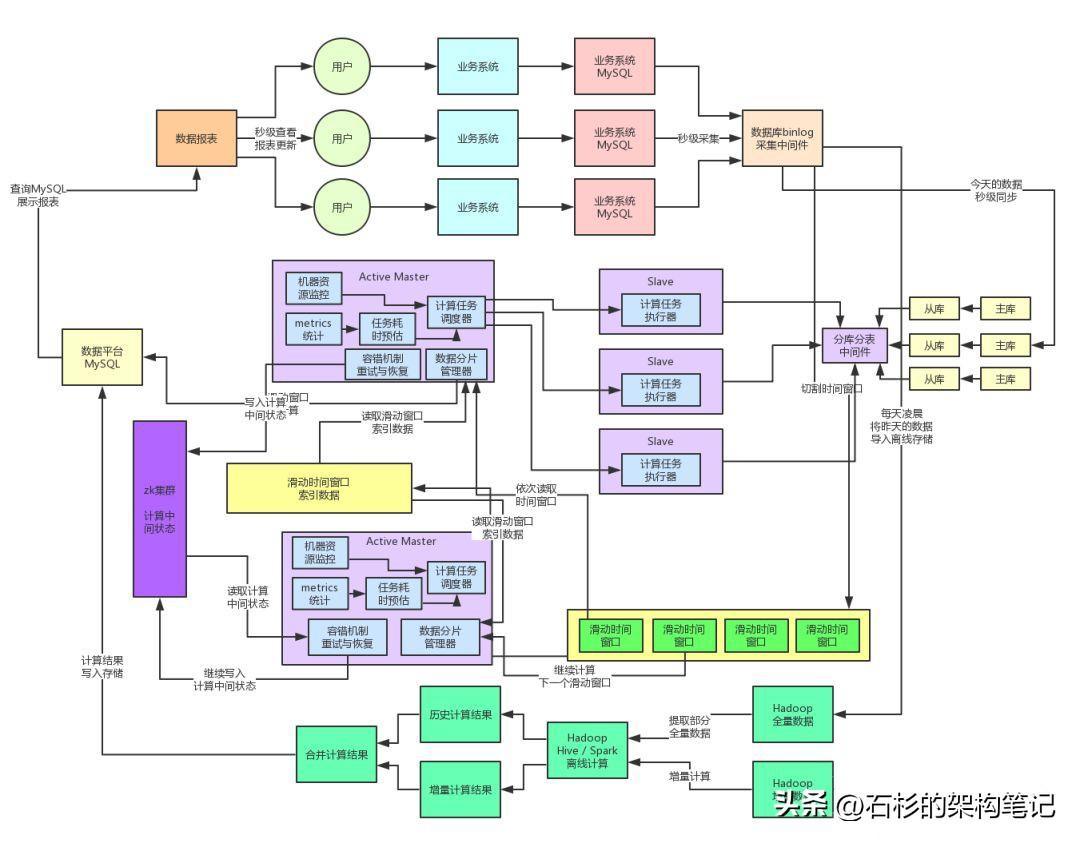
因此,我們又專門在Master節點中加入了計算任務metrics上報、計算任務耗時預估、任務執行狀態監控、機器資源管理、彈性資源調度等機制。
實現的一個效果大致就是:
- Master節點會實時感知到各個機器的計算任務執行情況、排隊負載壓力、資源使用等情況。
- 同時還會收集各個機器的計算任務的歷史metrics
- 接著會根據計算任務的歷史metrics、預估當前計算任務的耗時、綜合考慮當前各Slave機器的負載,來將任務分發給負載較低的Slave機器。
通過這套機制,我們充分保證了線上Slave集群資源的均衡利用,不會出現單臺機器負載過高,計算任務排隊時間過長的情況,經過生產環境的落地實踐以及一些優化之后,該機制運行良好。
五、分布式系統高容錯機制
其實一旦將系統重構為分布式系統架構之后,就可能會出現各種各樣的問題,此時就需要開發一整套的容錯機制。
大體說起來的話,這套系統目前在線上生產環境可能產生的問題包括但不限于:
- 某個Slave節點在執行過程中突然宕機
- 某個計算任務執行時間過長
- 某個計算任務執行失敗
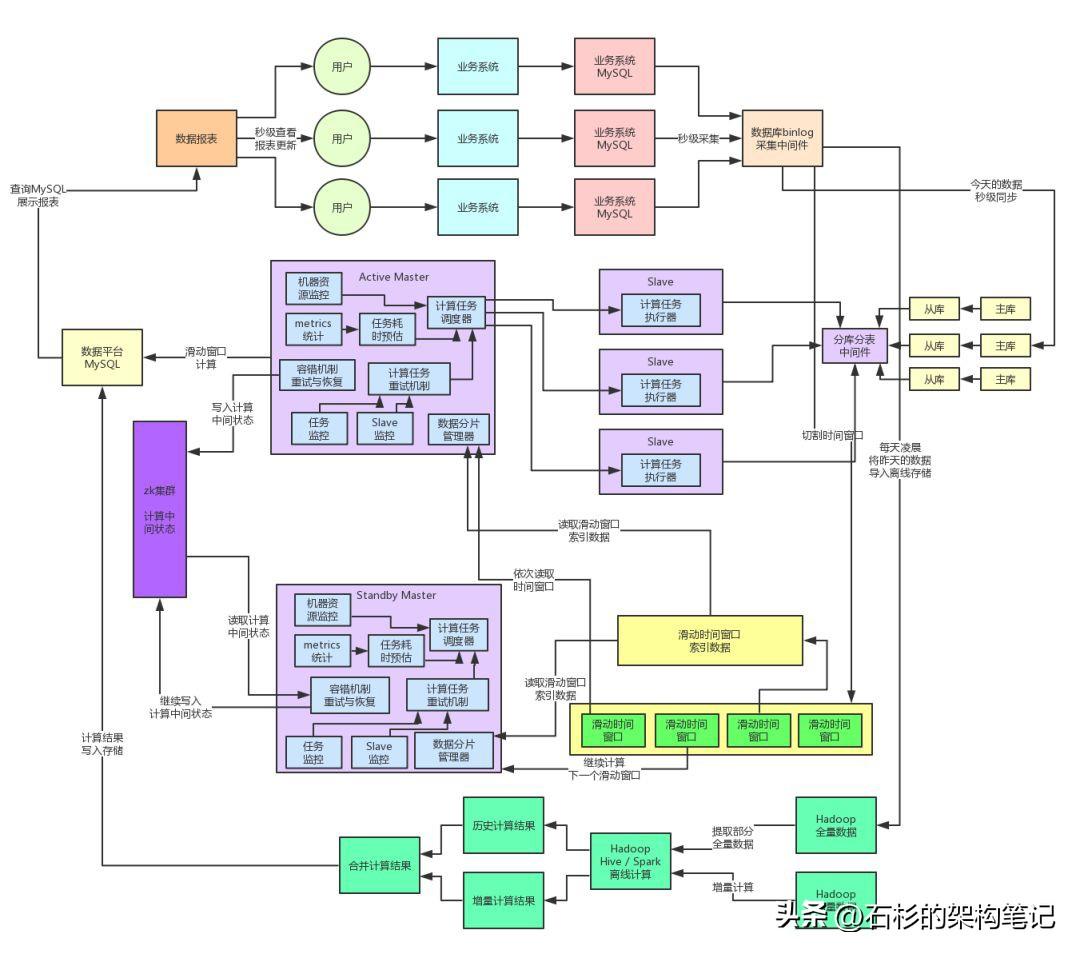
因此,Master節點內需要實現一套針對Slave節點計算任務調度的容錯機制,大體思路如下:
1.Master節點會監控各個計算任務的執行狀態,同時也會監控各個Slave節點的運行狀態
2.如果說某個Slave宕機了,那么此時Master就會將那個Slave沒執行完的計算任務重新分配給其他的Slave節點
3.如果說某個Slave的計算任務執行失敗了,同時重試幾次之后還是失敗,那么Master會將這個計算任務重新分配給其他的Slave節點來執行
4.如果說某個計算任務在多個Slave中無法成功計算的話,此時會將這個計算任務儲存在一個延時內存隊列中,間隔一段時間過后,比如說等待高峰期故去,然后再重新嘗試執行這個計算任務
5.如果某個計算任務等待很長時間都沒成功執行,可能是hang死了,那么Master節點會更新這個計算任務的版本號,然后分配計算任務給其他的Slave節點來執行。
6.之所以要更新版本號,是為了避免說,新分配的Slave執行完畢寫入結果之后,之前的那個Slave hang死了一段時間恢復了,接著將計算結果寫入存儲覆蓋正確的結果。用版本號機制可以避免這種情況的發生。
六、階段性總結
系統架構到這個程度為止,其實在當時而言是運行的相當不錯的,每日億級的請求以及數據場景下,這套系統架構都能承載的很好,如果寫數據庫并發更高可以隨時加更多的主庫,如果讀并發過高可以隨時加更多的從庫,同時單表數據量過大了就分更多的表,Slave計算節點也可以隨時按需擴容。
計算性能也是可以在這個請求量級和數據量級下保持很高的水準,因為數據分片計算引擎(滑動窗口)可以保證計算性能在秒級完成。同時各個Slave計算節點的負載都可以通過彈性資源調度機制保持的非常的均衡。
另外整套分布式系統還實現了高可用以及高容錯的機制,Master節點是Active-Standby架構可以自動故障轉移,Slave節點任何故障都會被Master節點感知到同時自動重試計算任務。
七、下一個階段的展望
其實如果僅僅只是每天億級的流量請求過來,這套架構是可以撐住了,但是問題是,隨之接踵而來的,就是每天請求流量開始達到數十億次甚至百億級的請求量,此時上面那套架構又開始支撐不住了,需要繼續重構和演進系統架構。