自研ES+HBase+純內(nèi)存的高性能毫秒級(jí)查詢引擎

一、前情回顧
上篇文章(《??億流量大考(3):不加機(jī)器,如何抗住每天百億級(jí)高并發(fā)流量???》)聊了一下系統(tǒng)架構(gòu)中,百億流量級(jí)別高并發(fā)寫入場(chǎng)景下,如何承載這種高并發(fā)寫入,同時(shí)如何在高并發(fā)寫入的背景下還能保證系統(tǒng)的超高性能計(jì)算。
這篇文章咱們繼續(xù)來(lái)聊一下,百億級(jí)別的海量數(shù)據(jù)場(chǎng)景下還要支撐每秒十萬(wàn)級(jí)別的高并發(fā)查詢,這個(gè)架構(gòu)該如何演進(jìn)和設(shè)計(jì)?
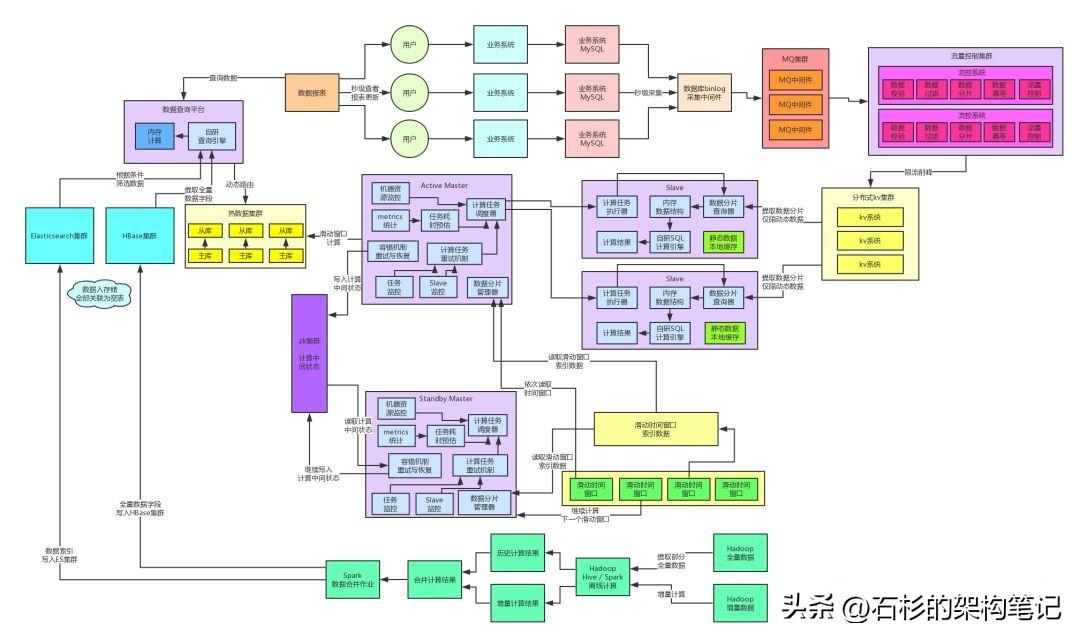
咱們先來(lái)看看目前系統(tǒng)已經(jīng)演進(jìn)到了什么樣的架構(gòu),大家看看下面的圖:
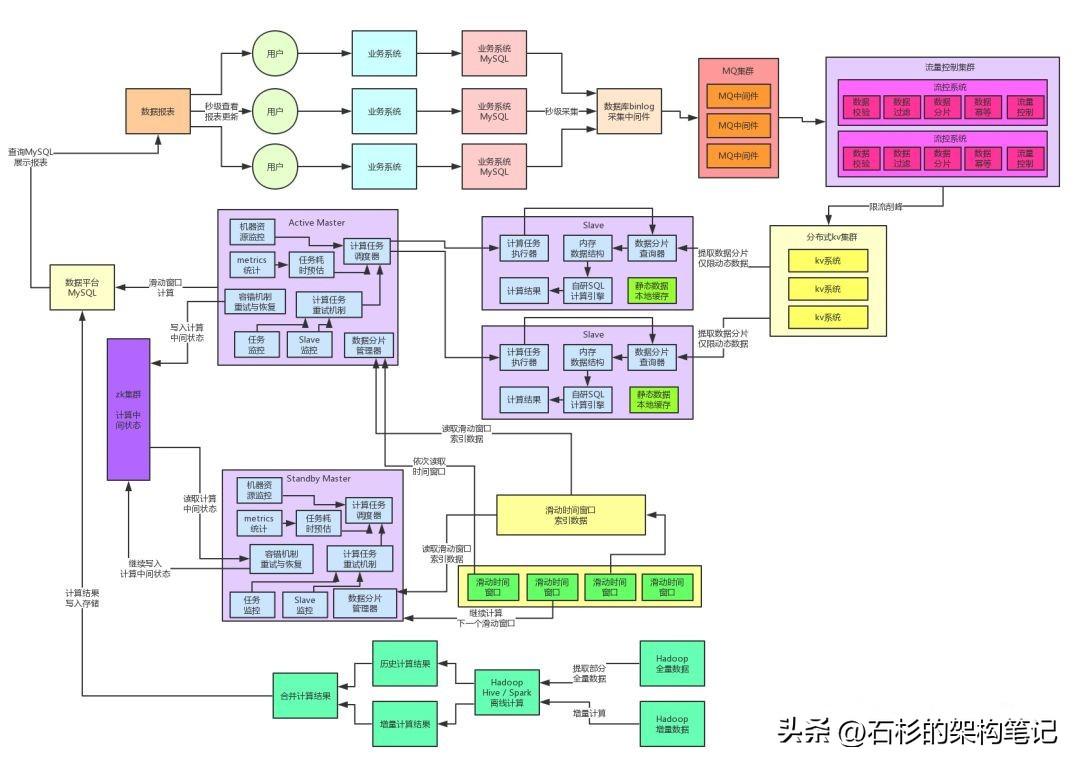
首先回顧一下,整個(gè)架構(gòu)右側(cè)部分演進(jìn)到的那個(gè)程度,其實(shí)已經(jīng)非常的不錯(cuò)了,因?yàn)榘賰|流量,每秒十萬(wàn)級(jí)并發(fā)寫入的場(chǎng)景,使用MQ限流削峰、分布式KV集群給抗住了。
接著使用了計(jì)算與存儲(chǔ)分離的架構(gòu),各個(gè)Slave計(jì)算節(jié)點(diǎn)會(huì)負(fù)責(zé)提取數(shù)據(jù)到內(nèi)存中,基于自研的SQL內(nèi)存計(jì)算引擎完成計(jì)算。同時(shí)采用了數(shù)據(jù)動(dòng)靜分離的架構(gòu),靜態(tài)數(shù)據(jù)全部緩存,動(dòng)態(tài)數(shù)據(jù)自動(dòng)提取,保證了盡可能把網(wǎng)絡(luò)請(qǐng)求開銷降低到最低。
另外,通過(guò)自研的分布式系統(tǒng)架構(gòu),包括數(shù)據(jù)分片和計(jì)算任務(wù)分布式執(zhí)行、彈性資源調(diào)度、分布式高容錯(cuò)機(jī)制、主備自動(dòng)切換機(jī)制,都能保證整套系統(tǒng)的任意按需擴(kuò)容,高性能、高可用的的運(yùn)行。
下一步,咱們來(lái)研究研究架構(gòu)里的左側(cè)部分。
二、日益膨脹的離線計(jì)算結(jié)果
其實(shí)大家會(huì)注意到,在左側(cè)還有一個(gè)MySQL,那個(gè)MySQL就是用來(lái)承載實(shí)時(shí)計(jì)算結(jié)果和離線計(jì)算結(jié)果放在里面匯總的。
終端的商家用戶就可以隨意的查詢MySQL里的數(shù)據(jù)分析結(jié)果,支撐自己的決策,他可以看當(dāng)天的數(shù)據(jù)分析報(bào)告,也可以看歷史上任何一段時(shí)期內(nèi)的數(shù)據(jù)分析報(bào)告。
但是那個(gè)MySQL在早期可能還好一些,因?yàn)槠鋵?shí)存放在這個(gè)MySQL里的數(shù)據(jù)量相對(duì)要小一些,畢竟是計(jì)算后的一些結(jié)果罷了。但是到了中后期,這個(gè)MySQL可是也岌岌可危了。
給大家舉一個(gè)例子,離線計(jì)算鏈路里,如果每天增量數(shù)據(jù)是1000萬(wàn),那么每天計(jì)算完以后的結(jié)果大概只有50萬(wàn),每天50萬(wàn)新增數(shù)據(jù)放入MySQL,其實(shí)還是可以接受的。
但是如果每天增量數(shù)據(jù)是10億,那么每天計(jì)算完以后的結(jié)果大致會(huì)是千萬(wàn)級(jí),你可以算他是計(jì)算結(jié)果有5000萬(wàn)條數(shù)據(jù)吧,每天5000萬(wàn)增量數(shù)據(jù)寫入左側(cè)的MySQL中,你覺得是啥感覺?
可以給大家說(shuō)說(shuō)系統(tǒng)當(dāng)時(shí)的情況,基本上就是,單臺(tái)MySQL服務(wù)器的磁盤存儲(chǔ)空間很快就要接近滿掉,而且單表數(shù)據(jù)量都是幾億、甚至十億的級(jí)別。
這種量級(jí)的單表數(shù)據(jù)量,你覺得用戶查詢數(shù)據(jù)分析報(bào)告的時(shí)候,體驗(yàn)?zāi)芎妹矗炕井?dāng)時(shí)一次查詢都是幾秒鐘的級(jí)別。很慢。
更有甚者,出現(xiàn)過(guò)用戶一次查詢要十秒的級(jí)別,甚至幾十秒,上分鐘的級(jí)別。很崩潰,用戶體驗(yàn)很差,遠(yuǎn)遠(yuǎn)達(dá)不到付費(fèi)產(chǎn)品的級(jí)別。
所以解決了右側(cè)的存儲(chǔ)和計(jì)算的問題之后,左側(cè)的查詢的問題也迫在眉睫。新一輪的重構(gòu),勢(shì)在必行!
三、分庫(kù)分表 + 讀寫分離
首先就是老一套,分庫(kù)分表 + 讀寫分離,這個(gè)基本是基于MySQL的架構(gòu)中,必經(jīng)之路了,畢竟實(shí)施起來(lái)難度不是特別的高,而且速度較快,效果比較顯著。
整個(gè)的思路和之前第一篇文章(《?億流量大考(1):日增上億數(shù)據(jù),把MySQL直接搞宕機(jī)了...?》)講的基本一致。
說(shuō)白了,就是分庫(kù)后,每臺(tái)主庫(kù)可以承載部分寫入壓力,單庫(kù)的寫并發(fā)會(huì)降低;其次就是單個(gè)主庫(kù)的磁盤空間可以降低負(fù)載的數(shù)據(jù)量,不至于很快就滿了;
而分表之后,單個(gè)數(shù)據(jù)表的數(shù)據(jù)量可以降低到百萬(wàn)級(jí)別,這個(gè)是支撐海量數(shù)據(jù)以及保證高性能的最佳實(shí)踐,基本兩三百萬(wàn)的單表數(shù)據(jù)量級(jí)還是合理的。
然后讀寫分離之后,就可以將單庫(kù)的讀寫負(fù)載壓力分離到主庫(kù)和從庫(kù)多臺(tái)機(jī)器上去,主庫(kù)就承載寫負(fù)載,從庫(kù)就承載讀負(fù)載,這樣避免單庫(kù)所在機(jī)器的讀寫負(fù)載過(guò)高,導(dǎo)致CPU負(fù)載、IO負(fù)載、網(wǎng)絡(luò)負(fù)載過(guò)高,最后搞得數(shù)據(jù)庫(kù)機(jī)器宕機(jī)。
首先這么重構(gòu)一下數(shù)據(jù)庫(kù)層面的架構(gòu)之后,效果就好得多了。因?yàn)閱伪頂?shù)據(jù)量降低了,那么用戶查詢的性能得到很大的提升,基本可以達(dá)到1秒以內(nèi)的效果。
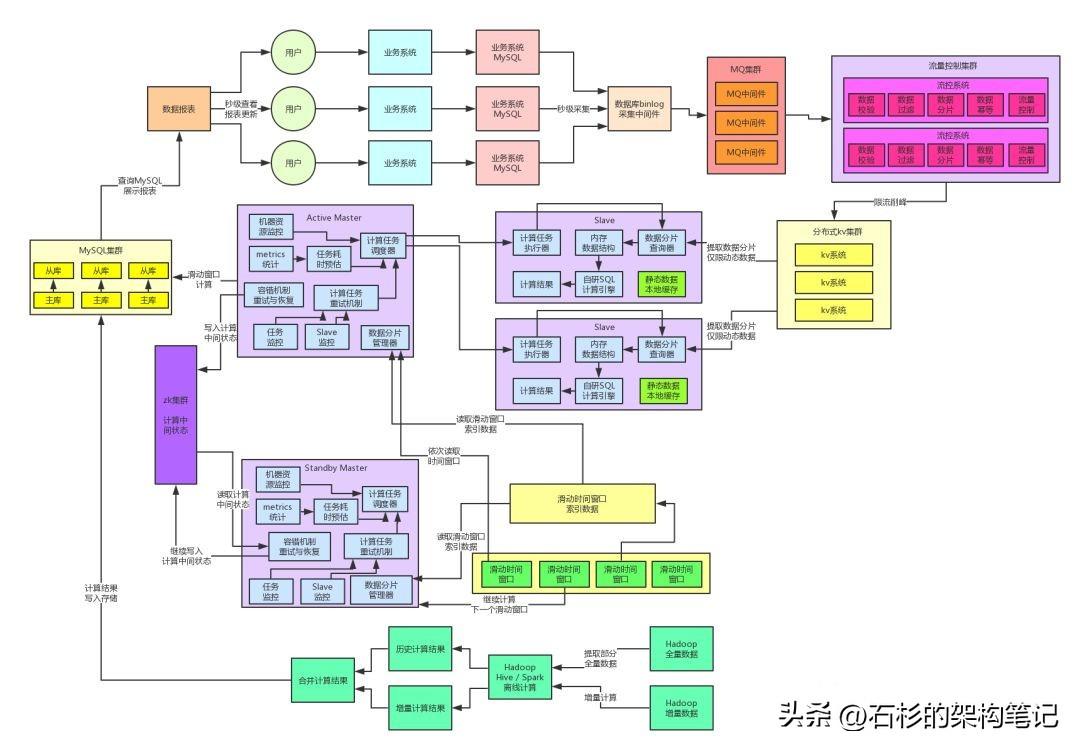
四、每秒10萬(wàn)查詢的高并發(fā)挑戰(zhàn)
上面那套初步的分庫(kù)分表+讀寫分離的架構(gòu)確實(shí)支撐了一段時(shí)間,但是慢慢的那套架構(gòu)又暴露出來(lái)了弊端出來(lái)了,因?yàn)樯碳矣脩舳际情_了數(shù)據(jù)分析頁(yè)面之后,頁(yè)面上有js腳本會(huì)每隔幾秒鐘就發(fā)送一次請(qǐng)求到后端來(lái)加載最新的數(shù)據(jù)分析結(jié)果。
此時(shí)就有一個(gè)問題了,漸漸的查詢MySQL的壓力越來(lái)越大,基本上可預(yù)見的范圍是朝著每秒10級(jí)別去走。
但是我們分析了一下,其實(shí)99%的查詢,都是頁(yè)面JS腳本自動(dòng)發(fā)出刷新當(dāng)日數(shù)據(jù)的查詢。只有1%的查詢是針對(duì)昨天以前的歷史數(shù)據(jù),用戶手動(dòng)指定查詢范圍后來(lái)查詢的。
但是現(xiàn)在的這個(gè)架構(gòu)之下,我們是把當(dāng)日實(shí)時(shí)數(shù)據(jù)計(jì)算結(jié)果(代表了熱數(shù)據(jù))和歷史離線計(jì)算結(jié)果(代表了冷數(shù)據(jù))都放在一起的,所以大家可以想象一下,熱數(shù)據(jù)和冷數(shù)據(jù)放在一起,然后對(duì)熱數(shù)據(jù)的高并發(fā)查詢占到了99%,那這樣的架構(gòu)還合理嗎?
當(dāng)然不合理,我們需要再次重構(gòu)系統(tǒng)架構(gòu)。
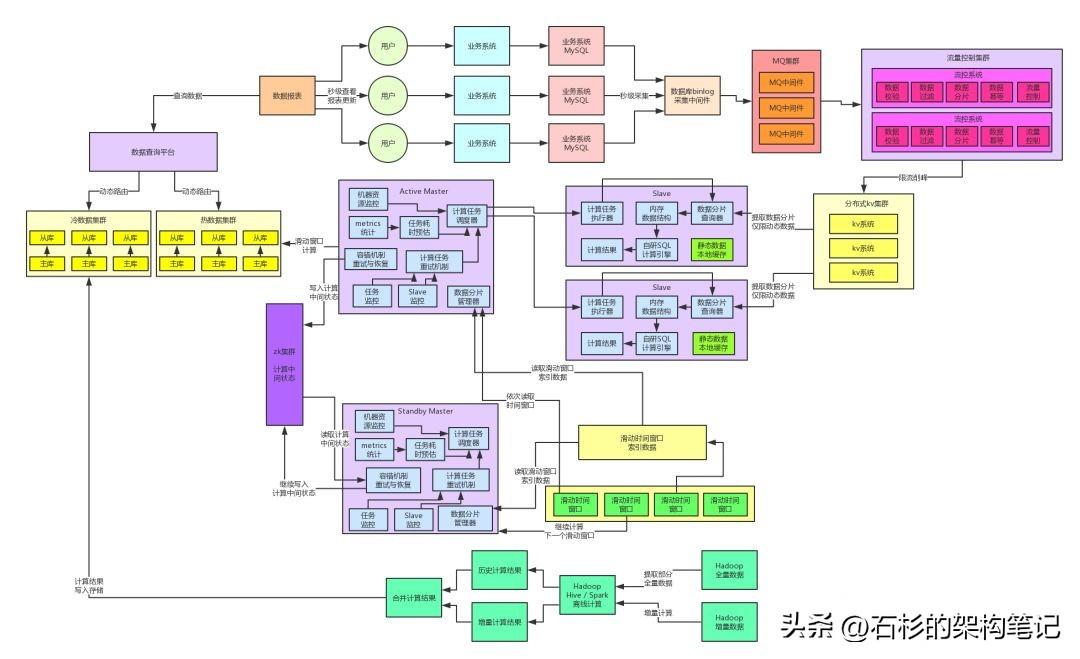
五、 數(shù)據(jù)的冷熱分離架構(gòu)
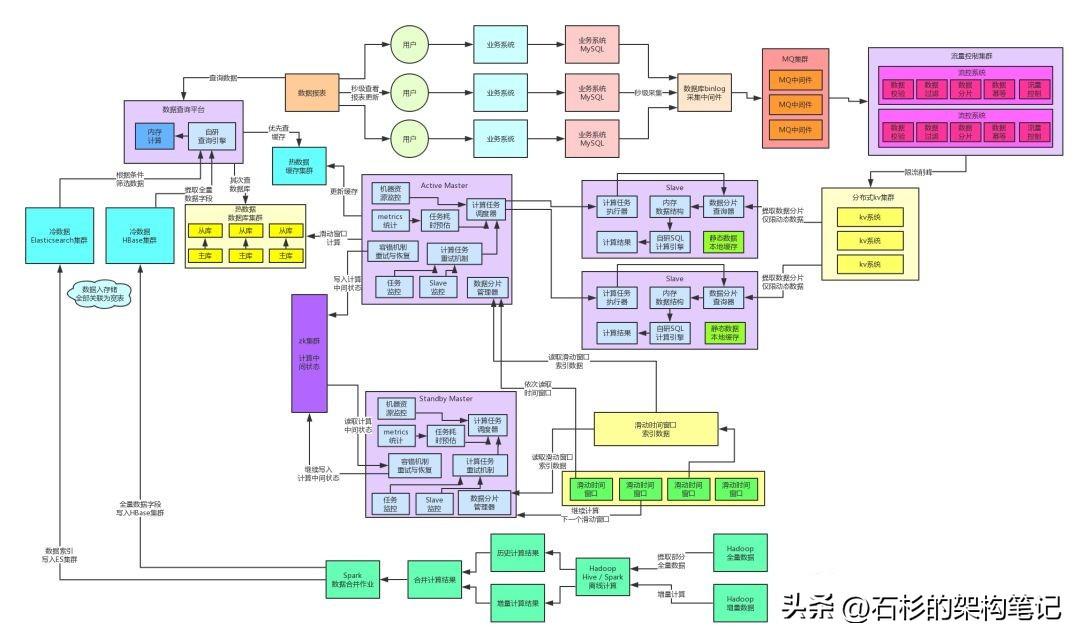
針對(duì)上述提到的問題,很明顯要做的一個(gè)架構(gòu)重構(gòu)就是冷熱數(shù)據(jù)分離。也就是說(shuō),將今日實(shí)時(shí)計(jì)算出來(lái)的熱數(shù)據(jù)放在一個(gè)MySQL集群里,將離線計(jì)算出來(lái)的冷數(shù)據(jù)放在另外一個(gè)MySQL集群里。
然后開發(fā)一個(gè)數(shù)據(jù)查詢平臺(tái),封裝底層的多個(gè)MySQL集群,根據(jù)查詢條件動(dòng)態(tài)路由到熱數(shù)據(jù)存儲(chǔ)或者是冷數(shù)據(jù)存儲(chǔ)。
通過(guò)這個(gè)步驟的重構(gòu),我們就可以有效地將熱數(shù)據(jù)存儲(chǔ)中單表的數(shù)據(jù)量降低到更少更少,有的單表數(shù)據(jù)量可能就幾十萬(wàn),因?yàn)閷㈦x線計(jì)算的大量數(shù)據(jù)結(jié)果從表里剝離出去了,放到另外一個(gè)集群里去。此時(shí)大家可想而知,效果當(dāng)然是更好了。
因?yàn)闊釘?shù)據(jù)的單表數(shù)據(jù)量減少了很多,當(dāng)時(shí)的一個(gè)最明顯的效果,就是用戶99%的查詢都是針對(duì)熱數(shù)據(jù)存儲(chǔ)發(fā)起的,性能從原來(lái)的1秒左右降低到了200毫秒以內(nèi),用戶體驗(yàn)提升,大家感覺更好了。
六、自研Elasticsearch+HBase+純內(nèi)存的查詢引擎
架構(gòu)演進(jìn)到這里,看起來(lái)好像還不錯(cuò),但是其實(shí)問題還是很多。因?yàn)榈搅诉@個(gè)階段,系統(tǒng)遇到了另外一個(gè)較為嚴(yán)重的問題:冷數(shù)據(jù)存儲(chǔ),如果完全用MySQL來(lái)承載是很不靠譜的。冷數(shù)據(jù)的數(shù)據(jù)量是日增長(zhǎng)不斷增加,而且增速很快,每天都新增幾千萬(wàn)。
因此你的MySQL服務(wù)器將會(huì)面臨不斷的需要擴(kuò)容的問題,而且如果為了支撐這1%的冷數(shù)據(jù)查詢請(qǐng)求,不斷的擴(kuò)容增加高配置的MySQL服務(wù)器,大家覺得靠譜么?
肯定是不合適的!
要知道,大量分庫(kù)分表后,MySQL大量的庫(kù)和表維護(hù)起來(lái)是相當(dāng)麻煩的,修改個(gè)字段?加個(gè)索引?這都是一場(chǎng)麻煩事兒。
此外,因?yàn)閷?duì)冷數(shù)據(jù)的查詢,一般都是針對(duì)大量數(shù)據(jù)的查詢,比如用戶會(huì)選擇過(guò)去幾個(gè)月,甚至一年的數(shù)據(jù)進(jìn)行分析查詢,此時(shí)如果純用MySQL還是挺災(zāi)難性的。
因?yàn)楫?dāng)時(shí)明顯發(fā)現(xiàn),針對(duì)海量數(shù)據(jù)場(chǎng)景下,一下子查詢分析幾個(gè)月或者幾年的數(shù)據(jù),性能是極差的,還是很容易搞成幾秒甚至幾十秒才出結(jié)果。
因此針對(duì)這個(gè)冷數(shù)據(jù)的存儲(chǔ)和查詢的問題,我們最終選擇了自研一套基于NoSQL來(lái)存儲(chǔ),然后基于NoSQL+內(nèi)存的SQL計(jì)算引擎。
具體來(lái)說(shuō),我們會(huì)將冷數(shù)據(jù)全部采用ES+HBase來(lái)進(jìn)行存儲(chǔ),ES中主要存放要對(duì)冷數(shù)據(jù)進(jìn)行篩選的各種條件索引,比如日期以及各種維度的數(shù)據(jù),然后HBase中會(huì)存放全量的數(shù)據(jù)字段。
因?yàn)镋S和HBase的原生SQL支持都不太好,因此我們直接自研了另外一套SQL引擎,專門支持這種特定的場(chǎng)景,就是基本沒有多表關(guān)聯(lián),就是對(duì)單個(gè)數(shù)據(jù)集進(jìn)行查詢和分析,然后支持NoSQL存儲(chǔ)+內(nèi)存計(jì)算。
這里有一個(gè)先決條件,就是如果要做到對(duì)冷數(shù)據(jù)全部是單表類的數(shù)據(jù)集查詢,必須要在冷數(shù)據(jù)進(jìn)入NoSQL存儲(chǔ)的時(shí)候,全部基于ES和HBase的特性做到多表入庫(kù)關(guān)聯(lián),進(jìn)數(shù)據(jù)存儲(chǔ)就全部做成大寬表的狀態(tài),將數(shù)據(jù)關(guān)聯(lián)全部上推到入庫(kù)時(shí)完成,而不是在查詢時(shí)進(jìn)行。
對(duì)冷數(shù)據(jù)的查詢,我們自研的SQL引擎首先會(huì)根據(jù)各種where條件先走ES的分布式高性能索引查詢,ES可以針對(duì)海量數(shù)據(jù)高性能的檢索出來(lái)需要的那部分?jǐn)?shù)據(jù),這個(gè)過(guò)程用ES做是最合適的。
接著就是將檢索出來(lái)的數(shù)據(jù)對(duì)應(yīng)的完整的各個(gè)數(shù)據(jù)字段,從HBase里提取出來(lái),拼接成完成的數(shù)據(jù)。
然后就是將這份數(shù)據(jù)集放在內(nèi)存里,進(jìn)行復(fù)雜的函數(shù)計(jì)算、分組聚合以及排序等操作。
上述操作,全部基于自研的針對(duì)這個(gè)場(chǎng)景的查詢引擎完成,底層基于Elasticsearch、HBase、純內(nèi)存來(lái)實(shí)現(xiàn)。
七、實(shí)時(shí)數(shù)據(jù)存儲(chǔ)引入緩存集群
好了,到此為止,冷數(shù)據(jù)的海量數(shù)據(jù)存儲(chǔ)、高性能查詢的問題,就解決了。接著回過(guò)頭來(lái)看看當(dāng)日實(shí)時(shí)數(shù)據(jù)的查詢,其實(shí)實(shí)時(shí)數(shù)據(jù)的每日計(jì)算結(jié)果不會(huì)太多,而且寫入并發(fā)不會(huì)特別特別的高,每秒上萬(wàn)也就差不多了。
因此這個(gè)背景下,就是用MySQL分庫(kù)分表來(lái)支撐數(shù)據(jù)的寫入、存儲(chǔ)和查詢,都沒問題。
但是有一個(gè)小問題,就是說(shuō)每個(gè)商家的實(shí)時(shí)數(shù)據(jù)其實(shí)不是頻繁的變更的,在一段時(shí)間內(nèi),可能壓根兒沒變化,因此不需要高并發(fā)請(qǐng)求,每秒10萬(wàn)級(jí)別的全部落地到數(shù)據(jù)庫(kù)層面吧?要全都落地到數(shù)據(jù)庫(kù)層面,那可能要給每個(gè)主庫(kù)掛載很多從庫(kù)來(lái)支撐高并發(fā)讀。
因此這里我們引入了一個(gè)緩存集群,實(shí)時(shí)數(shù)據(jù)每次更新后寫入的時(shí)候,都是寫數(shù)據(jù)庫(kù)集群同時(shí)還寫緩存集群的,是雙寫的方式。
然后查詢的時(shí)候是優(yōu)先從緩存集群來(lái)走,此時(shí)基本上90%以上的高并發(fā)查詢都走緩存集群了,然后只有10%的查詢會(huì)落地到數(shù)據(jù)庫(kù)集群。
八、階段性總結(jié)
好了,到此為止,這個(gè)架構(gòu)基本左邊也都重構(gòu)完畢:
- 熱數(shù)據(jù)基于緩存集群+數(shù)據(jù)庫(kù)集群來(lái)承載高并發(fā)的每秒十萬(wàn)級(jí)別的查詢。
- 冷數(shù)據(jù)基于ES+HBase+內(nèi)存計(jì)算的自研查詢引擎來(lái)支撐海量數(shù)據(jù)存儲(chǔ)以及高性能查詢。
經(jīng)實(shí)踐,整個(gè)效果非常的好。用戶對(duì)熱數(shù)據(jù)的查詢基本多是幾十毫秒的響應(yīng)速度,對(duì)冷數(shù)據(jù)的查詢基本都是200毫秒以內(nèi)的響應(yīng)速度。
九、下一階段的展望
其實(shí)架構(gòu)演進(jìn)到這里已經(jīng)很不容易了,因?yàn)榭此七@么一張圖,里面涉及到無(wú)數(shù)的細(xì)節(jié)和技術(shù)方案的落地,需要一個(gè)團(tuán)隊(duì)耗費(fèi)至少1年的時(shí)間才能做到這個(gè)程度。
但是接下來(lái),我們要面對(duì)的,就是高可用的問題,因?yàn)楦顿M(fèi)級(jí)的產(chǎn)品,我們必須要保證超高的可用性,99.99%的可用性,甚至是99.999%的可用性。