微信自研高性能推理計算引擎 XNet-DNN:跨平臺 GPU 部署大語言模型及優化實踐
作者 | yannic
XNet-DNN 是微信高性能計算團隊自主研發的一款全平臺神經網絡推理引擎。我們在 XNet 的 RCI 基礎設施之上構建了全平臺的 GPU LLM 推理能力。目前能夠在:
Apple/NVIDIA/AMD/Intel/Qualcomm/MTK/Huawei 等主流硬件廠商的 GPU 上實現非常優秀的推理性能,能夠支持在 Windows/Linux/MacOS/ios/Android/HarmonyOS 等操作系統上部署。本文深入解析該引擎的核心技術架構,以及在異構計算環境下的性能優化策略。通過與主流 LLM 推理框架(llama.cpp, 英偉達 TRT-LLM,蘋果 MLX-LM 等)全面比較,XNet-DNN 在推理效率、內存占用以及包體大小等關鍵性能指標上均顯著超越現有解決方案。

一、GPU 的跨平臺統一:XNet-DNN 高效推理實踐
大模型技術的規模化應用正呈現爆發式增長態勢,持續驅動人工智能技術體系革新。在此背景下,XNet-DNN 推理引擎基于自主研發的 RCI(Render and Compute Interface)跨平臺框架構建了跨平臺的 GPU LLM 推理能力。該引擎目前已實現對 NVIDIA、AMD、Apple、Intel、Qualcomm、聯發科、華為等主流硬件平臺的全面支持。在推理效率、內存占用以及包體積等關鍵性能指標上均顯著超越現有解決方案,為各業務線部署高效的 LLM 推理服務提供了強有力的支持。我們曾系統闡述過移動端 CPU 部署大模型的技術路徑。本文作為該技術路線的延續,重點聚焦 GPU 加速場景下的 LLM 推理優化,從 RCI 框架的系統級優化到核心算子的極致調優,系統闡述實現大模型 GPU 推理極致性能的技術路徑。本文末章給出了詳實的對比實驗數據,包括 QwQ-32B 模型的本地部署性能指標。
1. GPU 發展與現狀
自 NVIDIA 于 1999 年發布首代圖形處理器 GeForce 256 至 2024 年 Blackwell 架構問世,GPU 技術經歷了 26 年技術演進。晶體管集成度從 68M 提升至 104B,單精度浮點算力增幅達 5400 倍,內存帶寬擴展幅度超 95 倍。這種持續四分之一個世紀的技術迭代,使 GPU 完成從圖形加速單元向人工智能核心計算架構的轉變。值得關注的是,在 Blackwell 架構突破 14 PFLOPS 算力峰值的產業熱點背后,以 Apple M 系列的 GPU、高通的 Adreno GPU、Arm 的 Mali GPU 為代表的移動 GPU 正推動計算范式發生結構性轉變——人工智能加速架構不斷向邊緣側大規模滲透。這些廣泛分布的邊緣計算設備,其架構差異性、能效約束性及內存局限性等特征,使模型部署面臨多維度的挑戰。

表1. GPU 硬件信息
表 1 展示了 GPU 生態的現狀:
- 硬件性能差異巨大: 帶寬差異達 26 倍; 峰值算力差距達 71 倍
- 硬件架構分化: NVIDIA 的 TensorCore 與 Adreno 的可編程著色器的計算架構分化; HBM3 與 LPDDR5X 的存儲架構分化
- 編程生態碎片化: CUDA (NVIDIA)、Metal (Apple)、ROCm (AMD), OpenCL 等編程框架并存; 現代 GPU 特性支持情況各不相同
- 部署需求分化: 云端需支持千億、萬億參數大模型的分布式計算; 移動端需要在 10 W 功耗下實現數十億參數模型的實時推理
2. LLM GPU 推理現狀
表 2 展示了目前 LLM 推理的現狀,各框架部署能力各有千秋,很難找到一款高效的,支持全平臺部署且適應實際業務場景的推理框架。
在此背景下,我們利用 RCI 完善的現代 GPU 特性支持,以及高效的編程框架,開發了全平臺的 GPU LLM 推理引擎。同時,基于硬件性能上限,對核心算子進行極致優化,在各端都取得了非常優秀的推理表現。下文將從系統優化及算子優化兩個維度闡述 XNet-DNN 是如何構建高性能的跨平臺 GPU LLM 推理引擎的。

表2. 現有方案
二、突破 GPU 生態瓶頸:RCI 的系統優化之道
1. RCI 計算架構概覽
GPU 開發領域當前面臨顯著的生態碎片化挑戰,主要體現在以下三個技術層面:
- 首先,在驅動層存在多套編程標準。主流圖形 API 包括跨平臺的 OpenGL/Vulkan、Windows平臺的 Direct3D、蘋果生態的 Metal,以及面向通用計算的 CUDA/OpenCL。這些 API 在功能特性、執行模型和內存管理機制方面存在顯著差異。
- 其次,kernel 編程語言也分化嚴重包括 GLSL、HLSL、MSL、CUDA C、OpenCL C 等,這些語言在語法規范、編譯工具鏈和運行時支持方面缺乏統一標準。
- 最后,硬件指令集層面也存在明顯分化。不同廠商 GPU 在計算單元設計、存儲層級結構和特殊功能單元等方面采用不同的技術方案,例如 NVIDIA 在硬件上增加矩陣計算單元 (TensorCore),開發者可以使用對應的矩陣計算指令獲得更高的矩陣計算算力, Apple 及 Arm 僅在軟件層面支持矩陣計算指令(硬件沒有添加矩陣計算單元),Qualcomm 不支持矩陣計算指令;另外,例如 shared memory 的支持在移動端 GPU 上普遍較差。這些差異導致開發者需針對特定硬件進行深度優化。
以上現狀顯著增加了 GPU 應用開發的復雜度,其情形類似于 CPU 領域早期需直接面向 x86、ARM 等不同指令集架構進行底層開發的困境。值得關注的是,在 CPU 領域已形成統一的高級語言編程體系(如 C++、Java 等),而 GPU 領域尚未出現具有同等普適性的高級工具。
針對這一技術瓶頸,RCI 框架構建了跨平臺的 GPU 高級編程范式。
RCI 在 API 設計層面以接近原生 API 為宗旨,可以有效降低學習成本,同時要求運行時相對于原生 API 達到零開銷。架構設計上充分考慮各 GPU 架構編程的最佳實踐,保證開發者采用預計算,預編譯狀態與管線等方式提高 GPU 在渲染、計算等場景中的管線吞吐。RCI 的 Command Tape 機制就很好的詮釋了這一特點,它能夠以最高效的方式提交命令,節省 GPU 啟動、驅動以及設備執行的開銷,有效提高了管線吞吐,下文我們將詳細介紹。
RCI 在 kernel 開發層面,借助自研的反編譯器(其中 CL/CUDA/ROCm 反編譯是業內首創)實現了高級語言到原生 kernel 語法的轉換,避免了大量的重復開發工作,同時有效降低了包體積。為了實現高性能與通用性的平衡,RCI 支持開發者嵌入手工優化的原生 kernel 代碼(MSL/CUDA C/OpenCL C)或者匯編代碼(PTX/SASS/GCN),以實現特定硬件上的最佳性能。
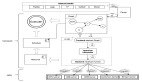
值得強調的是,RCI 架構與 CPU 高級編程語言設計理念存在顯著共性:在基礎功能層,兩者均采用高級抽象語言(C++ / RCI)保障開發效率與可移植性;在關鍵性能路徑,則通過底層指令集(匯編/Native kernel)實現硬件級深度優化。二者均采用"通用框架+底層優化"的混合編程模型,有效平衡了通用性與高性能之間的矛盾,既提升了應用的跨平臺開發效率,又能利用平臺特性保持其高性能。圖 1 展示了 RCI 計算部分的核心架構。

圖1. RCI 計算架構概覽
RCI 作為復雜系統設計領域的突破性創新框架,上文論述所揭示的僅是冰山一角。我們將在后續的文章中詳細向大家展示 RCI 的全貌,以及其在系統優化中卓越的表現。
2. RCI 開發優勢
從項目生態來看, llama.cpp 社區擁有近千名貢獻者,其中代碼貢獻量超萬行的核心開發者近 30 位,其硬件適配能力主要依賴廠商團隊的直接投入,例如 Intel 和 Qualcomm 分別主導了 SYCL 與 OpenCL 后端開發,阿里巴巴等機構也參與其模型生態支持。然而,XNet-DNN 僅投入很少的開發資源實現了更廣泛的 GPU 硬件覆蓋與更優的推理性能,圖 2 展示了 XNet-DNN 與開源項目 llama.cpp 的代碼規模及開發者效率對比。

圖2. XNet LLM(GPU) 與 LLama.cpp 代碼量對比
我們能夠以更少的人力完成更優秀的更全面的工作,其關鍵在于 RCI 架構設計的雙重創新:
(1) 跨平臺特性降低開發冗余
借助 RCI 的跨平臺特性,框架實現僅需一套邏輯,有效降低框架代碼量。kernel 部分,非核心計算邏輯(如內存布局轉換)可借助 RCI 編寫通用實現,無需針對各平臺重復開發。大幅減少開發工作量,也有效降低了包體積。表 3 展示了 XNet-DNN 的包體積與其他主流推理框架的對比。對于移動端等包體積敏感場景,XNet-DNN 有巨大優勢。

表3 包體積對比
(2) 差異化策略平衡性能與效率
RCI kernel 支持兩種開發模式:采用高級語言編寫跨平臺通用 kernel,或使用原生語言(如 Metal Shading Language/CUDA C/PTX/SASS/GCN)編寫硬件專用 kernel。對于硬件特性差異顯著的核心算子(如矩陣計算),采用專用 kernel 實現極致性能;共性操作則通過通用 kernel 提升開發效率,實現了開發工作量與應用高性能之間的有效平衡。
憑借 RCI 優秀的框架設計,使我們得以聚焦核心算子的深度優化,最終以極小的人力規模完成對 Apple、NVIDIA、AMD、Intel、Qualcomm、Mali、 Maleoon 等主流 GPU 的覆蓋并取得超越業界的性能,人效比遠高于傳統開發方式。
3. RCI Command Tape 特性
GPU 的執行需要宿主機 CPU 參與大量工作。CPU 作為主處理器負責邏輯調度和命令序列構建,通過總線向 GPU 設備提交結構化的命令隊列。這種提交過程涉及指令預編譯、資源綁定、內存屏障同步以及上下文狀態的維護。以上是 CPU 提交 GPU 命令的核心機制。
在推理任務中,典型的執行流程是由多個 kernel 組成一個隊列,每個計算幀執行相同的隊列。在傳統 GPU 執行機制下,每個計算幀都需要驅動層對隊列中所有 kernel 執行完整的指令預編譯和資源綁定流程,硬件指令緩沖區需要反復構建。這一過程 CPU 重復執行大量的相同任務,造成 CPU 負載及功耗顯著增加,一些場景下計算管線的端到端延遲甚至受限于 CPU 性能。
RCI 的 Command Tape 技術有效解決了這一瓶頸。 該技術提供了一種跨平臺的命令預錄制機制,預先錄制命令隊列,指令預編譯和資源綁定等操作只在預錄制時執行一次,后續計算幀的處理,只需要提交預錄制命令隊列即可,有效降低 CPU 負載和功耗,也能夠更好的提高 GPU 管線的吞吐。該技術實現了與 Metal 的 Indirect Command Buffer、NVIDIA CUDA Graphs 以及 Adreno Recordable Queue 等效的能力。
如圖 4 展示了在輕量級模型的推理任務中,decode 過程使用 CommandTape 技術所帶來的性能提升。。


圖4. Command Tape 在 iPhone (上) 及 Android (下) 設備的加速效果
三、榨取硬件潛能:核心算子的極致優化實踐
所謂工欲善其事,必先利其器。憑借對各種計算硬件體系結構的深入理解和長期實戰的經驗總結。我們開發了一套微基準測試(Micro-benchmark)工具,它可以幫助我們準確獲取硬件的算力峰值、各級存儲結構的帶寬以及延遲、指令吞吐、指令延遲以及一些硬件架構特點,這些信息大多數是硬件廠商不公開的,或者僅是理論數據。這些關鍵指標對于我們做性能優化非常關鍵,它可以幫助我們做數據排布,指令排布,實現最優的 pipeline 以獲得最優的帶寬利用率和算力利用率。同時,這套工具配合 Roofline 模型,可以快速準確的幫助我們定位到當前優化的瓶頸,以及當前優化距離最終目標還有多遠。這套方法論讓優化不再是玄學,所有的經驗可總結,可借鑒,可復現,幫助我們能夠有效的在不同的硬件上取得最優的性能。
1. 如何做算子優化
本節先簡單介紹一下,如何通過硬件指標配合 Roofline 模型來指導優化。圖 5 是根據 8 Gen2 的帶寬和算力畫出的 Roofline 模型。我們通過 Micro-benchmark 測出,GPU Memory 的帶寬為 60 GB/s, shared memory 的帶寬為 465 GB/s, FP16 算力為 4668.5 GFLOPs。縱軸是算力,單位為 GFLOP/s, 橫軸為計算密度,單位是 FLOPs/Bytes。圖中的紫色線條和藍色線條代表算力隨計算密度變化的趨勢。紫色垂線表示,按照 shared memory 的帶寬能力,要達到峰值算力,需要計算密度達到 10 及以上,藍色垂線表示,按照顯存帶寬能力,要達到峰值帶寬需要計算密度達到 77 及以上。以顯存帶寬衡量,當計算密度小于 77,該算子就屬于帶寬受限型算子,當計算密度大于 77, 該算子就屬于算力受限型算子。
如果一個算子已經是算力受限型算子,那么說明已經優化到極致了,我們是無法突破算力天花板的。然而由于帶寬更昂貴,絕大多數的情況,算子都會落在帶寬受限區域,此時為了達到硬件峰值,優化方向有兩個,其一是提高計算密度,其二是提高帶寬。以矩陣乘法為例,增大矩陣分塊,可以提高計算密度,這個過程中需要考慮寄存器數量限制,寄存器資源有限,過大的分塊導致可能會導致 register spill,性能反而會大幅下降;提高帶寬,則是通過使用 shared memory 以及提升 Cache 命中率,來降低訪存延遲。除此之外,我們需要根據 Micro-benchmark 獲取的計算及訪存指令延遲數據,合理的排布訪存指令和計算指令以達到相互掩蓋延遲,實現軟流水獲得最優的吞吐。可見算子優化是一種平衡之道,在有限的資源中,探尋一種最優的平衡,訪存指令與計算指令的平衡,寄存器占用與計算密度的平衡等等,為了實現這種微妙的平衡,準確的 Micro-benchmark 就顯得尤為重要,Micro-benchmark 數據越精準,就越能接近極限平衡也就是達到最優性能,反之則只能南轅北轍。

圖5. Qualcomm 8 Gen2 Roofline
除了 Micro-benchmark 和 Roofline 之外,我們優化最重要的基礎是計算機體系結構。只有深刻了解硬件的運行規則,才能憑借 Micro-benchmark 數據合理的分析瓶頸,配置資源;Roofline 則提供了一套評價機制,幫助我們衡量當前優化水準。
2. GEMM/GEMV 的優化
大語言模型的推理分為兩個階段,prefill 和 decode; 前者是對用戶 prompt 的處理階段,也就是 kv-cache 填充階段,后者是 token 生成階段。Decode 過程是迭代過程,每輪迭代生成一個 token,prefill 階段可以進行批處理,一次運行填充多組 kv-cache。所以大語言模型的 prefill 和 decode 是兩種不同類型的計算過程,prefill 階段的核心計算是矩陣乘法(GEMM),decode 階段的核心計算是矩陣向量乘(GEMV)。
從計算密度(Arithmetic Intensity)分析,GEMV 的理論上界為 2 FLOPs/Byte,GEMM 的計算密度則受分塊策略影響,其上限由寄存器容量等硬件資源決定。因此二者的優化方向也大不相同。GEMV 的計算密度固定,屬于純帶寬型算子,優化中需要關注帶寬以及 GPU 的 occupancy, 在帶寬方面需要滿足最基礎的訪存合并,同時為了更優的 occupancy,一般需要數據重排,以滿足 GPU 的訪問模式。作為帶寬型算子,最優實現是算子耗時與最大帶寬情況下的數據讀寫耗時相當,也就是說,訪存延遲完全掩蓋了計算延遲。我們知道,GPU 是通過大量 warp 并行執行,通過訪存和計算的相互掩蓋以保證硬件單元的持續繁忙,那么在 GEMV 的優化中除了考慮數據排布的最優,還需要考慮 GPU occupancy,常見的方案如 split k 等,下文介紹的 shuffle 指令就可以避免數據交互,有效加速 K 方向的 reduce 計算。GEMM 的優化則更加復雜,前文已經對 GEMM 優化的方向及核心要素有了詳細介紹,這里就不再展開。深度優化本身也是對基礎優化技巧和理論的的深度實踐,所以本節接下來會從硬件層級結構,如何提高GPU 并行度和帶寬優化等方面來向大家介紹一些基礎的優化技巧。
(1) 硬件層次結構
GPU 的體系結構具有雙重層次特征:存儲層次(Global Memory → L1/L2 Cache → Shared Memory → Register)與計算層次(Grid → Block → Warp → Thread),另外現代 GPU 普遍集成矩陣計算單元(如 NVIDIA TensorCore)。所以 GPU 的優化也需要按層次展開:
① Warp 級別:矩陣計算單元以 warp 為執行粒度,數據從 Shared Memory 加載至寄存器供計算單元使用。此層級的優化目標包括:
- 設計合理的 warp 級矩陣分塊策略,提升計算密度,需注意寄存器的合理使用
- 消除 Shared Memory 的 bank 沖突(例如通過數據交錯存儲)
- 增加指令數量,滿足計算單元吞吐;
② Block 級別:數據流動路徑為 Global Memory → Shared Memory。優化重點包括:
- 根據 Shared Memory 容量和 warp 資源占用,劃分 block 內 warp 數量
- 平衡計算與訪存任務,最大化 warp 算力利用率
- 注意保證 GPU 合理的 warp 并行度,避免并行度不足導致性能退化
③ Grid 級別:通過數據重排提升 Global Memory 訪問效率,同時優化 block 調度順序以提高 L2 Cache 命中率,最終實現全局性能最優。
(2) 提高并行度
GPU 的高吞吐依賴大規模 warp 并發執行。當單個 warp 因資源占用過高(寄存器/ SM 資源)導致 SM 上并發 warp 數下降時,將產生 ALU 閑置。如圖 6 所示,warp 數量從 1 增至 3 可有效掩蓋訪存延遲,并盡可能保持算力單元的繁忙。但 2 個 warp 時 ALU 仍存在空閑周期。另外,例如指令依賴也會導致可調度 warp 數量下降造成資源閑置,所以在優化中需要很好關注 profiler 工具提供的相關參數,避免出現這種情況。除了以上優化層面造成資源閑置外,還有一些算法或者計算數據層面造成的 warp 并行度低的情況,例如矩陣計算中小 M、N 大 K 的情況,如果不仔細處理就會導致并行度低。這些 case 也都有一些成熟的方案來解決,例如 split K 算法,并行的 reduce,都是為了處理這些情況。

圖6. 提高 GPU Occupancy
除了以上的方法外,這里介紹兩種,硬件機制層面的方案,其一是 Apple/Arm GPU上采用 subgroup matrix 技術,它提供的軟件矩陣乘指令(類比 TensorCore),不增加硬件計算單元,但是可以降低寄存器占用,從而提升 warp 并行度。其二是 Apple 針對 M3/A17 芯片的 Dynamic Caching 技術,它運行時動態分配寄存器 / Cache 資源(圖 7),減少靜態分配造成的資源碎片,提升 SM 并發 warp 數量。這兩種方案都以較小的成本,進一步壓榨硬件性能,相比于一些廠商不考慮軟件的算力利用率,大幅度堆計算單元要高明的多。

圖7. 寄存器動態分配示意圖
(3) 帶寬優化
帶寬優化需貫穿存儲層級各環節(Global Memory → Shared Memory → Register),核心方法包括:
① Shared memory 帶寬優化
- Bank沖突規避:通過數據重排、交錯訪問消除沖突
- 直存指令優化:使用 ld.global 指令直接加載數據至 Shared Memory,規避寄存器中轉
② 數據通路加速
- Shuffle 指令:利用寄存器間數據交換加速 Reduce 操作
- 雙緩沖預取:實現 GEMM 計算與數據加載的流水線重疊
③ 合并訪問優化
- 合并訪問:確保 warp 內線程訪問連續對齊內存塊
- Thread Block Swizzle:通過 Z 型映射調整 block調度順序(如圖 8 所示),讓數據擁有更好的局部性,提升 L2 Cache 命中率
- 硬件 Cache 策略:在高通平臺優先使用 Texture,因為 Adreno GPU 只有 Texture read 可以使用 L1 cache,所以使用 Texture 可以提高數據訪問效率。除此之外,Texture2D 數據結構的 cache 是塊狀的,因此在數據訪問模式設計中,與 buffer 就有所不同,需要按照塊狀設計數據的局部性。

圖8. Thread Block Swizzle 示意圖
(4) 其他優化手段
要對 GPU 進行極限優化,硬件逆向和指令逆向是不可或缺的手段。通過逆向可以獲取更多硬件信息,可以幫助我們在指令重排,數據排布等方面提供更多的參考和指導。盡管主流 GPU 廠商(Apple/NVIDIA/AMD/Intel/Qualcomm/Arm/Mali/Maleoon 等)均提供基礎開發文檔,但涉及性能敏感的核心機制如指令流水線設計、緩存替換策略、寄存器動態分配算法等關鍵細節仍處于保密狀態。通過系統化的逆向工程,我們可以深度掌握指令延遲特性,微指令調度策略,指令吞吐等硬件信息。另外通過一些重要專利,也可以對硬件實現的細節有一定的了解,幫助我們制定更優的優化策略。
3. FlashAttention-2
當前基于 Transformer 架構的 LLM 面臨顯著挑戰:隨著輸入序列長度的增加,其核心組件 self-attention 模塊的時間與空間復雜度呈二次方增長。為突破這一瓶頸,斯坦福大學與紐約州立大學布法羅分校 Tri Dao 團隊提出的 FlashAttention 算法,通過創新的內存高效計算策略,在保持計算精度的前提下顯著提升了注意力機制的運算速度并降低了內存占用。
FlashAttention 的底層實現基于 NVIDIA 研究人員 Maxim Milakov 和 Natalia Gimelshein 于 2018 年提出的 Online Softmax 分塊計算技術。由于 FlashAttention-1 在工程實踐中存在循環順序優化不足的性能缺陷,FlashAttention-2 通過以下三大改進實現了突破性優化:
(1) 矩陣計算單元優化
通過改進 rescale 操作減少非矩陣乘法運算(non-matmul FLOPs)。鑒于現代 GPU 中矩陣計算單元的吞吐效率顯著高于通用浮點計算單元,這種優化策略能有效提升整體計算效率。
(2) block 級別優化
將 block 劃分維度從原有的 batch_size 和 num_heads 擴展至包含 seq_len 方向的三維劃分。具體實現通過將 Q 矩陣置于外循環,使并行計算單元能在序列長度維度展開,顯著提升小批量場景下的 GPU 資源利用率。
(3) warp 級優化
如圖 9 所示,通過重構 Q/K/V 矩陣的循環訪問順序:將 Q 矩陣劃分到 4 個 warp 同步訪問 K/V 矩陣,避免原方案中反復讀寫 shared memory 及 warp 同步帶來的性能損耗。這種改進使中間結果無需暫存于共享內存,同時降低線程束間的通信開銷。

圖9. FlashAttention-2 warp 劃分
在 XNet-DNN 框架中實現的 FlashAttention-2 算法已成功應用于長上下文業務場景,實測顯示其能有效提升計算速度達 3 到 8 倍。需要說明的是,雖然后續發布的 FlashAttention-3 針對 Hopper 架構進行了特定優化,但因其硬件適配范圍受限,當前 XNet-LLM(GPU) 引擎暫未集成該版本, 但是同樣的,我們也針對 Apple GPU 等其他 GPU 實現了定制優化的 FlashAttention 算法。
四、性能實測:XNet-DNN 多平臺性能圖譜
本次測試主流 LLM 推理引擎為llama.cpp(SHD-1: 916c83bf), MLX(version: 0.24.2),MLX-LM(version:0.22.4), MLX-Swift(version:0.21.2), mlc-llm(SHD-1: 9d798acc), TRT-LLM(version 0.16.0)。
測試平臺包括 Apple 的 M1 Pro 和 iPhone 15Pro 兩款設備。NVIDIA 的 RTX 3060 顯卡。Qualcomm 的 8Gen3 芯片以及 Intel ultra7 155H 的集成顯卡。我們測試模型如無特殊說明,均為 4bit 量化版本。
1. Apple GPU LLM 性能對比
本小節主要展示 XNet-DNN 在 Apple GPU 平臺的性能,測試設備包含 M1 Pro 和 iPhone 15 Pro。M1 Pro 上,prefill 性能我們領先最優 LLM 推理引擎 14% - 22% 不等;decode 性能領先最優 LLM 推理引擎 6% - 14% 不等。iPhone 15 Pro 上,prefill 性能我們領先最優 LLM 推理引擎 7% - 35%;decode 性能領先最優 LLM 推理引擎 5% - 12%。
(1) M1 Pro GPU 性能對比
圖 10 和 圖 11 分別展示了 XNet-DNN 在 M1 Pro GPU 上與主流 LLM 推理引擎的 prefill 及 decode 性能對比。

圖10. M1 Pro LLM 推理 prefill 性能測試

圖11. M1 Pro LLM 推理 decode 性能測試
除了以上端上經典尺寸的模型測試,鑒于 M1 Pro 內存空間大的特性,我們也在 M1 Pro 上部署了最近很火的 QwQ-32B Q40 量化版本(4bit 量化版本需要 17G 左右的內存),獲得了很好的體驗。圖 12 和 圖 13 分別展示了與主流 LLM 推理引擎的性能對比。Prefill 計算相對于主流 LLM 推理引擎,我們擁有巨大優勢。

圖12. M1 Pro LLM QwQ-32B 推理 prefill 性能測試

圖13. M1 Pro LLM QwQ-32B 推理 decode 性能測試
(2) iPhone 15 Pro GPU 性能對比
圖 14 和圖 15 分別展示了 XNet-DNN 在 iPhone 15 Pro GPU 上與 LLM 推理引擎的 prefill 和 decode 性能對比。

圖14. iPhone 15Pro LLM 推理 prefill 性能測試

圖15. iPhone 15Pro LLM 推理 decode 性能測試
2. NVIDIA GPU LLM 性能對比
本小節展示 XNet-DNN 在 NVIDIA GPU 上的性能。測試設備是 RTX 3060。XNet-DNN Prefill 性能領先最優 LLM 推理引擎 32% - 55% 不等;Decode 性能領先最優 LLM 推理引擎 6% - 21% 不等。
圖 16 和 圖 17 分別展示了 XNet-DNN 在 RTX 3060 上與 主流 LLM 推理引擎的 prefill 和 decode 性能對比。

圖16. RTX 3060 LLM 推理 prefill 性能測試

圖17. RTX 3060 LLM 推理 decode 性能測試
3. Qualcomm/Intel GPU LLM 性能對比
本節對高通及英特爾集成顯卡平臺的大語言模型推理性能與行業 主流 LLM 推理引擎進行對比分析。需特別說明的是,除前述顯卡系列外,XNet-DNN 還完整支持 Mali 架構 GPU 及華為 Maleoon GPU 等主流端側 GPU。
當前行業對大模型推理的優化研究主要集中于 NVIDIA CUDA 架構及 Apple Metal 生態的高性能計算設備,此類平臺憑借其突出的算力水平、較大的顯存和顯存帶寬以及龐大的用戶群體,成為算法落地的重要目標平臺。
受此技術路徑影響,現有 主流 LLM 推理引擎方案對 Intel/Qualcomm/Mali/Maleoon 等 GPU 的支持普遍存在顯著局限性,部分實現方案為追求運算速度過度壓縮計算精度,導致輸出結果不可靠甚至存在系統性誤差。
基于上述技術背景,本節選取具有代表性的移動端平臺(高通驍龍 8Gen3 移動平臺/Android 系統)及桌面端平臺(英特爾 Ultra7 155H 處理器/集成顯卡)進行 decode 性能數據展示。從測試數據看,XNet-DNN 在相關平臺依然有絕對性能優勢。歡迎有興趣或者有業務落地需求的朋友共同探討,共同推進端側 AI 應用的技術探索與落地實踐。圖 18 和圖 19 展示了 XNet-DNN 在 8Gen3 及 Ultra7 155H 與 主流 LLM 推理引擎的性能對比。

圖18. 小米 14 (8Gen3) LLM 推理性能測試

圖19. Intel ultra7 155H 集顯 LLM 推理性能測試
針對英特爾 Ultra7 155H 處理器的 Arc 架構集成顯卡單元,XNet-DNN 推理引擎展現出 104%-265% 的性能優勢。需說明, 主流 LLM 推理引擎 llama.cpp 在 Intel 平臺采用 SYCL 異構編程框架實現推理加速,其技術實現由 Intel 工程師團隊完成,屬于該平臺專業級解決方案。故本次測試僅選取 llama.cpp 作為核心對標方案進行評估。
五、總結展望
經過不斷的開發迭代,以及在多個業務中的錘煉,目前 XNet-DNN 在推理性能、跨平臺一致性、部署穩定性、包體積等方面優勢已經非常明顯。在未來的開發中我們將從以下幾個方面進一步優化完善 XNet-DNN,以期獲得更優的性能,持續保持領先,同時更好的更多的支持業務落地,持續賦能相關業務。
- 持續跟進大模型最新技術,保證相關技術能快速落地賦能業務
- 持續支持更多 GPU 平臺,支持國產化
- 進一步探索性能優化方案,壓榨硬件性能
- 完善業務場景中的各種 feature 支持
除了以上方向之外,當前大模型的部署包括軟硬件生態以及模型等都在蓬勃發展中,我們也將持續跟蹤最新發展情況,保持 XNet-DNN 在各個方面的持續領先。