任務調試太麻煩?教你一招搞定
通過傳統的離線數據分析,企業僅能針對歷史數據進行事后分析。 而隨著數據量的爆發式增 長,以及市場環境和業務需求的快速變化,企業對數據時效性的 要求在不斷提高。 如在互聯網行業中,客戶端需要滿足用 戶對個性化產 品和服務的需求; 在金融行業中, 企業需要更快速地進行風險控制和趨勢分析; 在新零售行業中,企業需要更快速地獲取 銷售數據,做出業務 決策等。 因此 ,企業需要實時數據計算的能力來滿足實時數據分析的需求。
1 實時開發中的痛點
在實時任務的開發過程中,任務調試是整個開發流程中比較耗時同時操作比較繁瑣的環節。在調試階段,用戶普遍會面臨以下幾個痛點。
1.1 任務頻繁上下線
在調試過程中,需要驗證任務代碼邏輯是否正確,任務配置參數是否合理,就需要重復任務上線、運行、下線調整重啟這一過程。
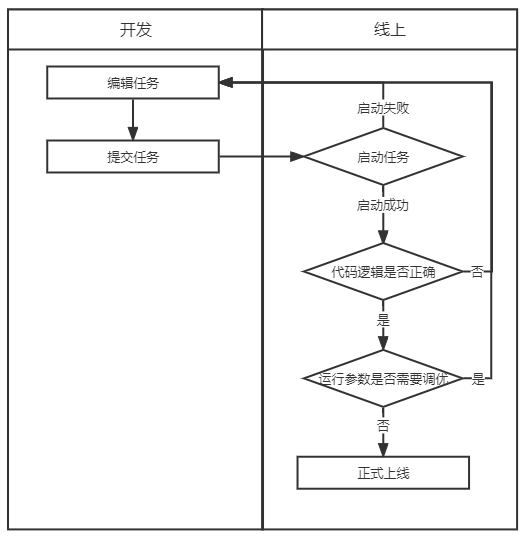
(實時任務開發流程)
1.2 需要創建測試結果表
由于實時任務在調試過程中需要不斷提交到線上運行,調試過程中會產生臟數據,因此一般需要創建一張測試的結果表用于調試,在調試完成后再通過修改代碼將結果表替換為正式的結果表。這個替換表的過程涉及到代碼變更,可能會引入新的問題,同時維護測試表需要額外的成本。
1.3 無法使用特定的測試數據進行調試
將任務實際上線運行時,使用的源端數據是任務中指定的源端,大部分實時任務中使用消息隊列中的流式數據作為源端,若想在調試階段使用特定的測試數據進行調試,還需要用戶在源端中自行插入指定數據,或使用測試源端表,在調試結束正式上線前替換為正式的源端表。操作復雜,同時也有可能在替換源端或插入數據時引入新的問題。
2 針對痛點的解決方案
針對上述痛點 , 有數實時計算平臺提供了 相應的解決方案,即 實時開發調試的功能。調試功能分為兩個步驟,第一步是獲取調試數據,第二步是使用調試數據進行任務本地調試。
2.1 獲取調試數據
在獲取調試數據步驟中,目前提供了在線采樣、上傳本地數據、在線維護測試數據的功能。用戶可直接使用在線采樣功能,針對任務中使用的源表進行采樣,在后續的調試過程中即可直接使用采樣的數據。
針對用戶想使用特定的測試數據進行任務調試的需求,平臺支持用戶在在線采樣后對采樣結果進行編輯和保存,保存采樣數據后,這份數據將作為這個任務可長期重復使用的調試數據記錄在任務中。此外用戶還可以下載源端數據結構文件,自行填寫源端數據后上傳至任務中,作為此任務的測試樣本進行保存。
2.2 任務本地調試
在獲取到調試的樣本數據后,用戶無需將任務提交上線即可開始調試,同時任務的調試結果將不會寫入結果表中,僅會在開發IDE中進行展示,方便用戶確認代碼邏輯是否正確。
通過任務本地調試的功能,免除了用戶需要頻繁上線任務的過程,也省去了創建測試結果表和替換結果表代碼的過程,為實時任務開發提高了效率,也保障了線上數據的安全。
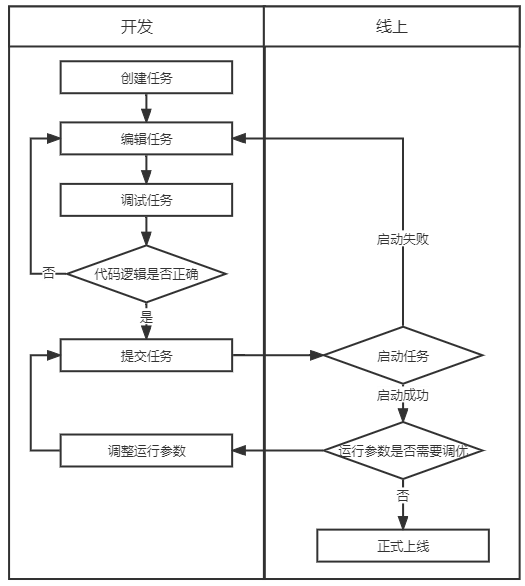
(使用調試功能后實時任務開發流程)
通過調試任務功能,用戶在開發環節中即可驗證代碼邏輯。后續有數實時計算平臺將在運行參數調優方面持續做出優化,徹底解決用戶調試實時任務難的問題。
3 應用案例
3.1 案例場景
業務方需要使用商品售賣結果的實時數據進行報表展示,數據加工團隊需要使用 Kafka 消息隊列中的商品實時銷售情況關聯包含商品詳情的 MySQL 維表,將結果寫入 MySQL 結果表中供業務方查詢。
3.2 開發前準備
使用的 Kafka topic:testgoods, 數據預覽:
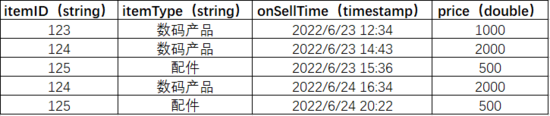
使用的 MySQL 維表:goods_info,包含商品ID和商品名稱, 數據預覽:
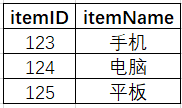
表結構:
3.3 創建任務
(1)創建一個 SQL 任務
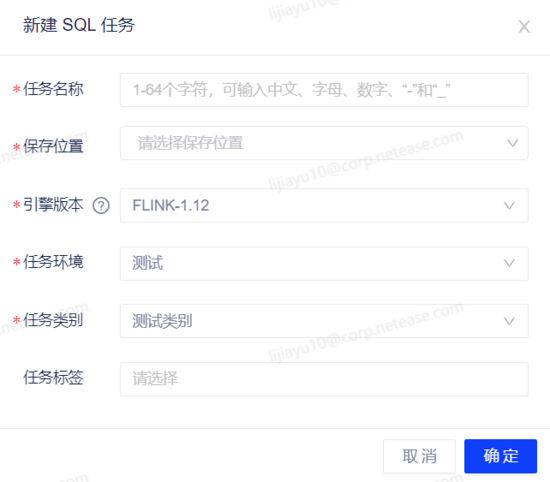
(2)編寫業務邏輯
set 'testgoods.connections.group.id' = 'mysql_join_example';
--設置Kafka消費者組id,需要更改為自己命名的groupid
set 'testgoods.scan.startup.mode' = 'earliest-offset';
--設置讀取消息隊列的位置
create view v1 as
select
PROCTIME() as proctime,
itemID,
itemType,
onSellTime,
price
from
poc.testgoods;
insert into
`ljy_test_mysql`.`sloth_test`.`goods_join_mysql_sink`
select
v1.itemID,
v1.itemType,
v1.onSellTime,
v1.price,
goods_info.itemName as itemName
from
v1
left join `ljy_test_mysql`.`sloth_test`.`goods_info` FOR SYSTEM_TIME AS of v1.proctime on v1.itemID = goods_info.itemID;
3.4 調試任務
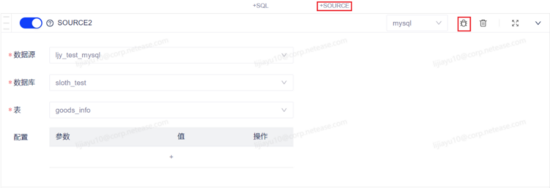
(1)進行源表和維表采樣
點擊頁面中的添加 source 按鈕,在 source 塊中選擇源表和維表,點擊 source 塊中的調試按鈕進行采樣。
源表 source 塊:此處提前將 Kafka的topic:testgoods登記為一張流表,因此有數據庫、表的選擇。
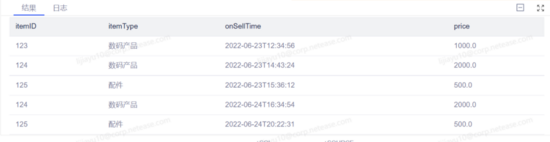
源表采樣結果:
維表 source 塊:
維表采樣結果:
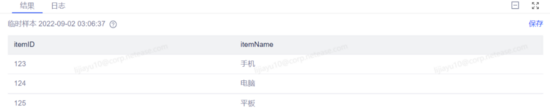
在獲取到采樣結果后,雙擊結果欄中的數值可修改樣本數據,點擊保存按鈕可將樣本保存為正式樣本用于后續多次調試。
(2)調試任務
點擊 SQL 塊操作欄中的調試按鈕,系統將自動解析代碼中使用的源表和維表并展示在調試側邊欄中,用戶選擇每張源表和維表需要使用的樣本數據后,即可對任務代碼開始調試,調試結果展示在代碼框下方。
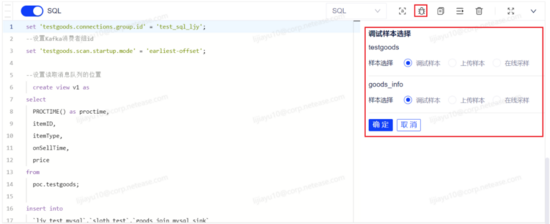
調試結果符合用戶預期,代碼邏輯驗證通過,任務可提交上線。
4 有數實時計算平臺介紹
目前 Apache Flink 已成為大數據實時計算的事實標準,具備高性能、低延遲等特點,但作為一款開源產品,社區版 Apache Flink 在產品化方面并未投入較大精力,因此企業用戶在使用社區版 Flink 時,開發門檻高、運維成本高,針對這些問題,我們基于 Apache Flink 構建了一站式、企業級,高性能實時大數據處理系統。
在開發方面,為用戶提供了一站式的開發控制臺進行任務開發,提供元數據中心進行元數據管理,內置豐富 connector 達到開箱即用的效果,保證了與用戶使用的大數據組件無縫對接,提供UDF管理功能、在線調試功能、版本管理功能,大大降低了實時計算任務的開發門檻。
在運維方面,提供全鏈路監控告警、任務是在檢索和基于元數據中心的任務血緣,幫助用戶快速發現問題定位問題,提供企業級權限管理保障線上數據安全。
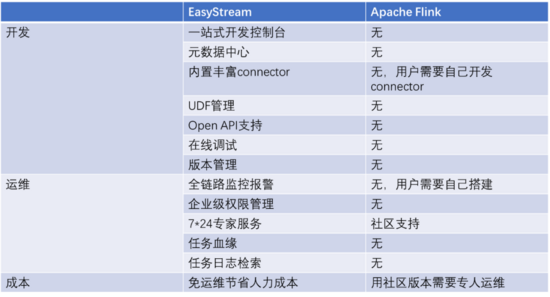
(有數實時計算平臺與 Apache Flink 的功能對比)
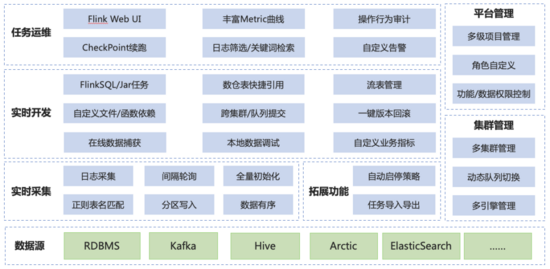
(有數實時計算 平 臺 架構)
作者簡介
佳鈺,網易數帆有數實時計算平臺產品經理 。