消息中間件該如何實現(xiàn)高可用架構(gòu)
1. 背景引入
這篇文章,我們來聊一下消息中間件高可用架構(gòu)的一些原理。
對于一個合格的高級 Java 工程師而言,你肯定會碰到在系統(tǒng)里用到 MQ(消息隊列)的場景。那么這個時候你需要基于你的業(yè)務(wù)場景和需求,考慮在使用 MQ 的時候可能遇到的一些技術(shù)問題。
接著,你必須得針對這些技術(shù)問題設(shè)計一套完整的技術(shù)方案。
你需要從消息的訂閱模式、消息的生產(chǎn)到消費全鏈路不丟數(shù)據(jù)、消息中間件本身如何保證高可用等各個角度切入,來考慮好你的系統(tǒng)和 MQ 對接之后的完整技術(shù)方案。
所以,本文就來聊聊消息中間件高可用的架構(gòu)原理。
2. 先來思考一下消息中間件的可用性問題
咱們先拋開各種具體的技術(shù),思考一下什么是 MQ 的可用性問題?
大家看看下面的圖,其實道理很簡單。假設(shè)你的 MQ 就部署在一臺機器上,那么正常情況下,生產(chǎn)者都會發(fā)送消息到 MQ 去,然后讓消費者獲取到。

但是萬一天有不測風(fēng)云,MQ 部署的那臺機器因為一些莫名的原因 MQ 自己本身的進程掛掉了或者是那臺機器直接就宕機了,那么這種時候該怎么辦呢?
很尷尬,是不是?結(jié)果是很明顯的。生產(chǎn)者沒法發(fā)送數(shù)據(jù)出去,然后消費者也沒法獲取到數(shù)據(jù)了。
然后整個系統(tǒng)不就完蛋了?因為系統(tǒng)的核心流程根本無法跑通了,對不對?
MQ 宕機就直接導(dǎo)致你的系統(tǒng)本身也故障了,然后可能會導(dǎo)致你的公司對外的 App、網(wǎng)站等產(chǎn)品就無法運作了,用戶無法使用你們公司的服務(wù)了。
如果你們公司是電商平臺、外賣平臺、社交平臺。那么來這么一出,不是會導(dǎo)致公司損失慘重?
如果你的系統(tǒng)持續(xù)幾個小時無法被人使用,本來你公司電商平臺一天營收可以達到 1 億,結(jié)果現(xiàn)在導(dǎo)致幾個小時內(nèi)無法下單購買商品,最后當(dāng)天營收就 5000 萬,那么你的公司是不是直接活生生損失了 5000 萬?
這個真的不是開玩笑的,如果大家留意互聯(lián)網(wǎng)行業(yè)的新聞的話和小道消息的話,就應(yīng)該知道近幾年一些大型互聯(lián)網(wǎng)公司都出現(xiàn)過類似的情況,損失慘重。咱們做碼農(nóng)的就得被祭天了,是不是?
3. 集群化部署 + 數(shù)據(jù)多副本冗余
好,問題來了!現(xiàn)在你感覺一個 MQ 中間件應(yīng)該如何實現(xiàn)高可用呢?
這里的方式有很多種,比如說數(shù)據(jù)多副本冗余、集群鏡像同步機制。我們就拋開具體的技術(shù)來從本質(zhì)層面思考一下 MQ 集群實現(xiàn)高可用的幾種方式。
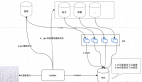
先來看下面的一張圖,假設(shè)我們寫到 MQ 的數(shù)據(jù)都被多副本冗余了,也就是你寫的每一條消息都被復(fù)制到了其他的機器上去了。
那么此時任何一臺機器宕機,似乎都不會影響我們跟 MQ 繼續(xù)通信,而且寫出去的數(shù)據(jù)似乎也都還在。

上面的圖里,MQ 采用集群模式部署到了兩臺機器上去,然后生產(chǎn)者給其中一臺機器寫入一條消息,該機器自動同步復(fù)制給另外一臺機器。
此時數(shù)據(jù)在兩臺機器上,就有兩個副本了。那么如果第一臺機器宕機了,會影響我們嗎?
答案是:不會。
因為數(shù)據(jù)本身是多副本冗余的,此時消費者完全可以從第二臺機器消費到這條消息,并且生產(chǎn)者還可以繼續(xù)給第二臺機器寫入消息,數(shù)據(jù)沒丟失。
而且,系統(tǒng)根本不用中斷流程,還可以繼續(xù)運行,我們看下面的圖。

這種感覺是不是很棒?實際上這種 MQ 集群化部署架構(gòu)以及數(shù)據(jù)多副本冗余機制,是非常常見的一種高可用架構(gòu)。
Kafka 這個極為優(yōu)秀的消息中間件,就是采用的這種架構(gòu)保證高可用、數(shù)據(jù)容錯性。
4. 多副本同步復(fù)制強制要求
但是這里你要思考另外幾個問題。
第一個問題,你在寫數(shù)據(jù)到其中一臺機器的時候,是不是有這樣的要求:必須得讓那臺機器復(fù)制數(shù)據(jù)到另外一臺機器了,保證集群里一定有這條數(shù)據(jù)雙副本了,才可以認為本次寫成功了?
沒錯,假如你要是不能保證這一點,比如你就寫數(shù)據(jù)給了其中一臺機器,然后它還沒來得及復(fù)制給另外一臺機器呢,直接第一臺機器就宕機了。
此時,雖然你可以繼續(xù)基于第二臺機器發(fā)送消息和消費消息,但是你剛才發(fā)送的一條消息就丟失了。
大家看下面的圖來理解一下這個場景。

所以對于采用這種機制的時候,你必須得讓生產(chǎn)者通過一些參數(shù)的設(shè)置,保證寫一條消息到某臺機器,必須同步這條消息到另外一臺機器成功。等到集群里有雙副本了,然后才可以認為這條消息寫成功了。
只要剛寫一臺機器他就宕機,還沒來得及復(fù)制到另外一臺機器的話,本次寫應(yīng)該報錯失敗。然后,你應(yīng)該重試再次寫入數(shù)據(jù)到 MQ 集群里去。
大家看看下面的圖。只要你一次寫成功了,就保證肯定已經(jīng)同步數(shù)據(jù)為雙副本了。此時,哪怕一臺機器宕機,數(shù)據(jù)不會丟失,生產(chǎn)和消費都可以有條不紊地繼續(xù)進行。

5. 多機器承載多副本強制要求
第二個問題,假如說現(xiàn)在你的集群中本來有兩臺機器,現(xiàn)在其中的一臺宕機了,只有一臺機器了,你還能允許你的生產(chǎn)者對唯一的那臺機器繼續(xù)寫入數(shù)據(jù)嗎?
答案是:否。
因為,如果集群里只有一臺機器可以承載寫入,那么萬一剩余的一臺機器又宕機了呢?是不是還是會導(dǎo)致數(shù)據(jù)丟失,集群完蛋?
所以說,你的生產(chǎn)者同理應(yīng)該基于參數(shù)設(shè)置一下,集群里必須有超過兩臺機器可以接收你的數(shù)據(jù)副本復(fù)制。
否則如果只有一臺機器可以接受你的數(shù)據(jù)副本復(fù)制的話,那么還是算了。
大家看看下面的圖,感受一下那個場景。

假設(shè)集群里有 3 臺機器,那么其中一臺宕機了,你后續(xù)再寫入另外一臺的時候,判斷一下集群里還有剩余兩臺機器,足以保證數(shù)據(jù)雙副本的高可用性和容錯性,所以可以繼續(xù)正常的寫入數(shù)據(jù)到 MQ 集群里去。
實際上,上面說的那一整套的機制,在 Kafka 里都可以采用。它有對應(yīng)的一些參數(shù)可以配置數(shù)據(jù)有幾個副本,包括你每次寫入必須復(fù)制到幾臺機器才可以算成功,否則就要重新發(fā)送。還可以通過參數(shù)設(shè)置,集群剩余機器必須可以承載幾個副本才能繼續(xù)寫入數(shù)據(jù)。
通過這一整套方案的設(shè)計和基于具體技術(shù)的落地,才可以保證在集群化部署的情況下,集群必須有幾臺機器承載多副本,同時數(shù)據(jù)寫入之后必須是保證多副本冗余的。
此時,任何機器宕機,數(shù)據(jù)都不會丟失,還可以正常讓系統(tǒng)繼續(xù)運行。
6. 架構(gòu)原理與技術(shù)無關(guān)性
其實本文對消息中間件的集群高可用架構(gòu)的探討,是完全脫離于某個具體技術(shù)的,非常樸素的從本質(zhì)的原理層面來討論這個話題。
具體的 RabbitMQ、Kafka、RocketMQ 等各種不同的消息中間件,對這種高可用架構(gòu)的實現(xiàn),都有一定的相似想通性,但是也都有各自不同的技術(shù)實現(xiàn),以及相對應(yīng)的區(qū)別。